[PYTHON] J'ai essayé les réseaux d'itération de valeur
C'est le 12ème jour du Calendrier de l'Avent Chainer 2016.
~~ Actuellement, à 18 heures le 11, cela prendra encore 14 heures si nous finissons enfin l'implémentation et commençons à apprendre sur AWS \ (^ o ^) / ~~
NOUVEAU code a été publié! (Remarque: j'ai remanié diverses choses, donc je suis désolé si cela ne fonctionne pas. Je prévois de vérifier l'opération après avoir vu un espace. Je suis désolé de ne pas avoir le document.) https://github.com/peisuke/vin
À propos de l'article
Dans cet article, j'écrirai un commentaire sur l'article qui a remporté le prix du meilleur article au NIPS 2016 (la semaine dernière!), Qui est la plus haute conférence de l'apprentissage automatique, et le résultat de sa mise en œuvre dans Chainer.
~~ Cependant, j'ai commencé à lire l'article après avoir su que j'avais gagné le prix, donc j'avais un calendrier de dernière minute comme indiqué ci-dessus, et les résultats expérimentaux ne sont pas encore sortis ... Alors, ajoutez plus de contenu à l'article ... Aussi, même s'il sera un peu tard, je posterai certainement les résultats expérimentaux, peut-être. ~~ J'ai réussi à poster les résultats expérimentaux!
Contexte
Le problème traité dans l'article est de définir le départ et l'objectif sur la carte et de trouver le chemin le plus court lorsque le robot se déplace dans l'environnement, comme indiqué dans la figure ci-dessous. Bien sûr, de tels problèmes existent depuis longtemps, mais les recherches antérieures nécessitent de supposer que l'environnement et les modèles de robots sont connus. En fait, il n'est pas possible de décrire complètement un modèle de robot, donc le but est de pouvoir rechercher un itinéraire sans modélisation en apprenant cette zone.

Lorsque le robot fonctionne dans l'environnement, l'action suivante doit être prise en considération des futurs changements environnementaux. L'itération de valeur est le processus d'ajout de la valeur de récompense de l'état actuel (atteint l'objectif, approche de l'objectif, etc.) et la valeur de récompense de l'état suivant qui a temporairement avancé l'opération d'une étape. En le répétant, vous pouvez découvrir à quel point l'état actuel du robot est bon dans le futur et comment passer à autre chose.
Cependant, il n'est pas facile de pré-calculer la vraie valeur de récompense de l'état actuel. En effet, vous devez calculer toutes les étapes pour atteindre l'objectif, car vous pouvez enfin obtenir la valeur de la récompense. Cela peut être réalisé en simulant parfaitement tous les changements dans l'environnement, les modèles de robot, etc., et en exécutant une grande quantité de traitements de calcul, mais il y a très peu de cas où cela est possible. Par conséquent, on pense que la simulation ci-dessus et une grande quantité de calculs peuvent être évités en apprenant la future récompense appropriée pour la situation en utilisant le Deep Learning, et diverses méthodes ont été étudiées.
L'une des méthodes les plus connues est Deep Q-Network. Cela utilise une méthode appelée apprentissage renforcé, dans laquelle le robot fait des erreurs en effectuant ses propres mouvements dans l'environnement, et se souvient du type d'action à entreprendre dans quelle situation. Cependant, étant donné que Deep Q-Network fait des erreurs dans la mise en œuvre d'un environnement donné, il existe un problème en ce que les résultats d'apprentissage ne peuvent pas être détournés lorsque l'environnement change. En outre, il peut être possible de le résoudre en propageant l'erreur d'application à un autre environnement. Il est possible que ce soit le cas, mais il a été rapporté dans cet article que la précision ne s'est pas améliorée grâce à des expériences. Maintenant, comme un autre moyen, l'apprentissage par imitation (apprentissage par manet) peut être mentionné. Il s'agit d'apprendre l'action à entreprendre en imitant directement l'action de l'expert sans commettre d'erreur d'exécution. L'apprentissage sera plus facile car vous n'avez pas à faire d'erreurs d'application supplémentaires. D'un autre côté, il reste le problème qu'il ne peut pas être appliqué correctement aux changements dans l'environnement.
En premier lieu, il est tout à fait nécessaire de prédire convenablement l'environnement en l'absence d'informations pour décider du mouvement basé sur l'apprentissage en anticipation du futur quel que soit le nouvel environnement sans donner manuellement un modèle du robot ou de l'environnement. C'est difficile. Si une telle chose peut être faite, un robot qui peut lire et faire fonctionner l'air sans apprentissage ni programmation peut être réalisé.
** Il semble que cela ait été fait. ** **
Voilà pourquoi. lis. Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel, "Value Iteration Networks", NIPS 2016. Et l'auteur est aussi un tel visage, S.Levine et P. Abbeel
À propos des réseaux d'itération de valeur
Je suis désolé, l'introduction est devenue plus longue. Cette recherche a été décevante car j'ai également essayé et échoué. À propos, le réseau d'itération de valeur consiste simplement (1) à estimer la récompense de l'état d'entrée par CNN, (2) à propager la récompense en fonction de l'action entreprise par elle-même, et (3) à l'estimer. La structure est telle que seule la récompense à la position d'intérêt est coupée, et (4) l'opération est déterminée par couplage complet. La formule est difficile à écrire, je vais donc l'omettre.

