[PYTHON] [Super introduction à l'apprentissage automatique] Découvrez les didacticiels Pytorch
Il s'agit d'une compilation de ce que l'auteur a écrit au lieu d'un mémo, dont l'auteur n'a pas encore saisi le tableau d'ensemble. Je vais résumer le contenu du tutoriel Pytorch + le contenu examiné en α. (J'ai écrit ..., mais cela n'est guère conforme au tutoriel.)
Dans le but de pouvoir l'utiliser librement, après avoir décidé de ce que vous pouvez comprendre, J'étudierai avec une politique de mise en œuvre régulière.
Cette fois, c'est le chapitre 2. Précédent-> https://qiita.com/akaiteto/items/9ac0a84377600ed337a6
introduction
La dernière fois, je viens de regarder le traitement de chaque couche du réseau neutre, donc Cette fois, je vais me concentrer sur l'optimisation.
En guise de prémisse, j'ai pensé qu'il était un peu déroutant de simplement déplacer la source de l'échantillon MNIST, donc Aussi simple que possible, construisez un exemple à partir de la position et déplacez-le, puis À partir de là, j'étudierai dans le but de mettre en œuvre diverses méthodes par moi-même.
Ensuite, j'essaierai d'incorporer ma propre méthode d'optimisation dans le réseau neutre. De plus, ce qui est mis en œuvre n'est que la méthode de descente la plus raide. Cela peut être utile lors de la mise en œuvre de vos propres techniques d'optimisation dans un réseau neutre.
Apprendre le réseau
Dernier malentendu
La dernière fois, j'ai présenté les résultats de calcul suivants dans l'explication de la fonction de perte.
C'est très simple à faire. Tout d'abord, entrez les données d'entrée applicables dans le réseau défini, puis J'ai obtenu la valeur de sortie (données contenant les informations sur les fonctionnalités).
Après cela, faites de même pour diverses autres données d'entrée, L '«erreur» avec l'emplacement de sortie calculé en premier a été calculée et elle a été sortie comme «évaluation».
#Résultat d'exécution
*****Phase d'apprentissage*****
Données d'entrée pour l'apprentissage du réseau
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
*****Phase d'évaluation*****
Entrez les mêmes données
input:
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Tenseur d'évaluation(0., grad_fn=<MseLossBackward>)
Entrez des données légèrement différentes
input:
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Tenseur d'évaluation(0.4581, grad_fn=<MseLossBackward>)
Entrez des données complètement différentes
input:
tensor([[[[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.],
[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.]]]])
Tenseur d'évaluation(58437.6680, grad_fn=<MseLossBackward>)
"Je suis sûr que cette valeur d'évaluation sera jugée par le seuil et si elle est la même ou non." J'ai pensé à ce moment-là. Est-elle considérée comme une donnée différente si elle est séparée par 0,5 ou plus? C'est une question de reconnaissance.
La valeur de sortie est, pour ainsi dire, une valeur numérique extraite des caractéristiques de chaque donnée. CNN est donc un moyen de voir à quel point les fonctionnalités sont proches! Quand.
... mais cela ne suffit pas. Tel qu'il est maintenant, il est simplement filtré. Je n'ai pas bien compris l'apprentissage.
Corriger les données de réponse A
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Données d'entrée B
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Tenseur d'évaluation(0.4581, grad_fn=<MseLossBackward>)
L'essence de la phase d'apprentissage est
"Les données d'entrée A et B, qui sont légèrement différentes mais pointent en fait vers la même chose, Reconnaissons-le comme la même chose! !! "à propos de ça.
Tenseur d'évaluation(0.4581, grad_fn=<MseLossBackward>)
Ce numéro est affiché comme une erreur. Cette valeur numérique indique à quel point les données d'entrée A et B ne sont pas alignées.
Il y a une erreur dans la valeur numérique, mais en réalité A et B sont les mêmes, donc L'erreur devrait idéalement être "0".
Autrement dit, quelle est l'essence de l'apprentissage? Erreur importante entre les données d'entrée A et B, sortie comme "0.4581" C'est l'essence même de "l'ajout d'une petite main" pour qu'elle soit sortie autant que possible "0".
En ajustant le "poids" de chaque couche du réseau pour que l'erreur soit sortie à 0, L'essence est "d'apprendre" qu'il n'y a pas d'erreur - A et B sont les mêmes ".
