[PYTHON] Calibrate the model with PyCaret
Introduction
- When classifying binary, it is good to determine the threshold value and classify Pos / Neg.
- Can I consider the output value of the model as the probability of becoming Positive? Is another matter.
- If you want to do the above, you may need to calibrate depending on the model.
- I would like to perform this calibration using PyCaret.
Make a model
- Follow the PyCaret tutorial and model with a decision tree as usual.
- Use the diabetes dataset as the dataset.
Data loading
from pycaret.datasets import get_data
diabetes = get_data('diabetes')

Modeling using a decision tree
- I want to classify, so import pycaret.classification.
- And you can model by specifying dt (decision tree) in create_model.
- Let's observe the created model with evalutate_model.
#Import classification package
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
#Make a decision tree
dt = create_model(estimator='dt')
#Visualization
evaluate_model(dt)
Check the Calibration Curve before calibration
- Click the button below to check the Calibration Curve.
- The horizontal axis is the one that binned the scoring result of the model and arranged it in order of value.
- The vertical axis is the percentage of positive data that appeared up to that bin.
- In an ideal situation (*)
- Positive data appears in a well-balanced manner with respect to the output value of the model.
- The model (blue line) approaches the diagonal ideal line (dashed line)
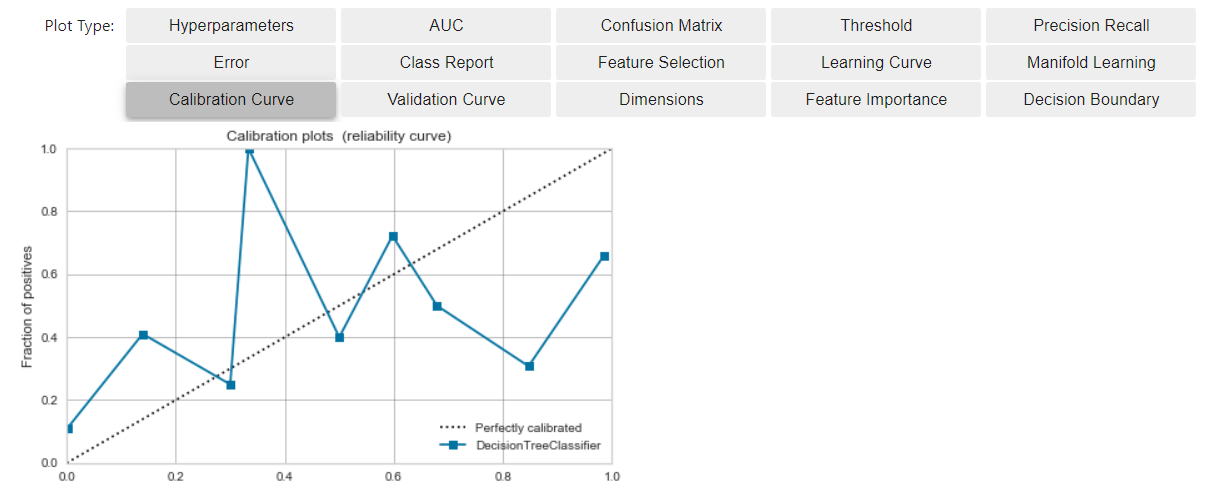
Calibrate the model
- Calibration is the work to bring the current model closer to the situation described above (*). By approaching the situation of * *, it becomes easier to regard the model output value as the probability that the prediction result is Positive.
- The implementation method is simple, use calibrate_model.
#Calibrate
calibrated_dt = calibrate_model(dt)
#Visualize
evaluate_model(calibrated_dt)
- Compared to the previous time, the model (blue line) is closer to the ideal line (broken line).
- For model scoring results
- We were able to create a linear increase in the cumulative appearance rate of Positives at that time (a situation close to *).
