[In-Database Python Analysis Tutorial mit SQL Server 2017] Schritt 5: Training und Speichern von Modellen mit T-SQL
Vom Anfang des Tutorials
In-Database Python Analysis für SQL-Entwickler
Vorheriger Schritt
Schritt 4: Feature-Extraktion von Daten mit T-SQL
Nächster Schritt
Schritt 6: Manipulieren des Modells
Schritt 5: Training und Speichern des Modells mit T-SQL
In diesem Schritt lernen Sie, wie Sie ein Modell für maschinelles Lernen mit den Python-Paketen scicit-learn und revoscalepy trainieren. Diese Python-Pakete sind bereits mit SQL Server Machine Learning Services installiert, sodass Sie Module laden und die erforderlichen Funktionen in gespeicherten Prozeduren aufrufen können. Trainieren Sie Ihr Modell mit den Datenfunktionen, die Sie erstellen, und speichern Sie das trainierte Modell in einer SQL Server-Tabelle.
Teilen Sie die Beispieldaten mit der gespeicherten Prozedur "TrainTestSplit" in Trainingssatz und Testsatz auf
Die gespeicherte Prozedur "TrainTestSplit" wird in SQL Server durch Schritt 2: Importieren von Daten in SQL Server mithilfe von PowerShell (http://qiita.com/qio9o9/items/98df36982f1fbecdf5e7) definiert.
- Erweitern Sie im Objekt-Explorer von Management Studio die Option Programmierung> Gespeicherte Prozeduren.
- Klicken Sie mit der rechten Maustaste auf "TrainTestSplit" und wählen Sie "Ändern", um das Transact-SQL-Skript in einem neuen Abfragefenster zu öffnen.
TrainTestSplit teilt die Daten in der Tabelle nyctaxi_sample in zwei Tabellen auf, nyctaxi_sample_training und nyctaxi_sample_testing.
```SQL:TrainTestSplit
CREATE PROCEDURE [dbo].[TrainTestSplit](@pct int)
AS
DROP TABLE IF EXISTS dbo.nyctaxi_sample_training
SELECT * into nyctaxi_sample_training FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) < @pct
DROP TABLE IF EXISTS dbo.nyctaxi_sample_testing
SELECT * into nyctaxi_sample_testing FROM nyctaxi_sample
WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) > @pct
GO
```
-
Führen Sie die gespeicherte Prozedur aus und geben Sie eine Ganzzahl ein, die den Prozentsatz darstellt, den Sie dem Trainingssatz zuweisen möchten. In der folgenden Anweisung werden beispielsweise 60% der Daten einem Trainingssatz zugewiesen. Trainings- und Testdaten werden in zwei separaten Tabellen gespeichert.
EXEC TrainTestSplit 60 GO
Erstellen Sie mit scikit-learn ein logistisches Regressionsmodell
In diesem Abschnitt erstellen Sie eine gespeicherte Prozedur, die Ihr Modell anhand der von Ihnen erstellten Trainingsdaten trainiert. Diese gespeicherte Prozedur verwendet die Scicit-Learn-Funktion, um ein logistisches Regressionsmodell zu trainieren. Dies wird mithilfe der gespeicherten Systemprozedur sp_execute_external_script implementiert, um die mit SQL Server installierte Python-Laufzeit aufzurufen.
Die Umschulung des Modells wird erleichtert, indem neue Trainingsdaten als Parameter definiert und eine gespeicherte Prozedur erstellt werden, die den Aufruf der gespeicherten Systemprozedur sp_execute_exernal_script umschließt.
Die gespeicherte Prozedur "TrainTipPredictionModelSciKitPy" wird in SQL Server durch Schritt 2 definiert: Importieren von Daten in SQL Server mithilfe von PowerShell (http://qiita.com/qio9o9/items/98df36982f1fbecdf5e7).
-
Erweitern Sie im Objekt-Explorer von Management Studio die Option Programmierung> Gespeicherte Prozeduren.
-
Klicken Sie mit der rechten Maustaste auf "TrainTipPredictionModelSciKitPy" und wählen Sie "Ändern", um das Transact-SQL-Skript in einem neuen Abfragefenster zu öffnen.
DROP PROCEDURE IF EXISTS TrainTipPredictionModelSciKitPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelSciKitPy](@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle # import pandas from sklearn.linear_model import LogisticRegression ##Create SciKit-Learn logistic regression model X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) SKLalgo = LogisticRegression() logitObj = SKLalgo.fit(X, y) ##Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO -
Führen Sie die folgende SQL-Anweisung aus, um das trainierte Modell in der Tabelle nyc_taxi_models zu registrieren.
DECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelSciKitPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('SciKit_model', @model);
-
Stellen Sie sicher, dass der Tabelle nyc_taxi_models ein neuer Datensatz hinzugefügt und das serialisierte Modell registriert wird.

Erstellen Sie mit dem revoscalepy-Paket ein logistisches Regressionsmodell
Trainieren Sie anschließend das logistische Regressionsmodell mit der gespeicherten Prozedur "TrainTipPredictionModelRxPy" unter Verwendung des neuen RevoScalePy-Pakets. Das RevoScalePy-Paket von Python enthält Algorithmen für die Objektdefinition, Datenverarbeitung und das maschinelle Lernen, die denen des RevoScaleR-Pakets von R ähneln. Mit dieser Bibliothek können Sie Vorhersagemodelle mit gängigen Algorithmen wie logistischen, linearen Regressions- und Entscheidungsbäumen trainieren, Rechenkontexte erstellen, Daten zwischen Rechenkontexten verschieben und Daten verarbeiten. Weitere Informationen zu RevoScalePy finden Sie unter Einführung in RevoScalePy.