Essayez d'optimiser
Optimisation (arrêtez de penser)
Quel type de formule est utilisé pour ajuster le poids? ... Je vais le mettre de côté et d'abord arrêter de penser et le laisser apprendre avec Pytorch.
Je ne sais pas pourquoi et je n'aime pas utiliser diverses couches cool dans l'exemple de MNIST. Testons avec un exemple plus simple pour autant que nous comprenions.
Motif A
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Motif B
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Apprenons et testons les deux modèles ci-dessus.
L'ensemble
test.py
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch import optim
import matplotlib.pyplot as plt
import numpy as np
class DataType():
TypeA = "TypeA"
TypeA_idx = 0
TypeB = "TypeB"
TypeB_idx = 1
TypeOther_idx = 1
def outputData_TypeA(i):
npData = np.array([[0,i,0,i],
[0,i,0,i],
[0,i,0,i],
[0,i,0,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
def outputData_TypeB(i):
npData = np.array([[i,i,i,i],
[0,i,0,i],
[0,i,0,i],
[i,i,i,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
#Préparation des données pendant le test
input_data = []
strData = "data"
strLabel = "type"
for i in range(20):
input_data.append({strData:outputData_TypeA(i),strLabel:DataType.TypeA})
for i in range(20):
input_data.append({strData:outputData_TypeB(i),strLabel:DataType.TypeB})
print("Préparez un total de 200 données de test des modèles suivants")
print("Motif A")
print(outputData_TypeA(1))
print("Motif B")
print(outputData_TypeB(1))
print("Assurez-vous que ces deux modèles peuvent être distingués.")
print("\n\n")
#Définition du réseau
Test_Conv = Test_Conv()
#contribution
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
print("***Essayez avant d'apprendre***")
##Essayez d'insérer les données appropriées dans le modèle entraîné.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Taux de réponse correct: {} %".format(correct / len(predicted) * 100.0))
print("***Phase d'apprentissage***")
epochs = 2
for i in range(epochs):
for dicData in input_data:
#Préparation des données d'entraînement
train_data = dicData[strData]
#Préparation des bonnes réponses
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Processus d'optimisation
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
# print(train_data.shape)
# print(outputs.shape)
# print(answer_data.shape)
#
# exit()
loss.backward()
optimizer.step()
print("\t", i, " :Erreur= ",loss.item())
print("\n\n")
print("***Phase de test***")
##Essayez de mettre des données appropriées avec le modèle entraîné.
input_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
outputs = Test_Conv(input_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Taux de réponse correct: {} %".format(correct / len(predicted) * 100.0))
exit()
Préparez un total de 200 données de test des modèles suivants
Motif A
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Motif B
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Assurez-vous que ces deux modèles peuvent être distingués.
***Essayez avant d'apprendre***
Taux de réponse correct: 0.0 %
***Phase d'apprentissage***
0 :Erreur= 1.3862943649291992
0 :Erreur= 1.893149733543396
0 :Erreur= 2.4831488132476807
0 :Erreur= 3.0793371200561523
0 :Erreur= 3.550563335418701
0 :Erreur= 3.7199602127075195
0 :Erreur= 3.3844733238220215
0 :Erreur= 2.374782085418701
0 :Erreur= 0.8799697160720825
0 :Erreur= 0.09877146035432816
0 :Erreur= 0.006193255074322224
0 :Erreur= 0.00034528967808000743
0 :Erreur= 1.8000440832111053e-05
0 :Erreur= 8.344646857949556e-07
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
0 :Erreur= 0.0
.
.
.
***Phase de test***
Taux de réponse correct: 100.0 %
C'est une source simple, mais regardons-la une par une.
Définition du réseau
test.py
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
Dans MNIST, toutes les données ont été entrées en même temps comme données d'entrée. Cependant, cela semblait difficile à comprendre intuitivement car l'échelle était trop grande. Il est configuré pour insérer les images monochromes une par une.
Puisque la couche de convolution $ out_channels = 4 $, 4 entités sont extraites avec un filtre, Dans $ x.view $, les dimensions sont arrangées pour comparaison avec l'étiquette correcte.
