[PYTHON] Schauen Sie sich das Kaggle / Titanic-Tutorial genauer an
Einführung
Ich habe Tutorial von Kaggles Titanic ausprobiert. Zufällig durch Kopieren und Einfügen Ich konnte mithilfe des Waldes Vorhersagen treffen, aber bevor ich mit dem nächsten Schritt fortfuhr, überprüfte ich, was ich im Tutorial tat. Sie können viele Titanic-Kommentare von Kaggle im Internet finden, aber hier ist eine Zusammenfassung dessen, was ich zusammen mit dem Tutorial gedacht habe.
Überprüfen Sie die Daten
head()
Verwenden Sie in Tutorial nach dem Lesen der Daten head (), um die Daten zu überprüfen.
train_data.head()

test_data.head()

Natürlich hat test_data keinen Survived-Begriff.
describe() Sie können die Statistik der Daten mit "beschreiben ()" anzeigen. Sie können die Objektdaten mit "beschreiben (include =" O ")" anzeigen.
train_data.describe()
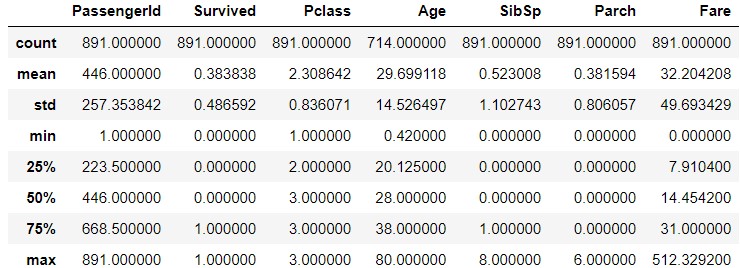
train_data.describe(inlude='O')
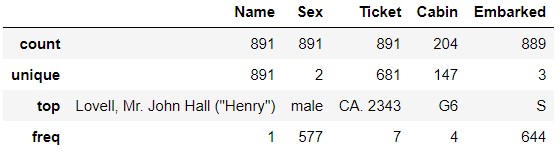
Wenn Sie sich "Ticket" ansehen, sehen Sie, dass "CA.2343" sieben Mal vorkommt. Bedeutet dies, dass Sie ein Familienmitglied oder etwas anderes sind und ein Ticket mit derselben Nummer haben? Ähnlich wie in "Kabine" G6` ist viermal aufgetaucht. Bedeutet das, dass sich vier Personen im selben Raum befinden? Ich bin gespannt, ob dieselbe Familie und dieselben Personen im selben Raum ihr Schicksal geteilt haben.
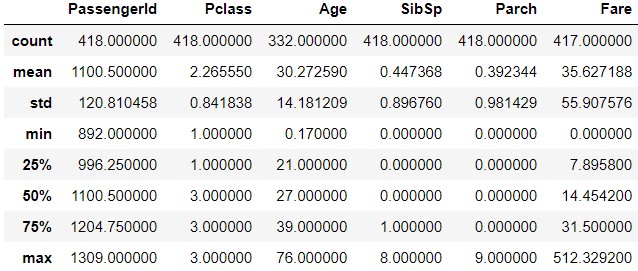
test_data.describe()
test_data.describe(include='O')
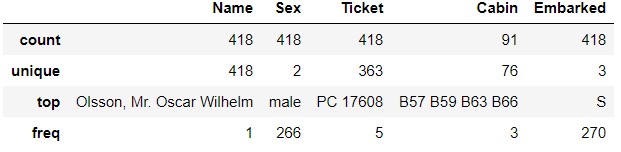 Auf der Seite "test_data" erscheint "PC 17608" fünfmal in "Ticket". "B57 B59 B63 B66" erscheint dreimal in "Cabin".
Auf der Seite "test_data" erscheint "PC 17608" fünfmal in "Ticket". "B57 B59 B63 B66" erscheint dreimal in "Cabin".
info()
Sie können Dateninformationen auch mit "info ()" abrufen.
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Sie können sehen, dass die Anzahl der Datenzeilen 891 beträgt, aber nur 714 für "Alter", 204 für "Kabine" und 889 für "Eingeschifft" (sorry!).
test_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
In "test_data" sind die fehlenden Daten "Age", "Fare", "Cabin". In "train_data" fehlten Daten in "Embarked", aber in "test_data" sind sie vollständig. , Fare wurde in train_data ausgerichtet, aber einer fehlt in test_data.
corr (); Siehe Datenkorrelation
Sie können die Korrelation der einzelnen Daten mit `corr () überprüfen.
