Abuse of reflection
Reflection and abuse of techniques that use reflection (eg, DI) make source code analysis difficult.
DI has the effect of weakening the coupling between classes and streamlining development and testing.
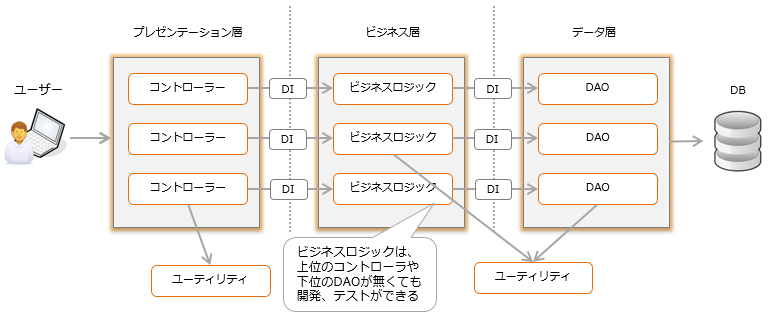
However, it is therefore difficult to look at dependencies. Even if you check the call hierarchy with an IDE such as Eclipse, you cannot detect calls by DI (reflection). To fix a bug and see if the fix affects other features, you need to check all callers. There is no problem if the implementation clearly shows the usage of DI, but if it is not, it will be difficult to identify the range of influence.
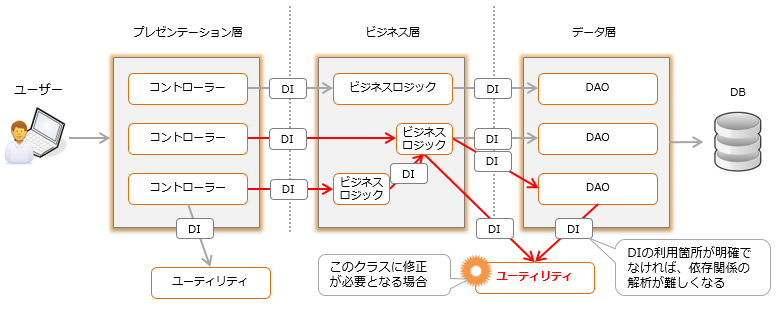
You can also use reflection to access private methods. I don't think any programmer will even consider calling by reflection to see the extent of the impact of modifying the logic of a private method. You wouldn't do a lot of time-consuming research, thinking that there couldn't be such tricky code. Writing tricky code can create risks.
Annotation abuse
Annotations are much like introducing a new grammar, with learning costs. It may be effective in improving productivity, but from the standpoint of maintainability, it's not all good.
The following code uses a library called Lombok to annotate and
public class Person {
private String firstName;
private String familyName;
public Person(String firstName, String lastName){
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFamilyName() {
return familyName;
}
public void setFamilyName(String familyName) {
this.familyName = familyName;
}
@Override
public String toString() {
return "Person(firstName=" + firstName + ", familyName=" + familyName + ")";
}
}
It can be simplified like this.
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
@ToString
@AllArgsConstructor
@Data
public class Person
{
private String lastName;
private String firstName;
}
There are no getters, setters, or toString methods in the source code, but they do exist. It's certainly easier to see, and I think it's harder to create bugs due to boring copy-paste mistakes. If you need a lot of these objects for large-scale development, Lombok will be a solution to improve your development productivity.
However, the latter is not immediately understandable to programmers without Lombok knowledge. On the other hand, no Java programmer can't read the former code.
In addition, the processing that annotations take on is often difficult to debug. If you want to set a breakpoint on getFirstName (), many people don't know what to do with the latter. Depending on the IDE, you can't just stop toString () in debug mode or see the implementation oftoString ()without using delombok.
Modern frameworks and libraries often add their own annotations, and using them in combination suffers from "annotation hell".
@PreAuthorize("#user.id == #u?.id")
public UserDTO access(@P("user") @Current UserEntity requestUser,
@P("u") @PathVariable("user-id") UserEntity user)
@PreAuthorize("#user.id == #uid && (#order == null || #order?.user?.id == #uid)")
public Message access(@Current @P("user") UserEntity user,
@PathVariable("user-id") @P("uid") Long uid,
@PathVariable("order-id") @P("order") OrderEntity order)
I don't think it's good to easily create your own annotations.
Abuse of other "black magic"
There are many tricky techniques besides reflection and annotation. Among them, it is best to avoid using a technique called "black magic" as much as possible.