Essayez de postuler avant d'apprendre
test.py
print("***Essayez avant d'apprendre***")
##Essayez de mettre des données appropriées avec le modèle entraîné.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Taux de réponse correct: {} %".format(correct / len(predicted) * 100.0))
Je vais l'essayer avant d'apprendre. Le code est différent, mais c'est une reproduction du "dernier malentendu". Effectivement, le taux de réponse correct est de 0%.
Apprendre le réseau
test.py
#Préparation des données d'entraînement
train_data = dicData[strData]
#Préparation des bonnes réponses
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Processus d'optimisation
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
loss.backward()
optimizer.step()
print("\t", i, " :Erreur= ",loss.item())
Dans la section "Dernier malentendu", j'ai écrit comme suit
Erreur importante entre les données d'entrée A et B, "0.Quelle est la sortie en tant que "4581"
C'est l'essence même de "l'ajout d'une petite main" pour qu'elle soit sortie autant que possible "0".
L'apprentissage en réseau fait cela. Au début du processus, mettez d'abord une seule donnée du motif A ou du motif B dans $ train_data $.
test.py
outputs = Test_Conv(train_data)
A l'intérieur du réseau, 4 caractéristiques sont calculées en appliquant 4 filtres, Produit des données qui incluent quatre entités par «une» donnée. En termes de dimensions, il s'agit de [1,4] données.
Ensuite, préparez les données de réponse correctes.
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
Définissez la réponse correcte pour la sortie "une donnée". Étant donné que la chaîne de caractères ne peut pas être définie, "0" pour les données du modèle A, S'il s'agit de B du motif B, réglez-le sur "1". Puisqu'il s'agit des données de réponse correctes pour une donnée, la dimension des données de réponse correcte est la donnée de [1].
Image dimensionnelle
#Cet exemple
[Structure des données de sortie]
-Les données
-Première fonctionnalité
-Deuxième caractéristique
-Troisième caractéristique
-Quatrième fonctionnalité
[Structure des données de réponse correcte]
-Répondre aux données(1?0?)
test.py
loss = criterion(outputs, answer_data)
Puis calculez l'erreur. Puisque le poids est ajusté pour chaque étiquette de réponse correcte, incluez également l'étiquette de réponse correcte.
optimizer.step()
Ensuite, il exécute un nouveau processus appelé optimisation, qui n'est pas encore apparu. Dans la boucle for, saisissez les données de sortie pour chaque type A et type B, Je pense que le poids est ajusté pour que l'erreur dans chaque type s'approche de 0. (Comme il est maintenant dans la phase d'arrêt de la réflexion, j'étudierai plus tard le type d'ajustements en cours!)
Qu'est-ce que l'optimisation? Comme avec wikipedia, trouver l'état optimal d'un programme s'appelle l'optimisation. Ici, l'optimisation est effectuée en calculant où l'erreur est minimisée.
Résultat d'exécution
Voyons le résultat de l'exécution.
***Phase de test***
Taux de réponse correct: 100.0 %
Oui, c'est 100%. Ce qui était de 0% avant l'apprentissage était capable d'apprendre en toute sécurité.
Optimisation (mise en œuvre par vous-même)
Le cœur du processus est le processus d'optimisation effectué par $ optimizer.step () $. Il existe de nombreuses méthodes d'optimisation qui peuvent être utilisées avec pytorch, et cette fois j'ai choisi SGD (Probabilistic Gradient Descent Method).
En regardant en arrière sur le processus d'optimisation effectué jusqu'à présent, J'utilise juste une fonction déjà implémentée dans pytorch et je ne fais rien.
Lorsque vous souhaitez mettre en œuvre une méthode d'optimisation dans votre article Que dois-je faire spécifiquement?
... donc Tout d'abord, nous allons implémenter une méthode d'optimisation simple appelée "Sudden Descent Method (GD)" à titre d'exemple. Tout d'abord, la méthode de descente la plus raide n'est pas pratique. Les temps reculent par rapport au SGD utilisé cette fois. Cependant, je pense que cela convient pour étudier, donc Implémentons la méthode de descente la plus raide.
