Trouver la fonction de distribution cumulative par tri (version Python)
Cet article est une réécriture de Calculer la fonction de distribution cumulative par tri écrit en Ruby en Python.
introduction
Lorsque vous voulez connaître la fonction de densité de probabilité (PDF) d'une certaine variable de probabilité, vous utilisez un histogramme pour naïf, mais il faut des essais et des erreurs pour couper les bacs, et il faut un nombre considérable de mesures pour obtenir un graphique propre. Il est difficile de devenir. Dans un tel cas, il est plus facile de regarder la fonction de distribution cumulative (CDF) au lieu de la fonction de densité de probabilité, et il est plus facile de la trouver avec un seul tri. Dans ce qui suit, nous présenterons les différences entre les nombres aléatoires qui suivent la distribution normale lorsqu'ils sont visualisés en PDF et lorsqu'ils sont visualisés dans CDF. L'opération a été confirmée par Google Colab.
Obtenez la fonction de densité de probabilité dans l'histogramme
Voyons d'abord comment obtenir la fonction de densité de probabilité à partir de l'histogramme. Importez toutes les bibliothèques dont vous aurez besoin plus tard.
import random
import matplotlib.pyplot as plt
import numpy as np
from math import pi, exp, sqrt
from scipy.optimize import curve_fit
from scipy.special import erf
Générez 1000 nombres aléatoires qui suivent une distribution gaussienne avec une moyenne de 1 et une variance de 1.
N = 1000
d = []
for _ in range(N):
d.append(random.gauss(1, 1))
Quand je le trace, ça ressemble à ça.
plt.plot(d)
plt.show()
Il semble qu'il oscille autour de 1.
Faisons un histogramme et trouvons la fonction de densité de probabilité. Vous pouvez également le trouver avec matplotlib.pyplot.hist, mais j'utilise numpy.histogram comme passe-temps pour recevoir des valeurs.
hy, bins = np.histogram(d)
hx = bins[:-1] + np.diff(bins)/2
hy = hy / N
plt.plot(hx,hy)
plt.show()
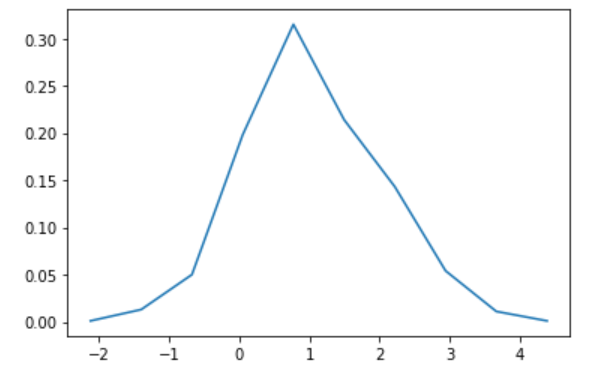
Cela ressemble à une distribution gaussienne, mais c'est assez fou.
Maintenant, supposons que cet histogramme a une distribution gaussienne et trouvons la moyenne et l'écart type. Utilisez scipy.optimize.curve_fit.
Tout d'abord, définissez la fonction utilisée pour l'ajustement.
def mygauss(x, m, s):
return 1.0/sqrt(2.0*pi*s**2) * np.exp(-(x-m)**2/(2.0*s**2))
Notez que vous devez utiliser np.exp au lieu de ʻexp car le tableau NumPy est passé à x. Si vous passez cette fonction et ces données à scipy.optimize.curve_fit`, il renverra un tableau d'estimations et une matrice de covariance, donc affichons-le.
v, s = curve_fit(mygauss, hx, hy)
print(f"mu = {v[0]} +- {sqrt(s[0][0])}")
print(f"sigma = {v[1]} +- {sqrt(s[1][1])}")
Puisque les composantes diagonales de la matrice de covariance sont des dispersions, les racines carrées sont affichées comme des erreurs. Le résultat est différent à chaque fois, mais il ressemble à ceci, par exemple.
mu = 0.9778044193329654 +- 0.16595607115412642
sigma = 1.259695311989267 +- 0.13571713273726863
Alors que les vraies valeurs sont toutes les deux 1, la valeur moyenne estimée est de 0,98 + -0,17 et l'écart type est de 1,3 + -0,1, ce qui n'est pas une grande différence, mais ce n'est pas bon.
Obtenir la fonction de distribution cumulative par tri
La fonction de distribution cumulative $ F (x) $ est la probabilité que la valeur d'une certaine variable de probabilité $ X $ soit inférieure à $ x $, c'est-à-dire
Est. Maintenant, supposons que lorsque $ N $ de données indépendantes est obtenu, la valeur $ k $ th est $ x $ en les arrangeant par ordre croissant. Ensuite, la probabilité que la variable de probabilité $ X $ soit inférieure à $ x $ peut être estimée à $ k / N $. À partir de ce qui précède, la fonction de distribution cumulative peut être obtenue en triant le tableau obtenu de variables de probabilité $ N $ et en traçant les données $ k $ th sur l'axe des x et $ k / N $ sur l'axe des y. Voyons voir.
sx = sorted(d)
sy = [i/N for i in range(N)]
plt.plot(sx, sy)
plt.show()
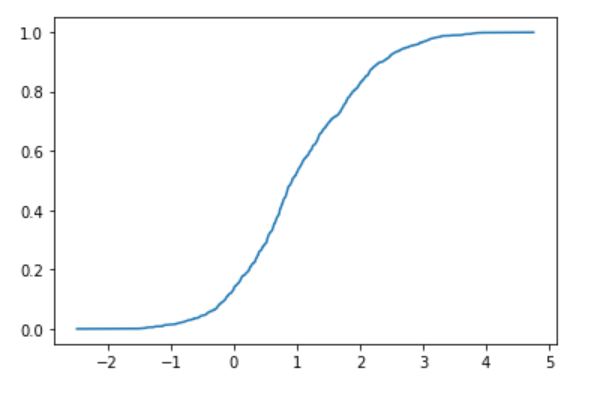
Une fonction d'erreur relativement belle a été obtenue. Comme précédemment, considérez cela comme une fonction d'erreur et trouvez la moyenne et la variance par ajustement. Commencez par préparer la fonction d'erreur pour l'ajustement. Notez que la définition de la fonction d'erreur dans le monde est délicate, vous devez donc ajouter 1 et diviser par 2, ou diviser l'argument par √2.
def myerf(x, m, s):
return (erf((x-m)/(sqrt(2.0)*s))+1.0)*0.5
Mettons-le en place.
v, s = curve_fit(myerf, sx, sy)
print(f"mu = {v[0]} +- {sqrt(s[0][0])}")
print(f"sigma = {v[1]} +- {sqrt(s[1][1])}")
Le résultat ressemble à ceci.
mu = 1.00378752698032 +- 0.0018097681998120645
sigma = 0.975197323266848 +- 0.0031393908850607445
La moyenne est de 1,004 + -0,002 et l'écart type est de 0,974 + -0,003, ce qui représente une amélioration considérable malgré l'utilisation exactement des mêmes données.
Résumé
Pour voir la distribution des variables stochastiques, j'ai présenté comment obtenir la fonction de densité de probabilité à l'aide d'un histogramme et comment trier et voir la fonction de distribution cumulative. L'histogramme nécessite beaucoup d'essais et d'erreurs sur la façon de couper le bac, mais il est facile de voir la fonction de distribution cumulative par tri car aucun paramètre n'est requis. Même si vous souhaitez une fonction de densité de probabilité, vous pouvez obtenir des données plus claires en recherchant une fois la fonction de distribution cumulative, puis en effectuant une moyenne mobile et en la différenciant numériquement.
En outre, la fonction de distribution cumulative est plus précise dans l'estimation des paramètres de la distribution d'origine. Ceci est intuitivement dans la zone d'intérêt (par exemple, près de la valeur moyenne), lors de l'utilisation de l'histogramme, seul le nombre de données dans le bac peut être utilisé, mais dans le cas de la fonction de distribution cumulative, environ $ N / 2 $ de données peuvent être utilisés. Je pense que cela peut être utilisé, mais je ne suis pas si confiant, alors demandez à un professionnel à proximité.
Recommended Posts