[PYTHON] SVM-Experiment 1
1. Welche Art von Inhalten
Ein Satz von 3 H x B Pixel 1-Kanal-Bildern ist gegeben. Zwei Blätter geben einen Merkmalsvektor als Satz an, und ein Blatt wird segmentiert und wird zu einer Zielvariablen. Die Idee ist, einen anderen segmentierten Kanal aus den Daten zweier Kanäle zu reproduzieren.
Als erste Idee wäre es schön, wenn wir einen anderen Kanal aus den Pixelwerten von 2 Kanälen in Pixeleinheiten vorhersagen könnten. Natürlich besteht das Thema darin, über etwas in der Faltungsmatrix nachzudenken und bis zu einigen Pixelabständen um diese herum zu lesen, um eine Vorhersage zu treffen.
Ferner wird die Zielvariable danach klassifiziert, ob der Pixelwert gleich oder größer als der angegebene Wert ist, und es wird erwartet, dass der Pixelwert durch Regression für den Wert unter dem angegebenen Wert vorhergesagt wird.
Als ersten Versuch habe ich diese Klassifizierung vorerst ausprobiert.
Die Ausführungsumgebung von Python wurde mit venv getrennt und die erforderlichen Bibliotheken mit pip darin installiert.
python3 -m venv ./P
source P/bin/activate
pip install --upgrade pip
pip install --upgrade scikit-image
2. Datenerfassung und Bestätigung
2.1 Daten lesen / prüfen
Zwei 1-Kanal-Bilder werden gelesen und gestapelt, um ein 2-Kanal-Bild zu bilden. Es sollte eindimensional sein und die Klasse (0 oder 1) sollte mit dem Pixelwert "[p1, p2]" verglichen werden.
