[PYTHON] Data wrangling of Excel file of My Number card issuance status (August)
Introduction
Data wrangling of Excel file of My Number card issuance status (September) continued
- August is extracted because the base date is at the end of each table
- Since there is no good delimiter for each table, turn it upside down and extract at the time
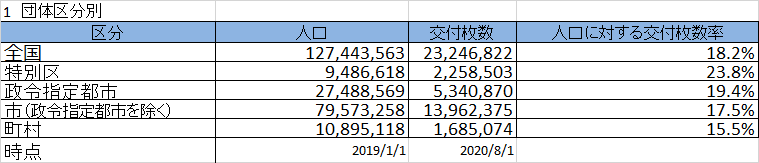
Data wrangling
import csv
import datetime
import pandas as pd
def df_conv(df, col_name, population_date, delivery_date):
df.set_axis(col_name, axis=1, inplace=True)
df["Population base date"] = population_date.strftime("%Y/%m/%d")
df["Base date for calculating the number of deliveries"] = delivery_date.strftime("%Y/%m/%d")
df.insert(0, "Calculation base date", delivery_date.strftime("%Y/%m/%d"))
return df
def my_round(s):
return int(s * 1000 + 0.5) / 10
df = pd.read_excel(
"https://www.soumu.go.jp/main_content/000703058.xlsx", sheet_name=1, header=None
).sort_index(ascending=False)
df.dropna(thresh=3, inplace=True)
dfg = df.groupby((df[0] == "Point in time").cumsum())
dfs = [g.dropna(how="all", axis=1).iloc[::-1].reset_index(drop=True) for _, g in dfg]
print(len(dfs))
#By group classification
dt = dfs[5].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
dfs[5].iloc[-1].dropna()
df0 = df_conv(
dfs[5].iloc[1:-1].reset_index(drop=True),
["Classification", "population", "Number of deliveries", "populationに対するNumber of deliveries率"],
population_date,
delivery_date,
)
df0["Number of grants to the population"] = df0["Number of grants to the population"].apply(my_round)
df0.to_csv(
"summary_by_types.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df0
#List of prefectures
dt = dfs[2].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df3 = df_conv(
dfs[2].iloc[1:-1].reset_index(drop=True),
["Name of prefectures", "Total number (population)", "Number of deliveries", "人口に対するNumber of deliveries率"],
population_date,
delivery_date,
)
df3["Number of grants to the population"] = df3["Number of grants to the population"].apply(my_round)
df3.to_csv(
"all_prefectures.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df3
#By gender and age
dt = dfs[1].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df4 = df_conv(
dfs[1].iloc[2:-1].reset_index(drop=True),
[
"age",
"population(Man)",
"population(woman)",
"population(Total)",
"Number of deliveries(Man)",
"Number of deliveries(woman)",
"Number of deliveries(Total)",
"Grant rate(Man)",
"Grant rate(woman)",
"Grant rate(Total)",
"Ratio of the number of grants to the whole(Man)",
"Ratio of the number of grants to the whole(woman)",
"Ratio of the number of grants to the whole(Total)",
],
population_date,
delivery_date,
)
df4["Grant rate(Man)"] = df4["Grant rate(Man)"].apply(my_round)
df4["Grant rate(woman)"] = df4["Grant rate(woman)"].apply(my_round)
df4["Grant rate(Total)"] = df4["Grant rate(Total)"].apply(my_round)
df4["Ratio of the number of grants to the whole(Man)"] = df4["Ratio of the number of grants to the whole(Man)"].apply(my_round)
df4["Ratio of the number of grants to the whole(woman)"] = df4["Ratio of the number of grants to the whole(woman)"].apply(my_round)
df4["Ratio of the number of grants to the whole(Total)"] = df4["Ratio of the number of grants to the whole(Total)"].apply(my_round)
df4.to_csv(
"demographics.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig",
)
df4
#By city
dt = dfs[0].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df5 = df_conv(
dfs[0].iloc[2:-1].reset_index(drop=True),
["Name of prefectures", "City name", "Total number (population)", "Number of deliveries", "人口に対するNumber of deliveries率"],
population_date,
delivery_date,
)
df5["Number of grants to the population"] = df5["Number of grants to the population"].apply(my_round)
df5["City name"] = df5["City name"].replace(r"\s", "", regex=True)
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Sasayama City, Hyogo Prefecture", "Tamba Sasayama City")
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Yusuhara Town, Takaoka District, Kochi Prefecture", "Yusuhara Town, Takaoka District")
df5["City name"] = df5["City name"].mask(df5["Name of prefectures"] + df5["City name"] == "Sue Town, Kasuya District, Fukuoka Prefecture", "Sue-cho, Kasuya-gun")
if pd.Timestamp(df5.iloc[0]["Calculation base date"]) < datetime.date(2018, 10, 1):
df5["City name"] = df5["City name"].mask(
df5["Name of prefectures"] + df5["City name"] == "Nakagawa City, Fukuoka Prefecture", "Nakagawa-cho, Chikushi-gun"
)
else:
df5["City name"] = df5["City name"].mask(
df5["Name of prefectures"] + df5["City name"] == "Nakagawa Town, Chikushi County, Fukuoka Prefecture", "Nakagawa City"
)
df_code = pd.read_csv(
"https://docs.google.com/spreadsheets/d/e/2PACX-1vSseDxB5f3nS-YQ1NOkuFKZ7rTNfPLHqTKaSag-qaK25EWLcSL0klbFBZm1b6JDKGtHTk6iMUxsXpxt/pub?gid=0&single=true&output=csv",
dtype={"Group code": int, "Name of prefectures": str, "County name": str, "City name": str},
)
df_code["City name"] = df_code["County name"].fillna("") + df_code["City name"]
df_code.drop("County name", axis=1, inplace=True)
df5 = pd.merge(df5, df_code, on=["Name of prefectures", "City name"], how="left")
df5["Group code"] = df5["Group code"].astype("Int64")
df5.to_csv(
"all_localgovs.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df5