For example, you can use sun.misc.Unsafe to rewrite a static final class field. With Javassist, you can directly rewrite the bytecode of a compiled class to change its behavior at run time. Black magic can be an effective tool when there is no other way to achieve it, or when there is a certain scale, but it should not be used unnecessarily.
Cache abuse
Caches are used in various parts of software because they help reduce processing time. However, it can also be a nuisance when analyzing. Since the behavior may differ depending on the cache state, it may appear that the behavior is not regular at the time of analysis. For example, data updates may not be immediately reflected on the screen, or the presence or absence of DB access errors may change.
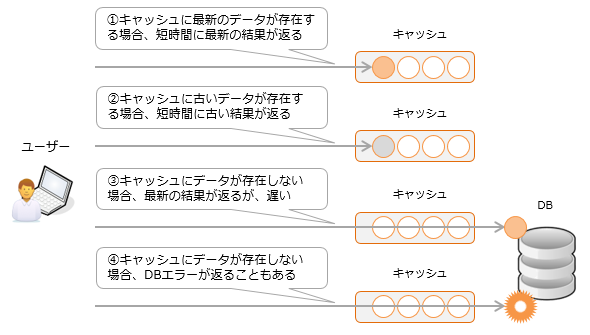
It can also be a factor in creating complex bugs such as memory leaks, so you may want to consider options such as disabling the cache when deploying.
Abuse of technology
If the programmer has mastered Java, he can implement Java applications. Furthermore, if you have mastered Servlet / JSP, you can build a Web application. If you have mastered Spring Boot, you can increase your development productivity. If you have mastered Thymeleaf and Bootstrap, you can separate design and logic and improve the quality and readability of your design. If you have mastered SAML 2.0 and Sprig Security, you can delegate authentication to an external system. If you are familiar with JUnit and Gradle, you can automate testing and building. There are many other things that can be achieved by learning.
However, the programmers who can do all of them are limited. Different people have different standards of readability, but the more technology you work with, the fewer programmers can read all of that code. If you increase the number of technologies you handle in the dark clouds, the overall readability will decrease. Even if you partially rewrite the implementation in another language or technology because it can be written more concisely, if fewer programmers can handle it, the readability will decrease and the analysis time will increase.
Liar comments, Javadoc, logs
I think many people don't think about comments and Javadoc as much as the source code (as I do ...).
In spite of the following description, the fact that there is a class introduced from version 3.0.0 breaks the prerequisites for investigation and causes confusion.
/**
* ...
* @since 2.0.1
*/
It's better not to write anything than to write incorrect comments, Javadoc. You can see it by looking at the history in your version control system, so it may be safer not to use something that has the potential for incorrect double management, such as @ since.
There are other things that are at high risk of telling lies. By copying and pasting the field variable Logger, it is easy to implement the following code whose class name and actual class are different.
public class DeleteController {
private static final Logger log = LoggerFactory.getLogger(ImportController.class);
The logs output by this logger can be confusing. You may want to grep and check the entire source code before releasing it to production.
Splitting key values
The problem when investigating is the implementation that divides a part of the property key defined in the properties file into constants. For example, suppose the following properties are defined:
account.lockout.count=10
account.lockout.interval=60000
If you write the following code to get this,
private static final String ACCOUNT_LOCK_PREFIX = "account.lockout.";
...
private void doSomething() {
ResourceBundle rb = ResourceBundle.getBundle("application");
String count = rb.getString(ACCOUNT_LOCK_PREFIX + "count");
String interval = rb.getString(ACCOUNT_LOCK_PREFIX + "interval");
Even if I grep all the source code with the property key "ʻaccount.lockout.count", it will not be hit. Based on the result, if you decide that this property is not used and remove this key from the properties file, you will get a MissingResourceException` at runtime. We recommend that you do not split the key strings.
Useless log
It is necessary to consider error log messages as well as property keys. The message should be such that you can grep the source code to identify where it is used. If there are multiple identical log messages, the location where they were output cannot be identified. It would be nice if the output format setting of the log library was to output the file name and the number of lines of the source code to the log, but in consideration of performance (or because the default has not been reviewed), that is not the case. There are also many.
For example, the following log output processing
log.warn("{} not found", data.getId());
If possible, it is better to divide it into the following two so that the output location can be easily identified.
log.warn("User does not exist in user table: {}", user.getId());
When
log.warn("Group does not exist in group table: {}", group.getId());
There are many other things to consider about log output. An implementation that catches an exception and doesn't take advantage of it will hide the problem.
} catch (Exception e) {
}
It will be easier to analyze the source code if the logs that are useful for investigation are output at the appropriate log level and at the appropriate timing.
