Visualisieren Sie Ihre Taschengelddateien mit Dash, dem Python-Webframework
Vorwort
Oft ist eine schnelle Visualisierung Ihrer Dateien erforderlich. In einer so schnellen Umgebung können auch Nicht-Programmierer die Daten verwenden, und die Welt der unbegründeten Intuition und des Mutes kann auf der Grundlage von Daten in die Welt der Intuition und des Mutes verwandelt werden.
Dieses Mal habe ich als bekanntes Beispiel eine (pic1) Dash-Anwendung erstellt, mit der die folgenden verbundenen Taschengelddateien hochgeladen werden können. Die Datumsspalte enthält das Datum, die Variablenspalte enthält den Ausgabenposten und die Wertespalte enthält den Betrag. Leider habe ich kein Taschenbuch, daher verwende ich japanische Haushaltsumfragedaten.

Die endgültige Anwendung, die Sie erstellt haben, sieht folgendermaßen aus: Sie können eine Datei auswählen, indem Sie auf das Tool zum Hochladen von Dateien klicken. Wenn es sich um Taschengelddaten mit den oben genannten drei Elementen handelt, wird ein Diagramm erstellt, und Sie können das Element auch auswählen und zeichnen.
Sie müssen viel Code schreiben, um so etwas zu machen! Das könnte man denken. Die Codelänge der Anwendung selbst beträgt jedoch 92 Zeilen, die mit Schwarz formatiert sind.
URL der eigentlichen App: https://okodukai.herokuapp.com/ (Der Start dauert etwas, da sie kostenlos ausgeführt wird.) Verwendete Datei: https://github.com/mazarimono/okodukai_upload/blob/master/data/kakei_chosa_long.csv
Erstellungsumgebung
Die Erstellungsumgebung ist wie folgt.
Windows10 Python 3.8.3 dash 1.13.4 plotly 4.8.2 pandas 1.0.4
Wie man ... macht
Lesen Sie den vorherigen Artikel zum Erstellen einer Dash-Anwendung.
https://qiita.com/OgawaHideyuki/items/6df65fbbc688f52eb82c
Dash selbst ist ein Paket wie der Python-Wrapper von React. Eine seiner Funktionen besteht darin, dass es einfach ist, Daten mithilfe eines Diagrammpakets namens Plotly zu visualisieren.
Kombinieren Sie die Komponenten, um ein Layout zu erstellen, und verwenden Sie Rückrufe, damit diese Komponenten interaktiv funktionieren.
Wichtige Komponenten in dieser Anwendung
Es gibt zwei wichtige Punkte in der Taschengeld-Upload-App.
- Wo können Dateien hochgeladen werden? --Vorratsdatenspeicherung
Dies nutzt die Upload- bzw. Store-Komponenten.
Komponente hochladen
Die Upload-Komponente ist eine Komponente zum Hochladen von Dateien und wird in der Anwendung wie folgt angezeigt.

Der Code sieht folgendermaßen aus:
upload.py
dcc.Upload(
id="my_okodukai",
children=html.Div(["Taschengelddatei", html.A("Bitte benutzen Sie CSV oder Excel!")]),
style=upload_style,
),
Komponente speichern
Die Store-Komponente wird nicht im Layout angezeigt, sondern dient zum Speichern der hochgeladenen Daten. Wenn die Anwendung eine Datei hochlädt, wird sie an die Store-Komponente übergeben, die abgerufen wird, um die Auswahl der Anzeigeelemente in der Dropdown-Liste zu aktualisieren, und das Diagramm wird aktualisiert.
** Wenn die App startet **

** Laden Sie die Datei hoch **

Rückrufen
Rückrufe verbinden jede Komponente und sorgen dafür, dass jede dynamisch funktioniert. Im Fall dieser App werden wir die folgenden zwei Rückrufe verwenden.
--Wenn es sich bei den in die Upload-Komponente hochgeladenen Daten um eine CSV- oder Excel-Datei handelt, handelt es sich um einen Datenrahmen. Nutzen Sie es, um Dropdown-Optionen zu erstellen. Dann hinterlegen Sie die Daten in der Store-Komponente (1)
- Erstellen Sie mit den aus der Store-Komponente gelesenen Daten die Daten gemäß der Dropdown-Auswahl und zeichnen Sie sie in das Diagramm (2).
Der Rückrufcode für (1) lautet wie folgt. verhindere_initial_call verhindert, dass der Rückruf beim Start ausgelöst wird. Dies löst diesen Rückruf nur aus, wenn die Datei hochgeladen wird.
@app.callback(
[
Output("my_dropdown", "options"),
Output("my_dropdown", "value"),
Output("tin_man", "data"),
],
[Input("my_okodukai", "contents")],
[State("my_okodukai", "filename")],
prevent_initial_call=True,
)
def update_dropdown(contents, filename):
df = parse_content(contents, filename)
options = [{"label": name, "value": name} for name in df["variable"].unique()]
select_value = df["variable"].unique()[0]
df_dict = df.to_dict("records")
return options, [select_value], df_dict
Die Funktion parse_content sieht folgendermaßen aus: Kurz gesagt, wenn der Dateiname mit .csv endet, wird er als CSV-Datei gelesen, und wenn xls enthalten ist, wird er als Excel-Datei gelesen. Es wird nur utf-8 unterstützt. Es scheint auch, dass die Excel-Datei xls und xlsx enthält, also habe ich es so gemacht.
def parse_content(contents, filename):
content_type, content_string = contents.split(",")
decoded = base64.b64decode(content_string)
try:
if filename.endswith(".csv"):
df = pd.read_csv(io.StringIO(decoded.decode("utf-8")))
elif "xls" in filename:
df = pd.read_excel(io.BytesIO(decoded))
except Exception as e:
print(e)
return html.Div(["Beim Lesen der Datei ist ein Fehler aufgetreten"])
return df
Der Rückruf von (2) ist wie folgt. Dies verhindert auch, dass der Rückruf beim Starten der App ausgelöst wird. Wenn das Dropdown-Menü aktualisiert wird, werden die Daten aufgerufen und das Diagramm aktualisiert.
@app.callback(
Output("my_okodukai_graph", "figure"),
[Input("my_dropdown", "value")],
[State("tin_man", "data")],
prevent_initial_call=True,
)
def update_graph(selected_values, data):
df = pd.DataFrame(data)
df_selected = df[df["variable"].isin(selected_values)]
return px.line(df_selected, x="date", y="value", color="variable")
Schauen Sie sich eine kleine japanische Haushaltsumfrage an
Es könnte so enden, also schauen wir uns die japanische Haushaltsumfrage an. Derzeit sind die Daten bis Mai.
Erstens ging der Konsum, der den Gesamtverbrauch darstellt, im April und Mai stark zurück.

Nein, als ich den Konsum von Milch ermutigte, sah ich, dass es effektiv war, danke, aber als ich mir ansah, wie es war, schien es wahr zu sein. Ich ging zurück in meine Kindheit und trank viel Milch. Milch ohne Alkohol! !! !!

