[PYTHON] Search for technical blogs by machine learning focusing on "easiness to understand"
I want to acquire new technology! Even if you search for it, it is often the case that the articles that come to the top of the search are not "easy to understand". The number of views of the article, the number of likes and the number of Qiita's likes can be used as a reference, but it does not mean that it should be high as a feeling.
So, can we evaluate not only the "reputation" of these sentences, but also the composition and writing style of the sentences themselves, and evaluate their "easiness to understand"? So, what I tried experimentally is the following "Elephant Sense".
chakki-works/elephant_sense (It will be encouraging if you give me a Star m (_ _) m)

- The name comes from the story that the elephant's senses are actually amazing.
During the development, we followed the basic natural language processing / machine learning procedure, so I would like to introduce the process in this article.
goal
I tried to find out in advance how easy it is to understand the articles of Qiita by "simply searching" and "extracting those with a high number of likes" (at this time). "Easy to understand" was evaluated subjectively. In the following phases, I will explain how to handle this feeling). As a result, it was found that the situation is as follows.

It seemed that the situation did not reach 50% even if the likes were extracted based on the criteria, so the goal is to make half of them easy to understand.

Previous research
There are some previous studies on the evaluation of the comprehensibility of sentences. The following two indicators are famous in the English-speaking world ("Evaluation index for readability (1)) I'm familiar with the blog).
- Flesch Reading Ease
- Calculated using the number of words per sentence (sentence length) and the number of syllables per word
- Flesch-Kincaid Grade Level
- Uses the same features as Flesch Reading Ease, but the lower one is for upper grades (= difficult)
In other words, "a long sentence packed with many words is difficult to understand." On the contrary, if the sentence length is appropriate and the number of words used is small as a whole, the score will be good. By the way, MS Word can calculate this index. It may be a good idea to try it out.
The purpose of this index is mainly to measure the difficulty of texts such as whether a specific sentence is for elementary school students or high school students. There are the following research efforts in Japan.
- Nagaoka University of Technology Readability Research Lab
- Measuring the difficulty of Japanese textbooks, Sato / Matsuzaki Laboratory, Department of Electronic Information Systems, Graduate School of Engineering, Nagoya University
However, since nothing is assumed to be a textbook-like sentence, the score is greatly influenced by the ratio of educational kanji and hiragana included in the sentence, and it is written in standard notation like this technical blog. I have the impression that there is a limit to measuring and estimating the sentence level of existing texts (this point is "[About sentences that are easy for Japanese learners to read](https://www.ninjal.ac.jp/event/specialists] /project-meeting/files/JCLWorkshop_no2_papers/JCLWorkshop2012_2_34.pdf) ”).
As a close study, there was a study on measuring the comprehensibility of the following computer manuals.
Quantitative evaluation method for comprehensibility of computer manual
This research presents the following two viewpoints as the quality of expression in the manual.
- Accuracy of expression: Correctness of content, correctness of notation (grammatical error, etc.)
- Quality of expression: Easy to understand, easy to read, easy to use (searchability), concrete charts, appropriate examples, etc.
In terms of technical blogs, there are two points: "Is the content you are writing correct?" And "Is the writing style appropriate?" Similar to this study, this time we will focus on "quality of expression" (because external knowledge is required to determine whether the expression is accurate). As will be described later, we also referred to this research for the features to be used.
In addition, I briefly read the following papers as a study on the characteristics of sentences (refer to the latest NIPS / EMNLP).
- Document Summarization Using Sentence Features
- Extractive Summarization Using Supervised and Semi-supervised Learning
- Recognizing contextual polarity in phrase-level sentiment analysis
- Analyzing Linguistic Knowledge in Sequential Model of Sentence
Data preparation
I decided to use machine learning this time, so I need data anyway. Specifically, it is data that is annotated as "This article is easy to understand / difficult to understand".
In general, it is important to design the task well first when annotating.
NAIST Text Corpus Annotation Specification
This method is very well organized in the following books, so it's a good idea to read it once when annotating text data.
Natural Language Annotation for Machine Learning
This time, we decided to use "easy to understand" as the standard for "can juniors read it?" This is to prevent the annotator's knowledge from obscuring the clarity. And I decided to evaluate it on 0/1. This is because it was difficult to define the stage and only three people on the team could be mobilized for evaluation, so it was necessary to make it as stable as possible (I wrote it lightly, but this "easy to understand" There was a lot of debate about how to annotate).
In addition, I decided to take the target corpus from Qiita. In other words, this time, the purpose is to "evaluate whether or not Qiita articles can be read by juniors on 0/1" and predict the score to "increase the amount of articles that feel easy to understand to 50%". (According to the book above, it's important that the annotation work and the tasks you want to accomplish beyond that are well connected).
Annotation was done for 100 articles. However, if you randomly select the articles, most of the articles will have a small number of likes, so I adjusted that. The final annotation result is as follows (3 is MAX (all added 1) because it was done by 3 people).