Dans la figure ci-dessus dans l'article, l'observation $ \ phi (s) $ multiplie l'image d'entrée par CNN, et la met dans la récompense estimée $ \ bar {R} $. De plus, $ \ bar {P} $ est une conversion de la façon dont l'état change lorsque l'action $ a $ est donnée à l'état $ s $, mais dans ce problème, le changement d'état est ignoré comme connu. .. Le module VI calcule la quantité de récompense accumulée à partir d'une carte de récompense estimée donnée, qui sera décrite plus tard. L '"Attention" dans l'image suivante est la partie découpée de quel côté de l'image faire la mise au point. Dans le Deep Learning ordinaire, il est souvent connecté de tout l'écran à la couche FC, mais c'est difficile car les paramètres augmentent. En revanche, si vous savez quel côté de l'écran contient les informations souhaitées, vous pouvez facilement calculer en ciblant uniquement cette zone. Dans ce cas, les informations de récompense pour déterminer la direction de mouvement suivante sont ajoutées à la propre position du robot, de sorte que la position du robot $ s $ est ciblée. Enfin, la couche FC est utilisée pour connecter les informations de récompense aux informations de comportement. En conséquence, vous savez quelle action entreprendre (droite, gauche, haut, bas, etc.), donc softmax cross entropy la compare avec la vraie direction de déplacement et calcule la propagation d'erreur inverse.
Maintenant, le module VI ressemble à ceci:

Tout d'abord, il se replie dans la récompense $ \ bar {R} $ donnée en entrée pour calculer $ \ bar {Q} $. $ \ bar {Q} $ calcule combien le mouvement $ a $ sera récompensé lorsque le robot sélectionne le mouvement $ a $, y compris la récompense actuelle. Enfin, en prenant MAX canal par canal, vous obtenez la récompense $ \ bar {V} $ pour le meilleur comportement. En calculant à nouveau le module VI en fonction de cette récompense, la récompense peut être propagée en séquence.
la mise en oeuvre
Maintenant que nous avons couvert l'ensemble, passons à la mise en œuvre. Cet article se compose de programmes séparés pour la préparation des données, l'apprentissage et l'affichage des résultats. Seules les parties d'apprentissage et de prédiction sont décrites ici. ~~ Je le téléchargerai bientôt sur github. ~~ Téléchargé.
Tout d'abord, à propos de l'initialisation du réseau.
class VIN(chainer.Chain):
def __init__(self, k = 10, l_h=150, l_q=10, l_a=8):
super(VIN, self).__init__(
conv1=L.Convolution2D(2, l_h, 3, stride=1, pad=1),
conv2=L.Convolution2D(l_h, 1, 1, stride=1, pad=0, nobias=True),
conv3=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
conv3b=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
l3=L.Linear(l_q, l_a, nobias=True),
)
self.k = k
self.train = True
conv1 et conv2 sont les poids de conversion des données cartographiques en récompense estimée. L'entrée est bidimensionnelle, l'image qui décrit l'obstacle sur la carte est affectée au canal 1 et l'image qui décrit la position de l'objectif est affectée au canal 2. Le résultat est la valeur de récompense à chaque position sur la carte et est unidimensionnel. conv3 est le poids pour la conversion à partir de la valeur de récompense, et conv3b est le poids pour convertir la valeur de récompense propagée par le VI en la valeur de récompense prédite correspondant au mouvement de position x. l3 est le poids obtenu par Attention pour convertir la future valeur de récompense prévue à la position du robot en mouvement final. Ensuite, le réseau est répertorié ci-dessous.
def __call__(self, x, s1, s2):
h = self.relu(self.conv1(x))
r = self.conv2(h)
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
return self.l3(q_out)
Si vous écrivez tout en même temps, il sera difficile de rattraper le retard, je vais donc le republier en le divisant en ce qui suit. Commencez par convertir l'image d'entrée en une valeur de récompense. C'est un CNN normal.
h = self.relu(self.conv1(x))
r = self.conv2(h)
Vient ensuite le module VI. En trouvant $ \ bar {Q} $ par la couche de convolution conv3 et en prenant MAX pour le canal de mouvement (axe = 1), le meilleur mouvement est sélectionné à chaque position dans la carte. La valeur de récompense à ce moment-là est v. Dans la phrase for, la valeur de récompense estimée directement à partir de la carte et la valeur de récompense propagée sont ajoutées, et le même calcul que le premier est effectué.
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
La partie Attention qui réduit le nombre de paramètres en utilisant uniquement la partie proche de votre position à partir de la carte de récompense obtenue est la suivante. Tout d'abord, ajoutez r et v en utilisant $ \ hat {Q} $, qui renvoie la valeur de récompense pour chaque action sous forme de carte de récompense. Ensuite, pour chaque donnée du lot, récupérez le numéro sur la carte qui correspond à votre emplacement. C'est un peu délicat car vous ne pouvez pas faire des choses de type Fancy Index avec le chainer, mais préparez une matrice w avec 1 dans la position que vous souhaitez récupérer et 0 à d'autres endroits, et effacez les éléments inutiles en prenant le produit pour chaque élément. , La valeur de récompense prescrite est obtenue par réduction.
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
Enfin, la récompense est convertie en action et sortie.
return self.l3(q_out)
Ensuite, la classe de l'ensemble de données (ce code correspond au chainer 1.10 ou supérieur)
class MapData(chainer.dataset.DatasetMixin):
def __init__(self, im, value, state, label):
self.im = np.concatenate(
(np.expand_dims(im, 1), np.expand_dims(value,1)),
axis=1).astype(dtype=np.float32)
self.s1, self.s2 = np.split(state, [1], axis=1)
self.s1 = np.reshape(self.s1, self.s1.shape[0])
self.s2 = np.reshape(self.s2, self.s2.shape[0])
self.t = label
def __len__(self):
return len(self.im)
def get_example(self, i):
return self.im[i], self.s1[i], self.s2[i], self.t[i]
Le reste est presque le même que l'échantillon CIFAR-10. Je le téléchargerai bientôt sur github, y compris la génération de données. ~~ Téléchargé.
Résultat expérimental
Maintenant, c'est une expérience. L'expérience a été essayée avec les mêmes paramètres que cet article. Le nombre de données est de 5000 pour chaque type de carte, 7 types de départ sont décidés au hasard pour la carte et un seul type d'objectif est pour la carte. Le nombre d'objectifs est faible car il semble que beaucoup de temps de calcul soit nécessaire pour calculer les bonnes réponses. Sur les 5000 types, 1/5 a été utilisé comme données de test pour les expériences. L'expérience est menée sur AWS et dure environ plusieurs heures avec 30 époques. Je ne comprenais pas pourquoi il était affiché comme 14 heures au début de la phrase, mais si j'ajoutais cudnn séparément, cela pourrait être exécuté en quelques heures.
Tout d'abord, le cas de test 1 est montré. Le mur est noir et la plage de mouvement est blanche. Le point bleu en bas est le début et le point bleu clair en haut est l'objectif. L'itinéraire reconnu s'affiche en jaune. Même s'il y a un blocage qui le bloque sur le chemin, vous pouvez voir qu'il détourne correctement et atteint l'objectif.