Die gespeicherte Prozedur "TrainTipPredictionModelRxPy" wird in SQL Server über Schritt 2: Importieren von Daten in SQL Server mit PowerShell definiert.
-
Erweitern Sie im Objekt-Explorer von Management Studio die Option Programmierung> Gespeicherte Prozeduren.
-
Klicken Sie mit der rechten Maustaste auf "TrainTipPredictionModelRxPy" und wählen Sie "Ändern", um das Transact-SQL-Skript in einem neuen Abfragefenster zu öffnen.
DROP PROCEDURE IF EXISTS TrainTipPredictionModelRxPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelRxPy](@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle # import pandas from revoscalepy.functions.RxLogit import rx_logit ## Create a logistic regression model using rx_logit function from revoscalepy package logitObj = rx_logit("tipped ~ passenger_count + trip_distance + trip_time_in_secs + direct_distance", data = InputDataSet); ## Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO
- Die SELECT-Abfrage verwendet die benutzerdefinierte Skalarfunktion fnCalculateDistance, um den direkten Abstand zwischen der Einstiegsposition und der Ausschiffungsposition zu berechnen. Das Ergebnis der Abfrage wird in der Standard-Python-Eingabevariablen "InputDataset" gespeichert.
- Das Python-Skript ruft die logisticRegression-Funktion von revoscalepy auf, die in Machine Learning Services enthalten ist, um ein logistisches Regressionsmodell zu erstellen. --Erstellen Sie ein Modell mit tapped als Zielvariable (Bezeichnung) und Passagieranzahl, trip_distance, trip_time_in_secs und direct_distance als erklärende Variablen (Feature).
- Das trainierte Modell, das durch die Python-Variable "logitObj" angegeben wird, wird serialisiert und als Ausgabeparameter zurückgegeben. Durch Registrieren dieser Ausgabe in der Tabelle nyc_taxi_models kann sie wiederholt für zukünftige Vorhersagen verwendet werden.
-
Führen Sie die folgende SQL-Anweisung aus, um das trainierte Modell in der Tabelle nyc_taxi_models zu registrieren.
DECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelRxPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('revoscalepy_model', @model);
Die Datenverarbeitung und Modellanpassung kann einige Minuten dauern. Nachrichten, die an den Python-Standard-Stream weitergeleitet werden, werden im Management Studio-Nachrichtenfenster angezeigt.
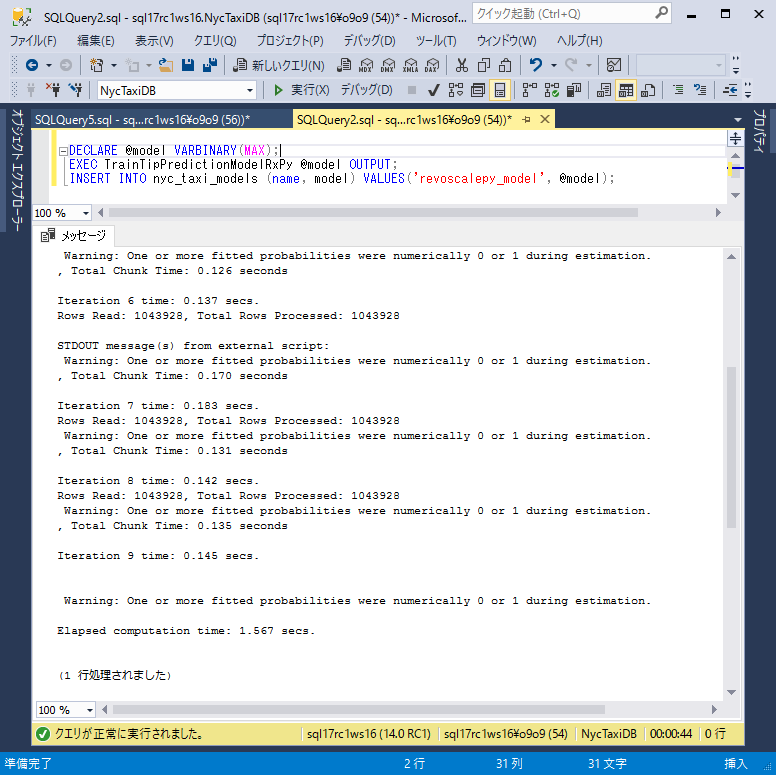
-
Stellen Sie sicher, dass der Tabelle nyc_taxi_models ein neuer Datensatz hinzugefügt und das serialisierte Modell registriert wird.

Der nächste Schritt besteht darin, eine Vorhersage unter Verwendung des trainierten Modells zu erstellen.
Verknüpfung
Nächster Schritt
Schritt 6: Manipulieren des Modells
Vorheriger Schritt
Schritt 4: Feature-Extraktion von Daten mit T-SQL
Vom Anfang des Tutorials
In-Database Python Analysis für SQL-Entwickler
Quelle
Step 5: Train and save a model using T-SQL
Verwandte Artikel
Machine Learning Services with Python
Recommended Posts