We will build a model using this data.
Model building
If you are addicted to neural networks, it tends to be like Word2Vec encoding with RNN, but this time I decided to make a model that will be the baseline exactly.
The feature quantities selected as candidates with reference to previous research are as follows.
- Length Feature
- Sentence length (average / maximum / minimum)
- Heading length
- Section length
- Sentence length
- Counting Feature
- Number of words
- Word TF / IDF
- Hiragana / Katakana / Kanji / Alphabet / Number ratio
- Number of punctuation marks
- Number of line breaks
- Number of emphasized words (key bracket / double quotation pair)
- Number / ratio of bullet points (relative to the total number of sentences)
- Number / ratio of headlines (relative to the total number of sentences)
- Number of figures (image) / ratio (relative to the total number of sentences)
The image of features in natural language is basically divided into either "length" or "number". "Number" can be derived as "frequency (probability)" by adding a parameter, and "conditional probability" by adding preconditions.
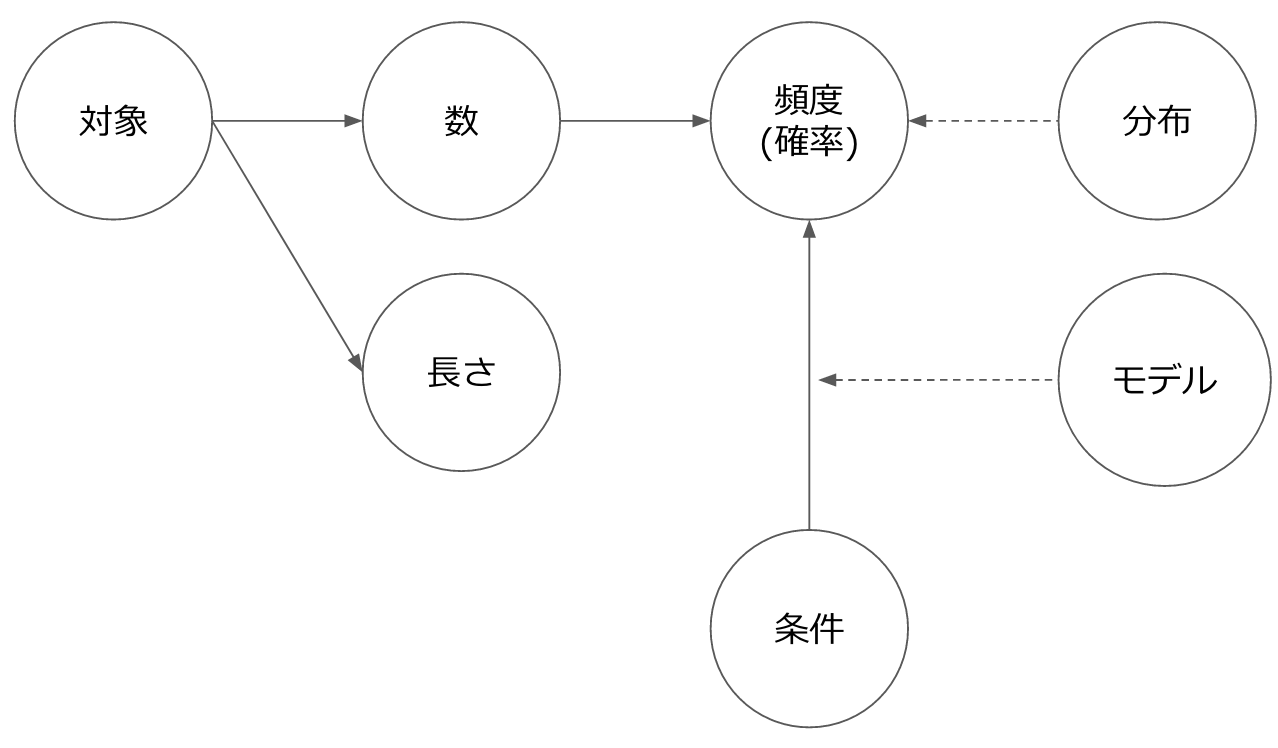
As for words, I did the pre-processing fairly carefully this time (@Hironsan should explain this area later).
I tried a test using the simple RandomForest using the listed features. (RandomForest is good because you can easily see the contribution of each feature).
Here is the result of actually building the model.
elephant_sense/notebooks/feature_test.ipynb