Image d'optimisation
Qu'est-ce que l'optimisation? Afin de donner une image intuitive, exprimons-la dans une formule simple. (Je n'ai lu aucun article au moment de faire ceci. Puisqu'il s'agit d'une image, je fais une erreur au sens strict. Juste pour référence ...)
y = f(x)
Lorsque j'ai mis les données d'entrée dans le réseau, la valeur de la fonction est revenue sous forme de valeur numérique. En d'autres termes, si vous entrez les données d'entrée $ x $, $ y $ sera renvoyé comme sortie. Soit cela $ y = f (x) $.
gosa = |f(A)-f(B)|
Et lorsque les données d'entrée $ A $ et $ B $ sont données à cette formule, Je veux ajuster pour que la différence soit la valeur minimale. Puisque A et B sont en fait les mêmes données, nous voulons obtenir le même résultat de sortie.
gosa(weight) = |g(A)-g(B)|\\
g(x) = weight * f(x)
Maintenant, introduisez le paramètre $ weight $. Pondérer la fonction réseau $ f (x) $. Le problème de vouloir minimiser l'erreur en introduisant cette formule est Il remplace la recherche du paramètre $ weight $ qui peut minimiser l'erreur.
Tout ce que vous avez à faire est de trouver le $ poids $ qui minimise $ gosa (poids) $.
Optimiser avec un simple graphique
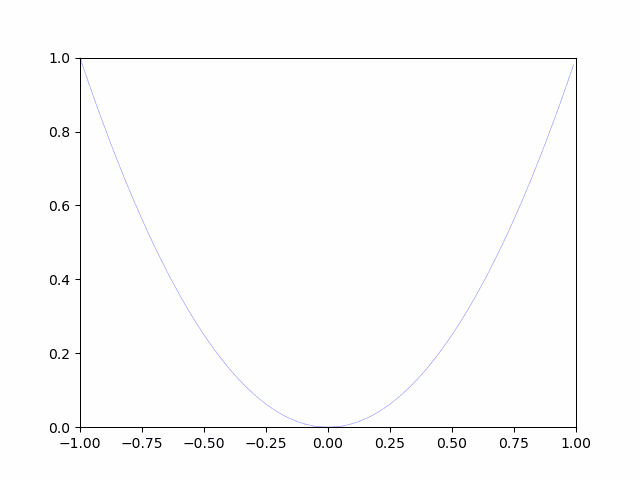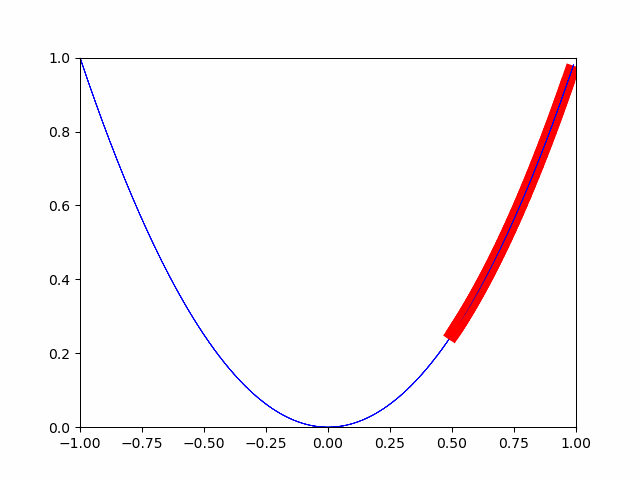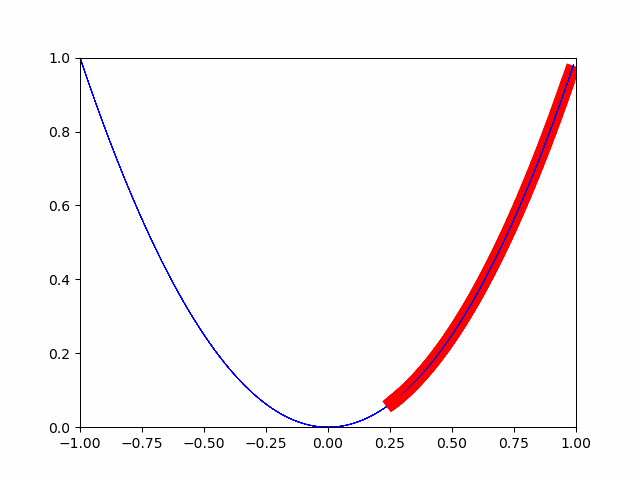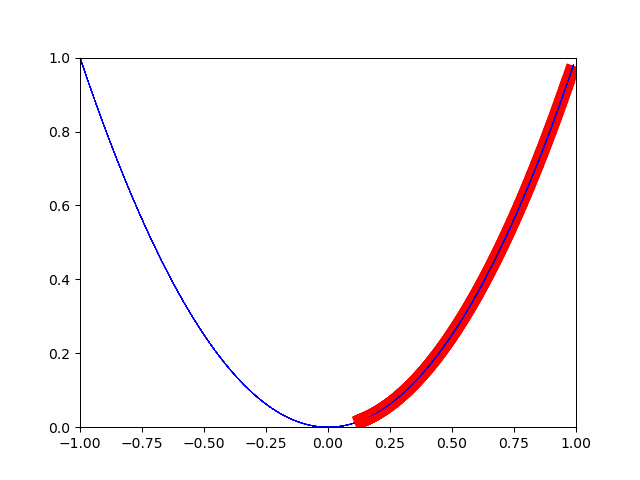
Optimisons avec une formule simple. En parlant du problème de minimisation, j'ai fait le problème $ y = x ^ 2 $ quand j'étais au collège. À ce moment-là, la valeur minimale était calculée à l'aide d'une formule très limitée, en supposant un calcul manuel.