Voici la carte de récompense estimée. Vous pouvez voir que la récompense pour la zone du mur est en baisse. En revanche, même sur une grande surface, la récompense semble être plus élevée dans la zone éloignée du mur.
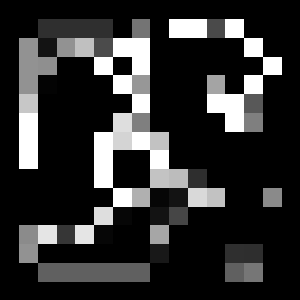
Enfin, il y a un diagramme des futures récompenses produites par le module VI. Vous pouvez voir que la récompense près de l'objectif est élevée. Lorsque vous choisissez un itinéraire, vous pouvez atteindre l'objectif en allant à la récompense la plus élevée.

Vient ensuite le cas de test 2. Cela ne change pas grand-chose, alors je vais l'expliquer brièvement. C'est un parcours qu'il faut faire un détour un peu plus grand, mais il semble que l'itinéraire puisse être reconnu correctement.

Il semble que vous puissiez reconnaître correctement la carte de récompense et la carte de récompense future.


Résumé
Je voulais faire une expérience un peu plus quantitative, mais je n'ai plus de temps, donc j'en ai fini avec ça pour le moment. Quant à l'impression, c'est un mot que VIN est vraiment incroyable. Même si c'est la première carte que je vois, l'itinéraire peut être estimé correctement! Je ne peux pas dire à quel point le problème peut être redimensionné à ce stade, mais j'ai trouvé que c'était une technique très intéressante. De plus, je suis heureux que cela se soit bien passé avec un seul coup.
Le chainer est toujours facile à utiliser! Cependant, afin de traiter des cas particuliers, j'aimerais que vous élargissiez un peu plus le Fancy Index ou que vous le différenciiez automatiquement.
Soit dit en passant, les questions restantes sont les deux points suivants.
- Bien que les données d'entraînement ne soient que l'itinéraire le plus court, nous avons pu apprendre même les récompenses de domaines non appris tels que les murs.
- Comme il était ajusté à l'itération de la valeur, il était possible d'apprendre même si VIM n'incluait pas de fonction d'activation non linéaire. Je pense que ce sont des conditions indispensables pour un Deep Learning normal, mais pour une raison quelconque, il était très étrange que cela fonctionne.
Au fait, il semble que la version implémentée par l'auteur basée sur Theano soit également disponible sur github.
Recommended Posts