The dataset is small, but much more accurate. Looking at the features, the following seems to work well.
- image_count: number of figures
- sentence_max_length: Maximum sentence length
- user_followers_count: Number of followers of the user
It means, "It is written by a reliable person, it is written with an appropriate sentence length, and it contains a figure." Especially, the presence or absence of the figure was very effective. "Number of followers of users" is contrary to the purpose of this time, and it was a policy not to include it at the beginning because of Qiita's unique characteristics, but accuracy + information about "writer" when applying it to other sentences in the future I decided to put it in because it can be taken in some form.
In addition, the result of classifying only the likes to be compared this time is as follows.
elephant_sense/notebooks/like_based_classifier.ipynb

If you look at this, you can see that the "easy-to-understand" sentence (1) cannot be predicted. In that sense, this model seems to be more useful than I expected.
Embedded in the application
Let's create an application that can actually be used by incorporating the built model.
When embedding a machine learning model in an application, the object for normalization used in that model (this time StandardScaler Note that) is also required. If you used to normalize when you created the model, you naturally need to normalize when making predictions.
The front end is simple and built with Vue.js/axios. axios is a library for sending http requests, it can be used on the server side (Node), and it has solid client side support (especially XSRF cookie support was appreciated).
The resulting application was deployed to Heroku. Since we are using scikit-learn etc. this time, normal deployment is difficult, so we are deploying using Docker.
Container Registry and Runtime
Until now, I had to become a buildpack craftsman, so this is convenient (but it's a bit painful because it can't be used from a proxy environment).
The deployed application is as follows.
But ... slow! I'd really like to have more posts to evaluate, but I'm narrowing it down because of performance (currently I'm scoring and displaying 50 search results). I'm doing parallel processing for the time being, but after all I'm doing html parsing of each sentence and extracting the features, so it will be quite slow. I think that improvements are needed here, including ingenuity on the front end side.
As for the display result, I get the impression that it is OK. However, in order to reach 50% of the target, you still have to evaluate more sentences before displaying them, so there are two sides of the same coin with the above performance problem.
The meter tag is used to display the score. I learned about the existence for the first time in this development. Like the progress tag, there are some tags that I don't know.
from now on
I have the impression that I have gone through a series of processes such as problem setting, data collection, model construction, and application. If this evolves further, I think that it can be applied to design documents, API documents, etc. to improve the quality of documents, and to support new entrants to search for "well-organized" sentences. ..
Currently, my team chakki is working on machine learning / natural language processing for "a society where everyone can return by tea time (15:00)". We are trying to realize it by. First of all, we are currently working on natural language information (documents, reviews, source code, etc.) in system development.
 [@chakki_works](https://twitter.com/chakki_works)
[@chakki_works](https://twitter.com/chakki_works)
If you are interested, Please come and listen!
Recommended Posts