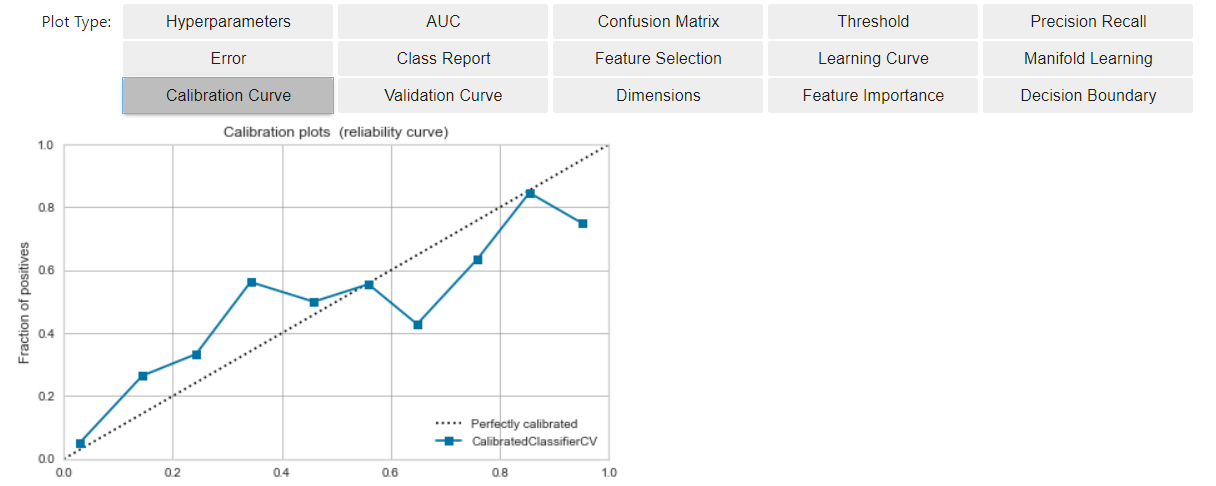
What is the calibration done?

- It seems that you are using sklearn.calibration.CalibratedClassifierCV.
- sklearn supports'sigmoid'and'isotonic' as calibration methods, but pycaret has similar documentation.
Which model needs calibration "Yes?"
-
Since the margin of SVM is maximized, the model output value is concentrated at 0.5 and calibration is required because the area around the decision boundary is strictly checked. The point is [this article](https://yukoishizaki.hatenablog.com/entry/2020/05/24/145155#:~:text=SVM%E3%81%AF%E3%83%9E%E3% It is discussed in 83% BC% E3% 82% B8% E3% 83% B3% E3% 82% 92% E6% 9C% 80% E5% A4% A7% E5% 8C% 96), but what about the others? Is it?
-
Leave the rigorous discussion of which model needs calibration to the expert, and in this article I'd like to write a Calibration Curve before and after calibration and observe what it tends to do.
-
Logistic regression
-
Originally, it can be interpreted as a positive probability, so it is well-balanced even before calibration.
-
It doesn't change much after calibration.
-
RBF kernel SVM
-
It's fierce. As mentioned in the above article, it seems that the data is close to 0.5 by maximizing the margin.
-
Calibration does not improve much, and it seems dangerous to treat the model output value as a probability.