Furthermore, for web applications, it would be very useful to have the ability to change the log level without rebooting. The software I work with, called OpenAM, has this feature that allows you to change the log level in a web application for administrators. Even if a problem occurs in the production environment, you can temporarily raise the log level and then reproduce the event to acquire the log. Once you have obtained it, you can restore the log level.
OpenAM also has a REST API for troubleshooting. When you send a request to a specific URL, the system configuration file, debug log for a certain period of time, thread dump, etc. are compressed into a zip file and output. Creating a function for analysis in this way will be a great help during operation.
How the settings determine the behavior
When developing a framework, it is often difficult to follow the behavior if you create a mechanism in which settings such as XML files and Java Config determine the behavior.
Recently (in a bad way) I've been addicted to setting Spring Security access control (authentication, authorization, session management, CSRF measures, etc.). If you write the following code, it will control access based on the contents, but if you try to realize a little complicated thing, it will not go as you expected.
@Override
protected void configure(HttpSecurity http) throws Exception {
http.antMatcher("/admins/**").authorizeRequests().antMatchers("/admins/login").permitAll()
.antMatchers("/admins/**").authenticated().and().formLogin().loginProcessingUrl("/admins/login")
.loginPage("/admins/login").failureUrl("/admins/login?error").defaultSuccessUrl("/admins/main")
.usernameParameter("username").passwordParameter("password").and().logout().logoutUrl("/logout")
.logoutSuccessUrl("/").deleteCookies("JSESSIONID").and().sessionManagement().sessionFixation()
.none().and().csrf();
}
Although it was "a little complicated", it was a level that could be easily implemented by adding logic to the Servlet filter, but when trying to incorporate that logic into the rules of Spring Security, what kind of settings would be made? I can't decide what kind of class or method should be implemented.
You can also debug your own Servlet filter to quickly identify where the problem is, but debugging Spring Security's generic logic is not easy. If you request an implementation or setting that cannot be debugged at runtime like the configure () method above, it will be difficult to analyze.
If you create a new mechanism that can realize complicated things only by setting, you have to assume various patterns and make the developer aware of why it does not work. It should also be taken into consideration that the learning cost of developers for how to use it will increase.
Pursuit of excessive shortness
Although it was written in the readable code, the source code is not easy to read if it is shortened. It's not surprising considering that the following source code for competing in code golf is by no means easy to read.
class G{static public void main(String[]b){for(int i=0;i<100;System.out.println((++i%3<1?"Fizz":"")+(i%5<1?"Buzz":i%3<1?"":i)));}}
You can't even set breakpoints with this. I think it's better to write verbose code than to use techniques to shorten it. I even feel that the stereotype of "short code = easy-to-read code" is a factor in creating code that is difficult to analyze.
New grammar
Lambda expressions have been added in Java 8, but there are many cases where they are also difficult to debug. For example, the following for statement
for (String n : notifications) {
System.out.println(n);
}
In Java8 you can also write:
descriptions.forEach(n -> System.out.println(n));
In this for statement, if you want to stop the loop only when the length of the string n exceeds 100, set the following conditional breakpoints.
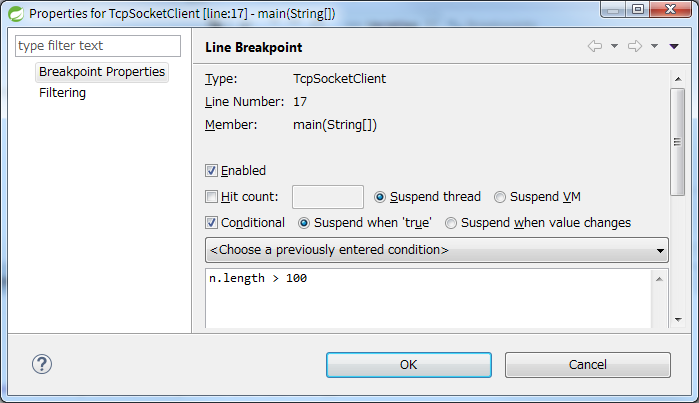
If you set a conditional breakpoint on the former line System.out.println (n);, the program will pause under that condition, but if you set a breakpoint on the latter, then I get an error like (* I am using STS 3.8.4).