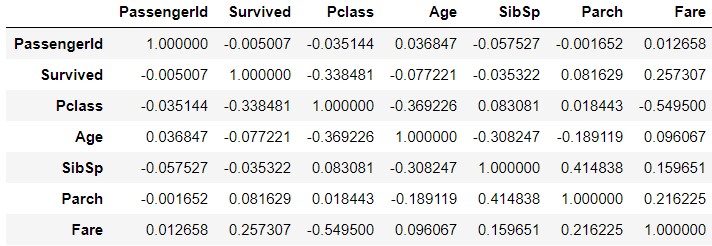
train_corr = train_data.corr()
train_corr
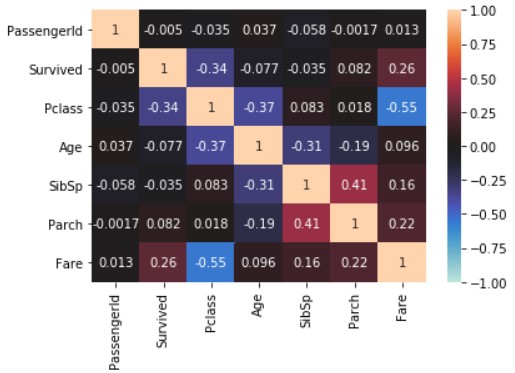
Visualisiere mit seaborn.
import seaborn
import matplotlib.pyplot as plt
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
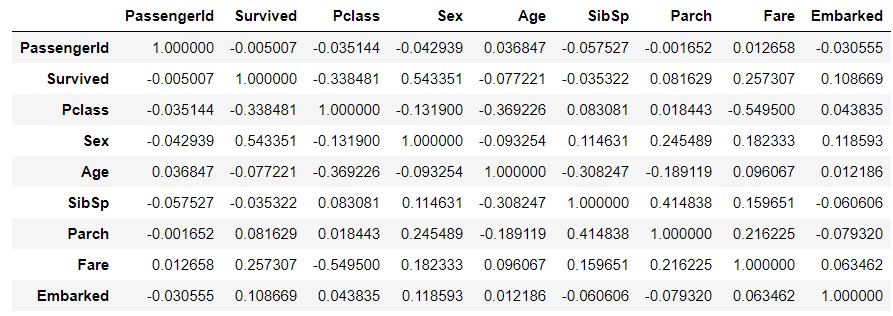
Das Obige spiegelt nicht die Objekttypdaten wider. Ersetzen Sie daher die Symbole "Geschlecht" und "Eingeschifft" durch Zahlen und machen Sie dasselbe. Wenn Sie die Daten kopieren, geben Sie ausdrücklich "copy ()" an. Erstellen Sie weitere Daten mit `.
train_data_map = train_data.copy()
train_data_map['Sex'] = train_data_map['Sex'].map({'male' : 0, 'female' : 1})
train_data_map['Embarked'] = train_data_map['Embarked'].map({'S' : 0, 'C' : 1, 'Q' : 2})
train_data_map_corr = train_data_map.corr()
train_data_map_corr
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
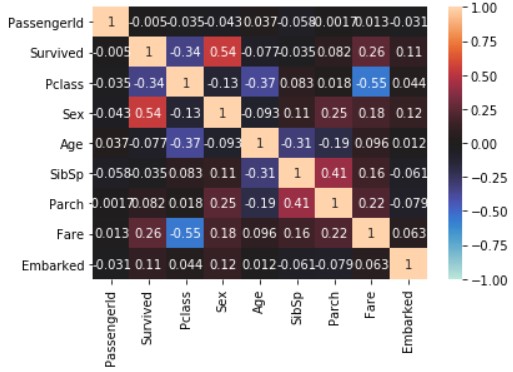
Konzentrieren Sie sich auf die Linie "Survived". Im Tutorial haben wir mit "Pclass", "Sex", "SibSp", "Parch" gelernt, aber "Age", "Fare" und "Embarked" sind auch mit "Survived". Hohe Korrelation.
Lernen
get_dummies()
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
Lernen Sie mit scikit-learn. Es gibt vier Funktionsgrößen, die in "Features" definiert sind: "Pclass", "Sex", "SibSp" und "Parch" (Features ohne Fehler). ..
Die für das Training verwendeten Daten werden von pd.get_dummies verarbeitet . Pd.get_dummies konvertiert hier die Objekttypvariable in eine Dummy-Variable.
train_data[features].head()
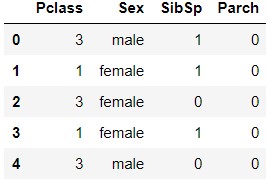
X.head()
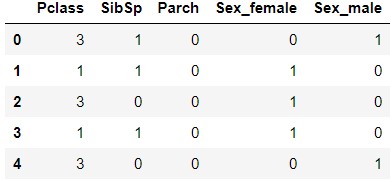
Sie können sehen, dass sich die Feature-Menge "Sex" in "Sex_female" und "Sex_male" geändert hat.
RandomForestClassfier()
Lernen Sie mit dem Random Forest-Algorithmus RandomForestClassifier ().