Ici, en supposant que $ y = x ^ 2 $ est $ gosa (poids) $, Résolvons-le avec une méthode d'optimisation appelée méthode de descente la plus raide.
y = x^2\\
\frac{d}{dy}
=
2x
Le différentiel $ \ frac {d} {dy} $ de $ y = x ^ 2 $ est comme ci-dessus. Le graphe $ y = x ^ 2 $ est un graphe qui change progressivement dans la plus petite unité de $ \ frac {d} {dy} $.
La méthode de descente la plus raide consiste à se déplacer progressivement par un petit changement. Il s'agit d'une méthode qui considère le point où le changement minute est complètement 0 comme la valeur minimale. (Quand j'étais au collège, il y avait un problème en ce que les points où l'inclinaison devenait 0 étaient le minimum et le maximum.)
Alors, essayons d'utiliser la fonction de différenciation automatique de pytorch.
Comme vous pouvez le voir sur l'image, il se rapproche progressivement de la valeur minimale. De cette manière, l'optimisation est effectuée pour la valeur minimale.
Ci-dessous, la source.
test.py
if __name__ == '__main__':
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Gamme graphique
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*Pour définir x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 800 #Nombre d'apprentissage
eta = 0.01 #Largeur de pas
x_arr = []
f_arr = []
x_tor = torch.tensor([1.0], requires_grad=True)
for epoch in range(n_epoch):
#Définition de la fonction à optimiser
f = func(x_tor)
# x_Calculer la pente au point tor
f.backward()
with torch.no_grad():
# 1.Méthode de gradient
# x_Soustrayez peu à peu les changements infimes du tor,
#Approcher progressivement la valeur minimale
x_tor = x_tor - eta * x_tor.grad
# 2.C'est le traitement pour l'animation
f = x_tor[0] ** 2
x_arr.append(float(x_tor[0]))
f_arr.append(float(f))
x_tor.requires_grad = True
def update_anim(frame):
#Processus d'enregistrement de gif
#Après avoir exécuté FuncAnimation, il est exécuté automatiquement et à plusieurs reprises.(frame =Nombre de cadres)
ims = []
if frame == 0:
y = f_arr[frame]
x = x_arr[frame]
else:
y = [f_arr[frame-1],f_arr[frame]]
x = [x_arr[frame-1],x_arr[frame]]
ims.append(ax.plot(F_main ,F_main*F_main,color="b",alpha=0.2,lw=0.5))
ims.append(ax.plot(x ,y,lw=10,color="r"))
# im.set_data(x, y)
return ims
anim = FuncAnimation(fig, update_anim, blit=False,interval=50)
anim.save('GD_modèle 1.gif', writer="pillow")
exit()
Mise en œuvre de l'optimisation (méthode de descente la plus raide)
J'essaierai de le mettre en œuvre. Le but de cette section n'est pas de mettre en œuvre la méthode de descente la plus raide elle-même. Ceci est une vérification pour confirmer que "c'est ainsi que vous implémentez votre propre fonction d'optimisation".