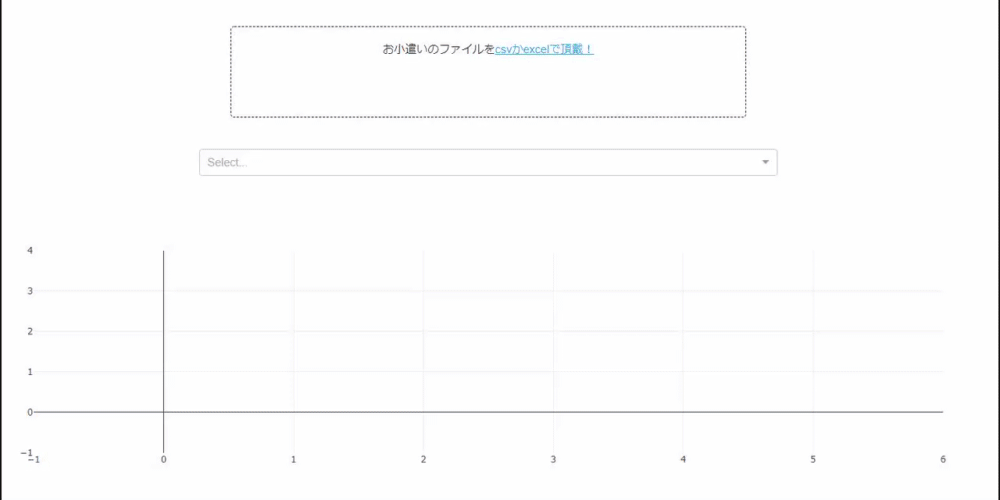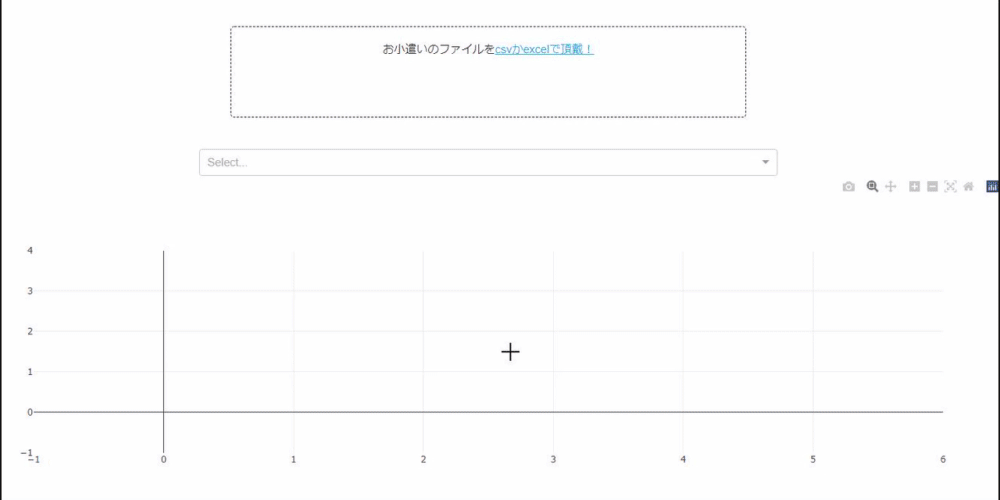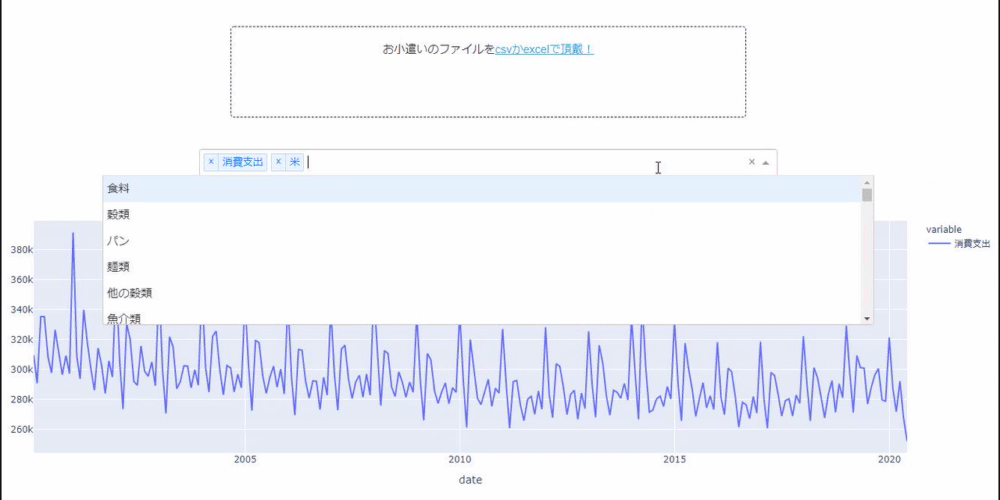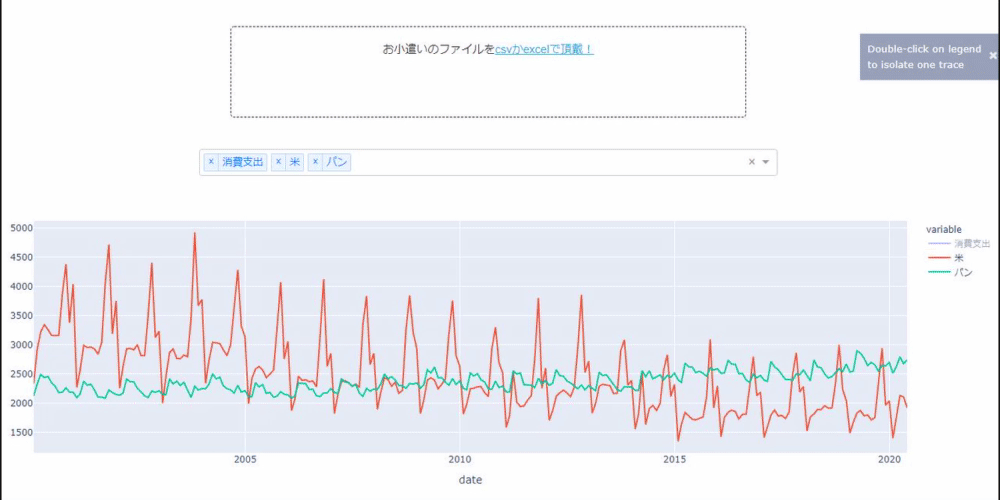
Wenn Sie interessante Tendenzen zu Corona haben, würde ich mich freuen, wenn Sie dies in den Kommentaren belassen könnten. Es ist etwas langsam, wahrscheinlich weil es ein freier Frame ist, aber bitte haben Sie etwas Geduld. Ich interessierte mich für Reis oder Brot, für das ich Geld ausgab. Ich bin definitiv Amerikaner, aber meine Töchter essen nur Brot. Ich habe mich gefragt, warum ...