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
Überprüfen Sie die Parameter von RandomForestClassifier (die Beschreibung ist ungefähr)
| Parameter | Erläuterung |
|---|---|
| n_estimators | Anzahl der ermittelten Bäume.Der Standardwert ist 10 |
| max_depth | Maximalwert der Tiefe des ermittelten Baumes.Der Standardwert ist Keine(Vertiefen, bis es vollständig getrennt ist) |
| max_features | Für eine optimale Aufteilung,Wie viele Funktionen müssen berücksichtigt werden?.Der Standardwert istautodamit, n_featuresWerde die Quadratwurzel von |
Obwohl es nur 4 Features (5 Dummy-Variablen) gibt, scheint es übertrieben, 100 Entscheidungsbäume zu erstellen. Dies wird zu einem späteren Zeitpunkt überprüft.
Überprüfen Sie das erhaltene Modell
score
print('Train score: {}'.format(model.score(X, y)))
Train score: 0.8159371492704826
Das Modell selbst passt auf 0,8159 (nicht so teuer).
feature_importances_ Überprüfen Sie die Wichtigkeit der Merkmalsmenge (notieren Sie sich die Stelle, an der der Plural s angehängt ist).
x_importance = pd.Series(data=model.feature_importances_, index=X.columns)
x_importance.sort_values(ascending=False).plot.bar()
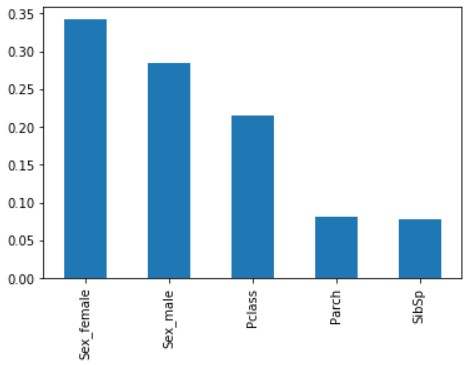
"Sex" ("Sex_female" und "Sex_male") sind von hoher Bedeutung, gefolgt von "Pclass". "Parch" und "SibSp" sind ebenso niedrig.
Anzeige des Entscheidungsbaums (dtreeviz)
Visualisieren Sie, welche Art von Entscheidungsbaum erstellt wurde. Es gibt verschiedene Mittel, aber hier verwenden wir dtreeviz.
Installation
Nehmen wir Windows10 / Anaconda3 an. Verwenden Sie zuerst pip und conda, um die erforderliche Software zu installieren.
> pip install dtreeviz
> conda install graphviz
In meinem Fall wurde der Fehler "Kann nicht schreiben" mit "conda" angezeigt. Starten Sie Anaconda im Admin-Modus neu (klicken Sie mit der rechten Maustaste auf Anaconda und wählen Sie "*** Im Admin-Modus starten ***"). Auswählen und starten), conda ausführen.
Fügen Sie danach den Ordner mit "dot.exe" zu "PATH" in der Systemumgebung hinzu.
> dot -V
dot - graphviz version 2.38.0 (20140413.2041)
Wenn Sie dot.exe wie oben ausführen können, ist es OK.
Anzeige des Entscheidungsbaums
from dtreeviz.trees import dtreeviz
viz = dtreeviz(model.estimators_[0], X, y, target_name='Survived', feature_names=X.columns, class_names=['Not survived', 'Survived'])
viz

Ich bin süchtig nach *** im Argument von dtreeviz, den folgenden Punkten.
--model.estimators_ [0] ; Wenn Sie nicht[0]angeben, tritt ein Fehler auf. Da nur einer von mehreren Entscheidungsbäumen angezeigt wird, geben Sie ihn mit[0]usw. an.
--feature_names; Anfangs wurde features angegeben, aber ein Fehler. Da es während des Lernens zu einer Dummy-Variablen mitpd.dummies ()gemacht wurde, wurde X.columns nach dem Erstellen zu einer Dummy-Variablen Konkretisieren
Ich war ein wenig beeindruckt, als ich den Entscheidungsbaum richtig anzeigen konnte.
Schließlich
Durch sorgfältiges Betrachten des Inhalts der Daten und der Parameter der Funktion habe ich irgendwie verstanden, was ich tat. Als nächstes möchte ich die Punktzahl so weit wie möglich erhöhen, indem ich die Parameter ändere und die Funktionen erhöhe.
Referenz
--Überprüfen Sie die Daten
- Datenübersicht mit Pandas
- [Python] [Maschinelles Lernen] Anfänger ohne Wissen versuchen vorerst maschinelles Lernen
- Pandas-Funktionen nützlich für die Titanic-Datenanalyse --Lernen
- Konvertieren von kategorialen Variablen in Dummy-Variablen mit Pandas (get_dummies)
- Zufälliger Wald von Scikit-learn
- Erstellen Sie ein Diagramm mit der Plotmethode von Pandas und visualisieren Sie die Daten
- Vorhersage von Nichterscheinen für Beratungstermine in der zufälligen Gesamtstruktur von Python scikit-learn
- Installationsverfahren von dtreeviz und grahviz zur Visualisierung des Ergebnisses der zufälligen Python-Gesamtstruktur
Recommended Posts