Aussi, ce qui est écrit de longue date, donc je n'écrirai que les points principaux.
test.py
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
Dans pytorch, vous pouvez sélectionner différentes méthodes d'optimisation à partir d'optim. Les implémentations de chaque technique sont créées en héritant d'une classe appelée $ torch.optim.Optimizer $. D'un autre côté, vous pouvez facilement créer votre propre classe héritée pour $ torch.optim.Optimizer $. Donc, comme avant, optimisez pour $ y = x ^ 2 $.
Cet exemple n'utilise pas de réseau neutre, Si je définis $ SimpleGD $ de la même manière, il peut toujours être utilisé dans un réseau neutre.
↓ ↓ ↓ Source globale ↓ ↓ ↓
test.py
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Ajout de tenseur
# p = p - d/dp(Petits changements) * lr
# (lr est multiplié car la plage de variation est trop petite s'il ne s'agit que d'un petit changement)
p.add_(d_p*-group['lr'])
return loss
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Gamme graphique
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*Pour définir x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 50 #Nombre d'apprentissage
eta = 0.01 #Largeur de pas
x_tor = torch.tensor([1.0], requires_grad=True)
param=[x_tor]
optimizer = SimpleGD(param, lr=0.1)
for epoch in range(n_epoch):
optimizer.zero_grad()
#Définition de la fonction à optimiser
f = func(x_tor)
# x_Calculer la pente au point tor
f.backward()
optimizer.step()
x_tor.requires_grad = True
#Peu à peu y=x*Valeur minimale de x=0.Aller à 0
# print(x_tor)
exit()
Parmi ceux-ci, le plus important C'est la partie "class Simple GD" qui déclare votre propre fonction d'optimisation.
test.py
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Ajout de tenseur
# p = p - d/dp(Petits changements) * lr
# (lr est multiplié car la plage de variation est trop petite s'il ne s'agit que d'un petit changement)
p.add_(d_p*-group['lr'])
return loss
Regardons de plus près. Tout d'abord à propos de la partie init.
test.py
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
lr est lors de la soustraction de changements minutes S'il ne s'agit que d'un petit changement, la plage de changement est trop petite ou trop grande, donc Les paramètres à appliquer aux changements de minute sont spécifiés.
SimpleGD nécessitait lr, donc je l'ai déclaré ici. Si vous avez besoin d'autres choses, ajoutez-les à l'argument init et ajoutez fermement la déclaration dans le dict.
test.py
@torch.no_grad()
def step(self, closure=None):
Il s'agit d'une fonction qui doit être déclarée lors de l'héritage de la classe torch.optim.Optimizer. L'optimisation se fait en appelant cette fonction pendant l'entraînement.
self.param_groups sont les paramètres que vous avez transmis lors de la création de l'instance SimpleGD. Si le gradient (petit changement) a déjà été calculé avec backward (), vous pouvez également obtenir le gradient à partir d'ici.
test.py
d_p = p.grad
#Ajout de tenseur
# p = p - d/dp(Petits changements) * lr
# (lr est multiplié car la plage de variation est trop petite s'il ne s'agit que d'un petit changement)
p.add_(d_p*-group['lr'])
Obtenez p.grad, c'est-à-dire des changements infimes, Le changement minute est reflété dans p = tenseur. Par cette opération, les paramètres se déplacent progressivement vers la valeur minimale.
・ ・ ・ ・ Étant donné que la méthode de descente la plus raide ne soustrait qu'une minute, elle tombe facilement dans une solution locale. Solution locale. Imaginez un graphique avec beaucoup de bosses comme $ y = x ^ 2 $. Puisque la méthode de descente la plus raide considère l'endroit où l'inclinaison devient 0 comme valeur minimale, Chaque fois qu'il atteint l'une des extrémités de ce convexe, il sera considéré comme une valeur extrême.
À partir de là, on peut dire que cette méthode n'est robuste pour aucune donnée.
en conclusion
Dans les chapitres 1 et 2, j'ai eu un petit aperçu du réseau.
Quant à l'horaire après la prochaine fois, Étudier l'apprentissage automatique du système de groupes de points que je voulais le plus étudier, Etudiez en particulier PointNet.
Après cela, j'étudierai RNN, l'encodeur automatique, le GAN et le DQN.
Recommended Posts