Es scheint, dass ich derjenige war, der zurückgelassen wurde. Es gibt mehr Fisch und Fleisch wie dieses, aber ich verstehe dieses Gefühl, weil ich eine Fleischsekte bin.
Zusammenfassung
Mit dem oben genannten Gefühl können Sie ganz einfach ein Tool erstellen, das die vorhandenen Standarddateien sofort visualisiert. Es gibt eine Anforderung, in der Lage zu sein, mehr verschiedene Dinge zu handhaben, aber ich frage mich, ob es notwendig ist, aus Sicht der Datenspeicherung einen Schnitt vorzunehmen.
DX dein eigenes Leben! !! Ist es so
Anwendungs-URL: https://okodukai.herokuapp.com/ github: https://github.com/mazarimono/okodukai_upload
Der Code auf github ist das, was app_heroku.py Herok gibt.
Anwendungscode
app.py
import base64
import io
import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
import plotly.express as px
from dash.dependencies import Input, Output, State
upload_style = {
"width": "50%",
"height": "120px",
"lineHeight": "60px",
"borderWidth": "1px",
"borderStyle": "dashed",
"borderRadius": "5px",
"textAlign": "center",
"margin": "10px",
"margin": "3% auto",
}
external_stylesheets = ["https://codepen.io/chriddyp/pen/bWLwgP.css"]
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.config.suppress_callback_exceptions = True
app.layout = html.Div(
[
dcc.Upload(
id="my_okodukai",
children=html.Div(["Taschengelddatei", html.A("Bitte benutzen Sie CSV oder Excel!")]),
style=upload_style,
),
dcc.Dropdown(
id="my_dropdown", multi=True, style={"width": "75%", "margin": "auto"}
),
dcc.Graph(id="my_okodukai_graph"),
dcc.Store(id="tin_man", storage_type="memory"),
]
)
def parse_content(contents, filename):
content_type, content_string = contents.split(",")
decoded = base64.b64decode(content_string)
try:
if filename.endswith(".csv"):
df = pd.read_csv(io.StringIO(decoded.decode("utf-8")))
elif "xls" in filename:
df = pd.read_excel(io.BytesIO(decoded))
except Exception as e:
print(e)
return html.Div(["Beim Lesen der Datei ist ein Fehler aufgetreten"])
return df
@app.callback(
[
Output("my_dropdown", "options"),
Output("my_dropdown", "value"),
Output("tin_man", "data"),
],
[Input("my_okodukai", "contents")],
[State("my_okodukai", "filename")],
prevent_initial_call=True,
)
def update_dropdown(contents, filename):
df = parse_content(contents, filename)
options = [{"label": name, "value": name} for name in df["variable"].unique()]
select_value = df["variable"].unique()[0]
df_dict = df.to_dict("records")
return options, [select_value], df_dict
Recommended Posts