-
Random forest
-
The balance seems to be good to some extent even before calibration.
-
This time, due to calibration, a peak has appeared around 0.7.
-
XGBoost,LightGBM
-
Moderate even before calibration. If you calibrate it, it will calm down a little.
| algorithm | Before calibration | After calibration |
|---|---|---|
| Logistic Regression |
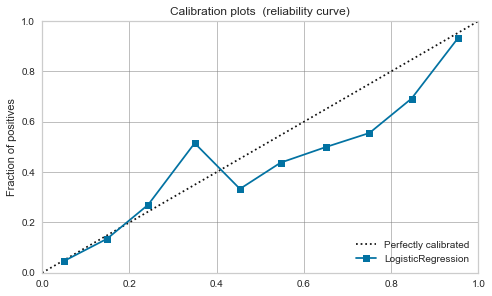 |
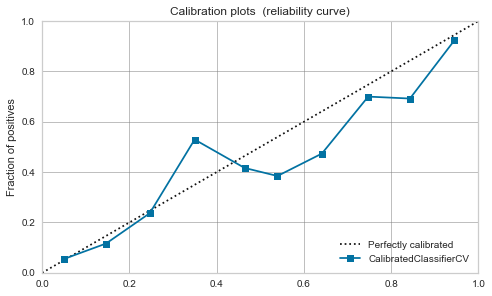 |
| RBF SVM | 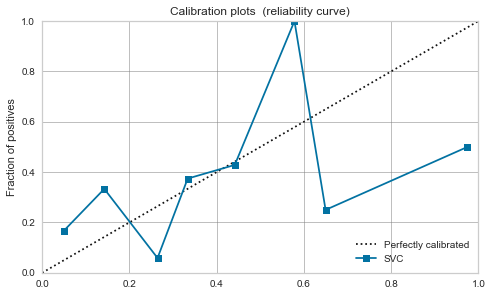 |
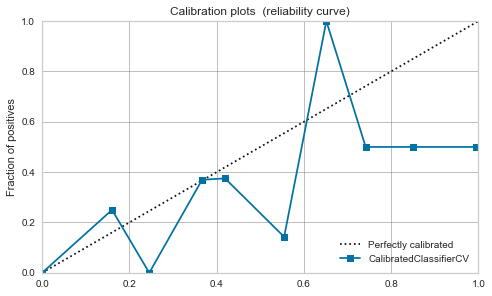 |
| Random Forest |
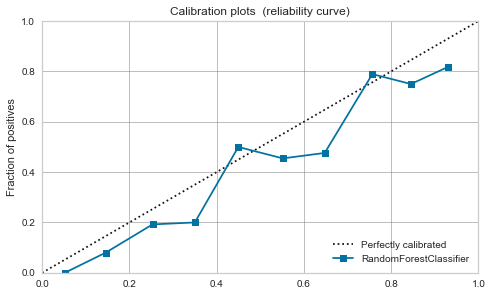 |
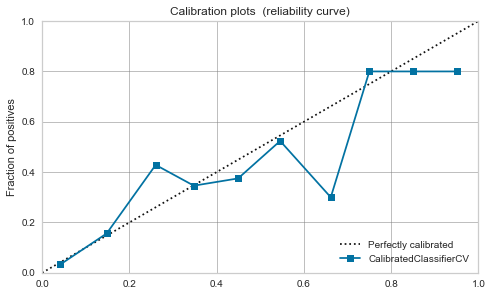 |
| XGBoost | 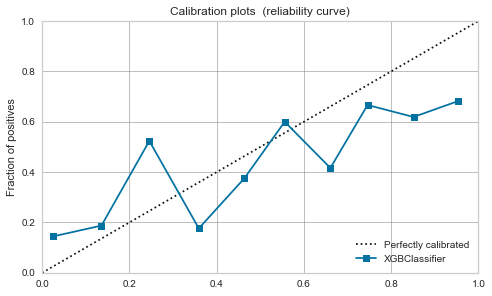 |
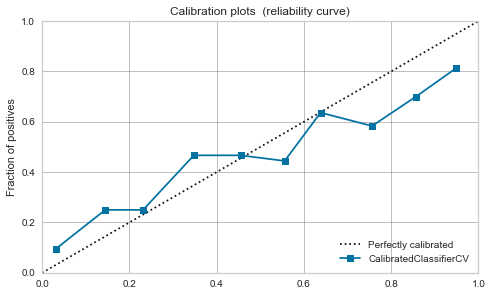 |
| LightGBM | 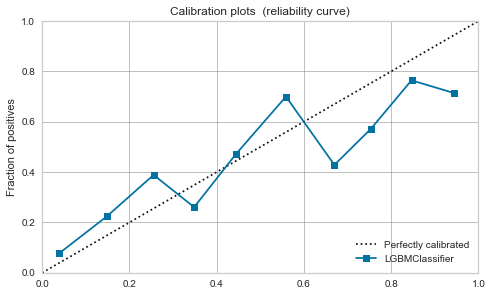 |
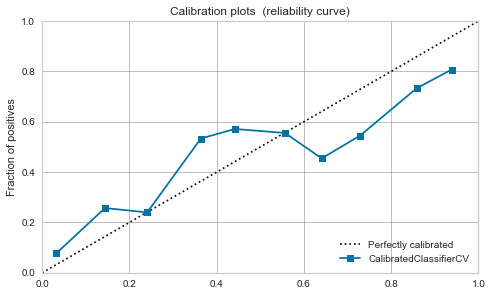 |
Finally
- I tried to calibrate the model with PyCaret.
- If you want to consider the model output value as the probability of Positive, you need to check the Calibration Curve.
- Even if calibrated, the original characteristics of the algorithm, such as maximizing the margin of SVM, may be severe.
- Some models, such as logistic regression, can be easily regarded as probabilities without calibration, so I think there is an approach to use them properly depending on the application.
Recommended Posts