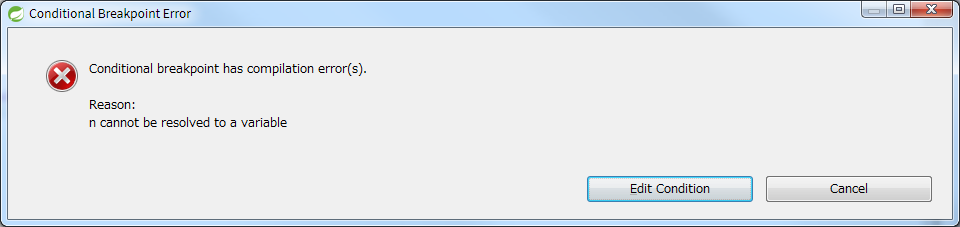
It would be nice if the IDE supported all the latest grammars, but that's not always the case. Sometimes you can't debug unless you write a one-line lambda expression in three lines. If you implement it with a new grammar, you may need to set breakpoints once and see how it works.
Method chain
Method Chaining like person.setName ("Peter"). SetAge (21) ..., which is often seen in recent source code, is also hard to say in analysis.
class Person {
private String name;
private int age;
// In addition to having the side-effect of setting the attributes in question,
// the setters return "this" (the current Person object) to allow for further chained method calls.
public Person setName(String name) {
this.name = name;
return this;
}
public Person setAge(int age) {
this.age = age;
return this;
}
public void introduce() {
System.out.println("Hello, my name is " + name + " and I am " + age + " years old.");
}
// Usage:
public static void main(String[] args) {
Person person = new Person();
// Output: Hello, my name is Peter and I am 21 years old.
person.setName("Peter").setAge(21).introduce();
}
}
It doesn't seem intuitive from an object-oriented point of view that setter returns its own instance. The readability of method chains may vary from person to person, but given the ease of debugging, it's hard to say. In this line
person.setName("Peter").setAge(21).introduce();
You can't pause the program where you need it because you can't set breakpoints at the right points. Also, if one of these methods throws an exception, the line numbers will all be the same, so I don't know which method caused the problem.
Exception in thread "main" java.lang.NullPointerException
at tdd.Person.main(Person.java:27)
If this is divided as follows,
person.setName("Peter"); //27th line
person.setAge(21); //Line 28
person.introduce(); //29th line
You can tell which method is the problem just by looking at the stack trace.
Exception in thread "main" java.lang.NullPointerException
at tdd.Person.main(Person.java:29)
Mechanism that is difficult to debug and difficult to reflect corrections
In the Web application that was developed several years ago, the framework analyzed the XML file output by the tool using the Excel screen specifications as input, and the screen was generated.

Although it is possible to unify and homogenize the screen design in this way, it was very troublesome to analyze when the layout and operation were not as expected.
Of course, neither Excel screen specifications nor XML files can be debugged. Breakpoints can be set in the source code of the framework that parses the XML. It takes time to debug the framework source code and to repeat the trial and error of specification changes. Not only that, it also takes time to modify, output, deploy, and verify the XML. Even with Tomcat autoreload enabled, this took a while ...
Development with the recent trend of Spring Boot and Thymeleaf does not require (though not at all) restarting the container after modifying the screen or logic. Thymeleaf can reflect the modification immediately if it does not cache the template HTML file. If you use JRebel, Spring Loaded, etc., you can immediately reflect and check the correction of Java source code.
If you create a mechanism that is difficult to debug and difficult to reflect corrections, it will result in a large time loss in the subsequent work.
Time-consuming startup process
I think that the initialization process of a Web application that runs in a container such as Tomcat is often performed at startup. For example, the DB connection pool is created at this timing, but it does not necessarily have to be done at startup. Even if you do it in the background when you access the DB for the first time or after starting it, it is not necessarily slow. Not only in the development process, but also in operation and troubleshooting, the container will be restarted many times. Even if one startup time increases by a few seconds, the time of (increased number of seconds) x (number of developers) x (number of reboots) is wasted.
At one site, there was a web application that took 5 minutes to start Tomcat, and no one had any doubts about it and was developing it. I thought this was strange, and when I investigated the cause of the delay, one process accounted for about 90% of the initialization processing time, and by improving this, the startup time was improved to about 20 seconds. If the container startup time differs significantly depending on whether or not you deploy the web application, you may want to review the contents of the web application initialization process once.
Summary
I wrote a lot as I came up with, so it's not very organized, but there are a lot of other code that's hard to parse and debug. To prevent this from happening, I think you should be aware of the following points.
--In addition to writing easy-to-read code, code by considering whether it is easy to debug or analyze.
--Try to actually run it in the IDE to see if it can be debugged and if it is easy to debug.
--Always keep in mind that log and comment messages are useful for analysis
--Thorough consideration when introducing tricky technologies and new rules
--Do not run into technique
――I don't care about writing short
--Do not create a mechanism that is difficult or time consuming to debug and analyze
In the end, I said something great, but I'm not writing such code ...: bow: