[PYTHON] Données d'entraînement et données de test (Que sont X_train et y_train?) ①
Cette fois en apprentissage supervisé Décrit les données d'entraînement et les données de test.
■ Données d'entraînement et données de test
Données d'entraînement: données pour créer des formules de modèle (formules qui représentent la pertinence des données) Données de test: données pour vérifier la précision de la formule créée
Même si vous pouvez exprimer la pertinence des données par une expression, ce serait un problème si vous n'avez pas les données pour l'essayer.
Maintenant, laissez-moi vous expliquer avec un exemple concret simple.
Par exemple, si vous disposez des données suivantes:
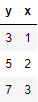 Maintenant, divisez les données de ce tableau comme suit.
Maintenant, divisez les données de ce tableau comme suit.
Données d'entraînement
 données de test
données de test
 En ce moment, je veux d'abord trouver la pertinence des données.
Considérez les formules candidates pour y et x (formules de modèle) à partir des données d'apprentissage.
En ce moment, je veux d'abord trouver la pertinence des données.
Considérez les formules candidates pour y et x (formules de modèle) à partir des données d'apprentissage.
Candidat 1: $ y = 3x $ Candidat 2: $ y = 2x + 1 $
J'ai créé une formule modèle en utilisant les données d'entraînement. Cependant, cela seul ne nous dit pas si cette formule tient vraiment. C'est pourquoi nous avons des données de test pour vérification.
Vérifiez si les données suivantes sont valables pour la formule de modèle créée.
La façon de vérifier est de remplacer x dans les données de test dans la formule du modèle et de voir si c'est vraiment y.
Candidat 1: $ y = 3x = 3 \ fois3 = 9 $
Candidat 2: $ y = 2x + 1 = 2 \ times3 + 1 = 7 $
Bonne réponse: $ y = 7 $
Pour cette raison, concernant les données préparées cette fois Il s'avère que le candidat 2 est plus précis que le candidat 1.
De cette façon, dans l'apprentissage automatique, trouver la pertinence des données à partir des données d'entraînement (création d'une formule modèle) Nous avons un mécanisme pour vérifier si les données de test sont réellement exactes.
■ Appliquer X_train, y_train
Alors, que sont exactement X_train, y_train, X_test, y_test?
train: données d'entraînement (abréviation de formation) test: données de test (données qui vérifient la formule du modèle)
Lorsqu'il est appliqué aux données préparées cette fois, il ressemble à ceci.
Données d'entraînement
 données de test
données de test
 Comme précédemment, considérez la formule du modèle à partir des données d'entraînement.
Comme précédemment, considérez la formule du modèle à partir des données d'entraînement.
Candidat 1: $ y = 3x $ Candidat 2: $ y = 2x + 1 $
Ceci termine la formule du modèle. Après cela, nous vérifierons leur précision en utilisant des données de test.
Auparavant, remplacez x des données de test dans la formule du modèle pour obtenir la valeur prévue y. J'ai vérifié qu'il correspond au y réel.
La valeur prédite à ce moment est exprimée en y_pred. (Prédire)
données de test
Candidat 1: $ y_ {pred} = 3x_ {test} = 3 \ fois3 = 9 $
Candidat 2: $ y_ {pred} = 2x_ {test} + 1 = 2 \ times3 + 1 = 7 $
Bonne réponse: $ y_ {test} = 7 $
Par conséquent, dans la formule modèle créée cette fois Il s'avère que le candidat 2 est plus précis.
En d'autres termes, il est résumé ci-dessous.
X_train, y_train: données pour créer des formules de modèle (expressions de pertinence des données) X_test: Données à affecter à l'expression de modèle et à donner votre propre réponse y_pred y_test: données de réponse vraies correctes (identiques à la réponse du modèle en mathématiques), pour répondre avec votre propre y_pred
C'est un peu déroutant que seul y_test soit traité comme une réponse modèle, n'est-ce pas?
En apprentissage supervisé (avec données de test), essentiellement basé sur cette idée Nous créons et vérifions diverses formules modèles.
Recommended Posts