[PYTHON] Data wrangling of Excel file of My Number card issuance status (September)
Introduction
[My Number System and My Number Card] of the Ministry of Internal Affairs and Communications (https://www.soumu.go.jp/kojinbango_card/)
- Excel format of My Number card issuance status (as of September 1, 2nd year of Reiwa)
Convert to CSV format of My Number Card Spread Status Dashboard
- August 1, 2nd year of Reiwa and September 1st, 2nd year of Reiwa Excel files have different formats, so only September 1st, 2nd year of Reiwa is supported.
- The base date is August at the end of each table, and September is in the column name (same as PDF).
- Separation of each table
Click here for My Number Card issuance status (as of August 1, 2nd year of Reiwa) https://qiita.com/barobaro/items/05efbb6aa2c759c80ff0
- In September, the base date is in the column name and each is extracted
- Each table is separated by the time point in the 2nd and 3rd columns of the column name, so extract based on that
Data wrangling
import csv
import datetime
import re
import pandas as pd
def wareki2date(s):
m = re.search("(H|R|Heisei|Reiwa)([0-9 yuan]{1,2})[.Year]([0-9]{1,2})[.Month]([0-9]{1,2})Day?",s)
year, month, day = [1 if i == "Former" else int(i) for i in m.group(2, 3, 4)]
if m.group(1) in ["Heisei", "H"]:
year += 1988
elif m.group(1) in ["Reiwa", "R"]:
year += 2018
return datetime.date(year, month, day).strftime("%Y/%m/%d")
def df_conv(df, col_name, population_date, delivery_date):
df.set_axis(col_name, axis=1, inplace=True)
df["Population base date"] = population_date
df["Base date for calculating the number of deliveries"] = delivery_date
df.insert(0, "Calculation base date", delivery_date)
return df
def my_round(s):
return int(s * 1000 + 0.5) / 10
df = pd.read_excel(
"https://www.soumu.go.jp/main_content/000707709.xlsx", sheet_name=1, header=None
)
df.dropna(thresh=3, inplace=True)
dfg = df.groupby(
(df[1].str.contains("Point in time", na=False) | df[2].str.contains("Point in time", na=False)).cumsum()
)
dfs = [g.dropna(how="all", axis=1).reset_index(drop=True) for _, g in dfg]
print(len(dfs))
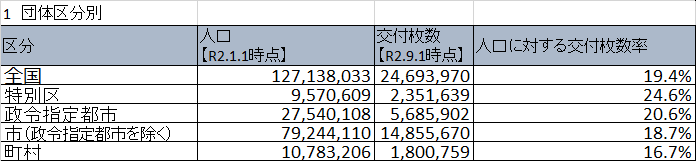
#By group classification
population_date = wareki2date(dfs[0].iat[0, 1])
delivery_date = wareki2date(dfs[0].iat[0, 2])
df0 = df_conv(
dfs[0].iloc[1:].reset_index(drop=True),
["Classification", "population", "Number of deliveries", "populationに対するNumber of deliveries率"],
population_date,
delivery_date,
)
df0["Number of grants to the population"] = df0["Number of grants to the population"].apply(my_round)
df0.to_csv(
"summary_by_types.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df0
#List of prefectures
population_date = wareki2date(dfs[3].iat[0, 1])
delivery_date = wareki2date(dfs[3].iat[0, 2])
df3 = df_conv(
dfs[3].iloc[1:].reset_index(drop=True),
["Name of prefectures", "Total number (population)", "Number of deliveries", "人口に対するNumber of deliveries率"],
population_date,
delivery_date,
)
df3["Number of grants to the population"] = df3["Number of grants to the population"].apply(my_round)
df3.to_csv(
"all_prefectures.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df3
#By gender and age
population_date = wareki2date(dfs[4].iat[0, 1])
delivery_date = wareki2date(dfs[4].iat[0, 4])
df4 = df_conv(
dfs[4].iloc[2:].reset_index(drop=True),
[
"age",
"population(Man)",
"population(woman)",
"population(Total)",
"Number of deliveries(Man)",
"Number of deliveries(woman)",
"Number of deliveries(Total)",
"Grant rate(Man)",
"Grant rate(woman)",
"Grant rate(Total)",
"Ratio of the number of grants to the whole(Man)",
"Ratio of the number of grants to the whole(woman)",
"Ratio of the number of grants to the whole(Total)",
],
population_date,
delivery_date,
)
df4["Grant rate(Man)"] = df4["Grant rate(Man)"].apply(my_round)
df4["Grant rate(woman)"] = df4["Grant rate(woman)"].apply(my_round)
df4["Grant rate(Total)"] = df4["Grant rate(Total)"].apply(my_round)
df4["Ratio of the number of grants to the whole(Man)"] = df4["Ratio of the number of grants to the whole(Man)"].apply(my_round)
df4["Ratio of the number of grants to the whole(woman)"] = df4["Ratio of the number of grants to the whole(woman)"].apply(my_round)
df4["Ratio of the number of grants to the whole(Total)"] = df4["Ratio of the number of grants to the whole(Total)"].apply(my_round)
df4.to_csv(
"demographics.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig",
)
df4
#By city
population_date = wareki2date(dfs[5].iat[0, 2])
delivery_date = wareki2date(dfs[5].iat[0, 3])
df5 = df_conv(
dfs[5].iloc[2:].reset_index(drop=True),
["Name of prefectures", "City name", "Total number (population)", "Number of deliveries", "人口に対するNumber of deliveries率"],
population_date,
delivery_date,
)
df5["Number of grants to the population"] = df5["Number of grants to the population"].apply(my_round)
df5["City name"] = df5["City name"].replace(r"\s", "", regex=True)
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Sasayama City, Hyogo Prefecture", "Tamba Sasayama City")
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Yusuhara Town, Takaoka District, Kochi Prefecture", "Yusuhara Town, Takaoka District")
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Sue Town, Kasuya District, Fukuoka Prefecture", "Sue-cho, Kasuya-gun")
if pd.Timestamp(df5.iloc[0]["Calculation base date"]) < datetime.date(2018, 10, 1):
df5["City name"] = df5["City name"].mask(
df5["Name of prefectures"] + df5["City name"] == "Nakagawa City, Fukuoka Prefecture", "Nakagawa-cho, Chikushi-gun"
)
else:
df5["City name"] = df5["City name"].mask(
df5["Name of prefectures"] + df5["City name"] == "Nakagawa Town, Chikushi County, Fukuoka Prefecture", "Nakagawa City"
)
df_code = pd.read_csv(
"https://docs.google.com/spreadsheets/d/e/2PACX-1vSseDxB5f3nS-YQ1NOkuFKZ7rTNfPLHqTKaSag-qaK25EWLcSL0klbFBZm1b6JDKGtHTk6iMUxsXpxt/pub?gid=0&single=true&output=csv",
dtype={"Group code": int, "Name of prefectures": str, "County name": str, "City name": str},
)
df_code["City name"] = df_code["County name"].fillna("") + df_code["City name"]
df_code.drop("County name", axis=1, inplace=True)
df5 = pd.merge(df5, df_code, on=["Name of prefectures", "City name"], how="left")
df5["Group code"] = df5["Group code"].astype("Int64")
df5.to_csv(
"all_localgovs.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df5