3. Natural language processing with Python 5-1. Concept of sentiment analysis [AFINN-111]
- There is a method to characterize a document as a group. Based on the attributes given to the words that make up the document, it makes a positive / negative judgment as to whether it likes or dislikes.
- It requires the original dictionary, but ** the English word emotion value dictionary AFINN-111 ** contains -4 to 4 emotion values for each of the 2,477 words. An integer is given.
⑴ Acquisition of AFINN-111
- Read AFINN-111 and set it as the data frame
afn.
import pandas as pd
afn = pd.read_csv(r'https://raw.githubusercontent.com/fnielsen/afinn/master/afinn/data/AFINN-111.txt',
names=['word_score'])
⑵ Convert AFINN-111 to dictionary type
- Separate the columns into the word
wordand the emotion valuescorewith "\ t" as the delimiter.
afn["split"] = afn["word_score"].str.split("\t")
afn["word"] = afn["split"].str.get(0)
afn["score"] = afn["split"].str.get(1)
- Since the value of
scoreis a string, generate the columnscore_intconverted to numeric type (INTEGER).
import numpy as np
afn_int = afn.assign(score_int = afn['score'].astype(np.int64))
- Extract the target two columns
wordandscore_intfrom the data frame, specify the key aswordinset_index ()and convert it to a dictionary withto_dict ().
afn_int = afn_int[["word", "score_int"]]
sentiment_dict = afn_int.set_index('word')['score_int'].to_dict()

(3) Calculation of emotional value by AFINN-111
- The following are the first three lines of Kenji Miyazawa's "Gauche the Cellist".
`Gauche was in charge of playing the cello at the activity photo studio in the town. He had a reputation for not being very good, though. He was always bullied by the conductor, not because he wasn't good at it, but because he was actually the worst of his fellow musicians. ``
- Translated into English as input data
string.- Gauche was in charge of playing the cello at the town's activity photo studio.
- He had a reputation for not being a very good player.
- Not only was he not a good player, but he was actually the worst player among his fellow musicians, so he was always bullied by the head musician.
string = "Gauche was in charge of playing the cello at the town's activity photo studio. He had a reputation for not being a very good player. Not only was he not a good player, but he was actually the worst player among his fellow musicians, so he was always bullied by the head musician."
- Import Python's natural language processing package NLTK and its submodule nltk.tokenize set and download the tokenizer punkt.
- Extract each sentence from
stringwithsent_tokenize ()and repeat the following process. Uselower ()to lowercase all letters, useword_tokenize ()to divide it into words, and usesentiment_dictto get the emotional value for each word, which is calledscore.
import nltk
from nltk.tokenize import *
nltk.download('punkt')
for s in sent_tokenize(string):
words = word_tokenize(s.lower())
score = sum(sentiment_dict.get(word, 0) for word in words)
print(score)
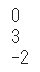
- ** If the score is a positive number, it means that the sentence is positive, and if it is a negative number, it means that the sentence has a negative character.
- "Gauche was in charge of playing the cello at the activity photo studio in the town" is an objective fact with 0 points.
- "But I had a good reputation that I wasn't very good at it" was 3 points, but I feel like I'm saying a negative meaning in a roundabout way.
- "I wasn't really good at it, but I was actually the worst of my fellow musicians, so I was always bullied by the conductor" was -2 points, which clearly has a negative meaning.
- Therefore, ** Calculate the total of positive emotion values and the total of negative emotion values separately **.
for s in sent_tokenize(string):
words = word_tokenize(s.lower())
positive = 0
negative = 0
for word in words:
score = sentiment_dict.get(word, 0)
if score > 0:
positive += score
if score < 0:
negative += score
print(s)
print("positive:", positive)
print("negative:", negative)

- What if you rephrase "not very good" in the second sentence to "not good"?
string_2 = "Gauche was in charge of playing the cello at the town's activity photo studio. But he had a reputation for being terrible at it. Not only was he not a good player, but he was actually the worst player among his fellow musicians, so he was always bullied by the head musician."
for s in sent_tokenize(string_2):
words = word_tokenize(s.lower())
positive = 0
negative = 0
for word in words:
score = sentiment_dict.get(word, 0)
if score > 0:
positive += score
if score < 0:
negative += score
print(s)
print("positive:", positive)
print("negative:", negative)

- There are differences between Japanese and English, but you can see that the results can be quite different depending on the wording.
⑷ Problems and precautions
- The above is the principle of sentiment analysis, but there are various problems such as the following.
- Words not in the dictionary are not counted.
- Even if there is a negatively qualified word such as "** not ** being a very ** good ** player" above, it is counted as a positive value.
- Similarly, even if there is a word that is amplified and modified, such as "not being a ** very good ** player", only "good" is counted.
- The longer the sentence, the larger the sum of emotional values.
- Emotions may differ between the first half and the second half of the sentence, so it is impossible to characterize them all at once.
- By the way, there are some English words that correspond to "cute" in Japanese, but in AFINN-111, they are "pretty: 1", "cute: 2", "lovely: 3" and so on. In other words, the emotional value is considered to correspond to the ** ordinal scale **, but the continuous value (-4, -3, -2, -1, 0, 1, 2, 3, 4), that is, the ** proportional scale ** Please note that it is treated as.
Recommended Posts