Ich habe scicit-image verwendet, um das Bild zu laden. Diesmal hätte alles in Ordnung sein sollen. Wenn Sie das Bild laden, wird es zu einem H x W-Numpy-Array.
so was
>>> from skimage import io
>>> img = io.imread('train_images/train_hh_00.jpg')
>>> print(img.shape, img.dtype)
(8098, 11816) uint8
>>> print(img.max(), img.min(), img.mean(), img.std())
255 0 4.339263004581821 4.489037358487263
>>> print(img)
[[1 1 1 ... 6 7 5]
[2 2 2 ... 6 8 8]
[2 2 2 ... 7 8 9]
...
[2 2 1 ... 6 7 8]
[2 3 3 ... 8 9 8]
[2 3 3 ... 8 9 8]]
Danach
io.imshow(img)
io.show()
Wenn Sie dies tun, können Sie es als Bild überprüfen
img *= 20
Wenn Sie so etwas tun, können Sie den Pixelwert erweitern.
2.2 Bestätigung der Pixelwertverteilung von HH-, HV-Bildern
Ich werde damit klassifizieren, also werde ich es visuell richtig überprüfen.
Erstellen Sie ein Array von Numpy-Arrays der gelesenen HH-, HV- und Anmerkungsbilder und zeichnen Sie sie mit matplotlib in 3D. Wenn ich es versuche, ist das so langsam wie die Hölle.
Ich kann nicht sehr viel zeichnen, deshalb werde ich versuchen, nur einen Teil zu zeichnen, indem ich ihn wie folgt eindimensional mache.
import matplotlib.pyplot as plt
def reshape_them(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(rimg[0][0][75500000:75510000], rimg[1][0][75500000:75510000], rimg[2][0][75500000:75510000], marker='o')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
Die folgenden Ergebnisse wurden erhalten.
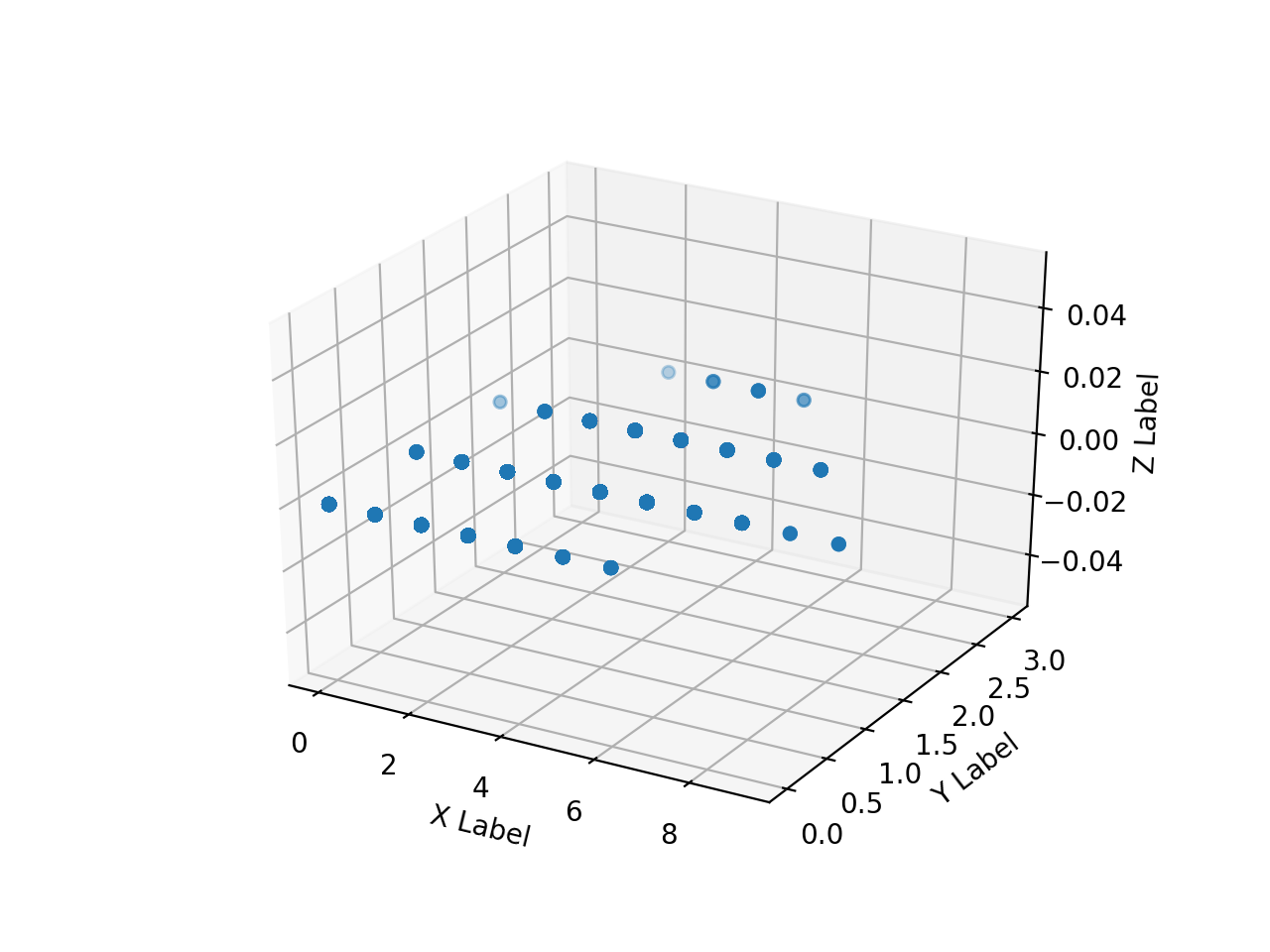
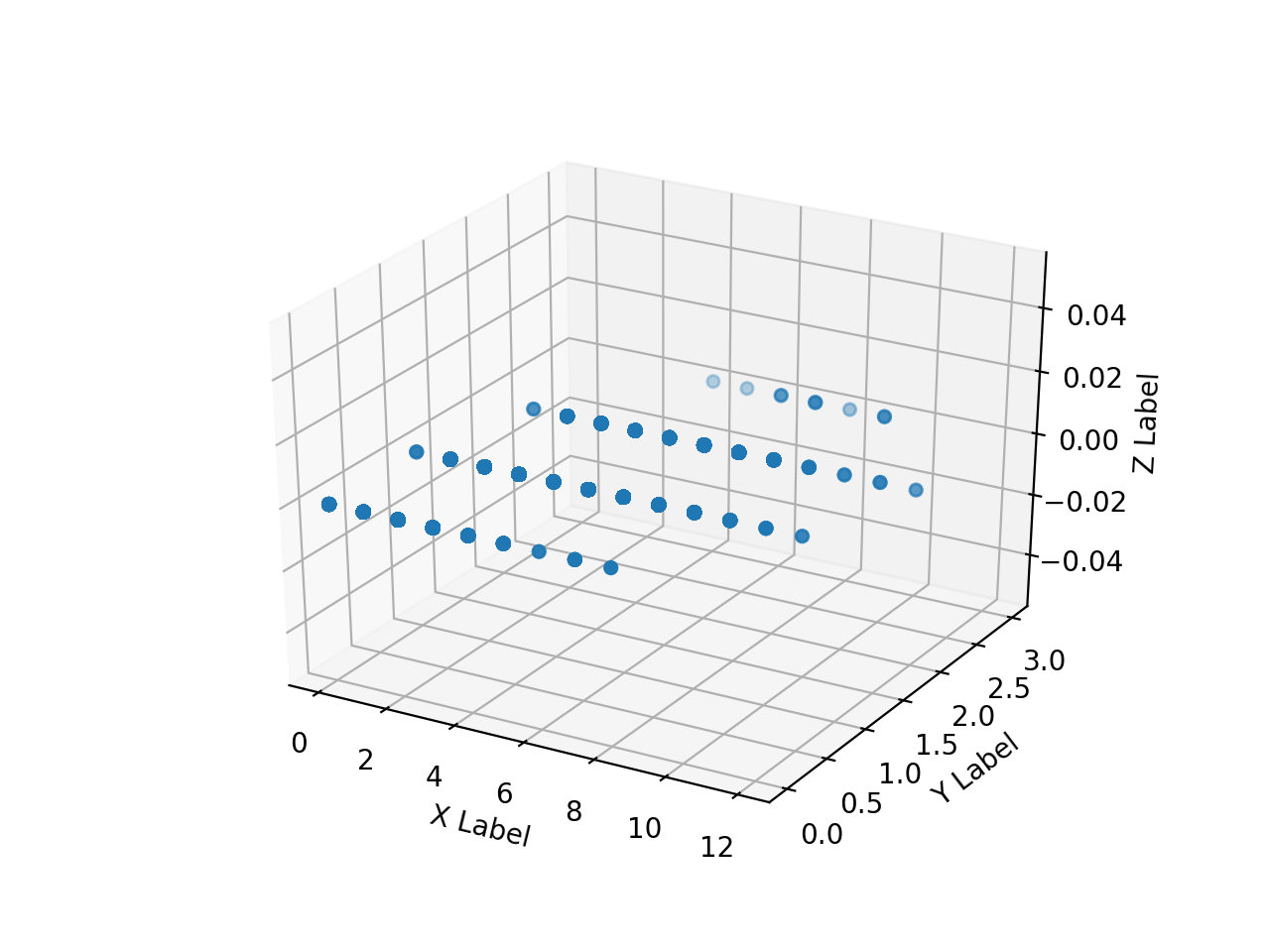
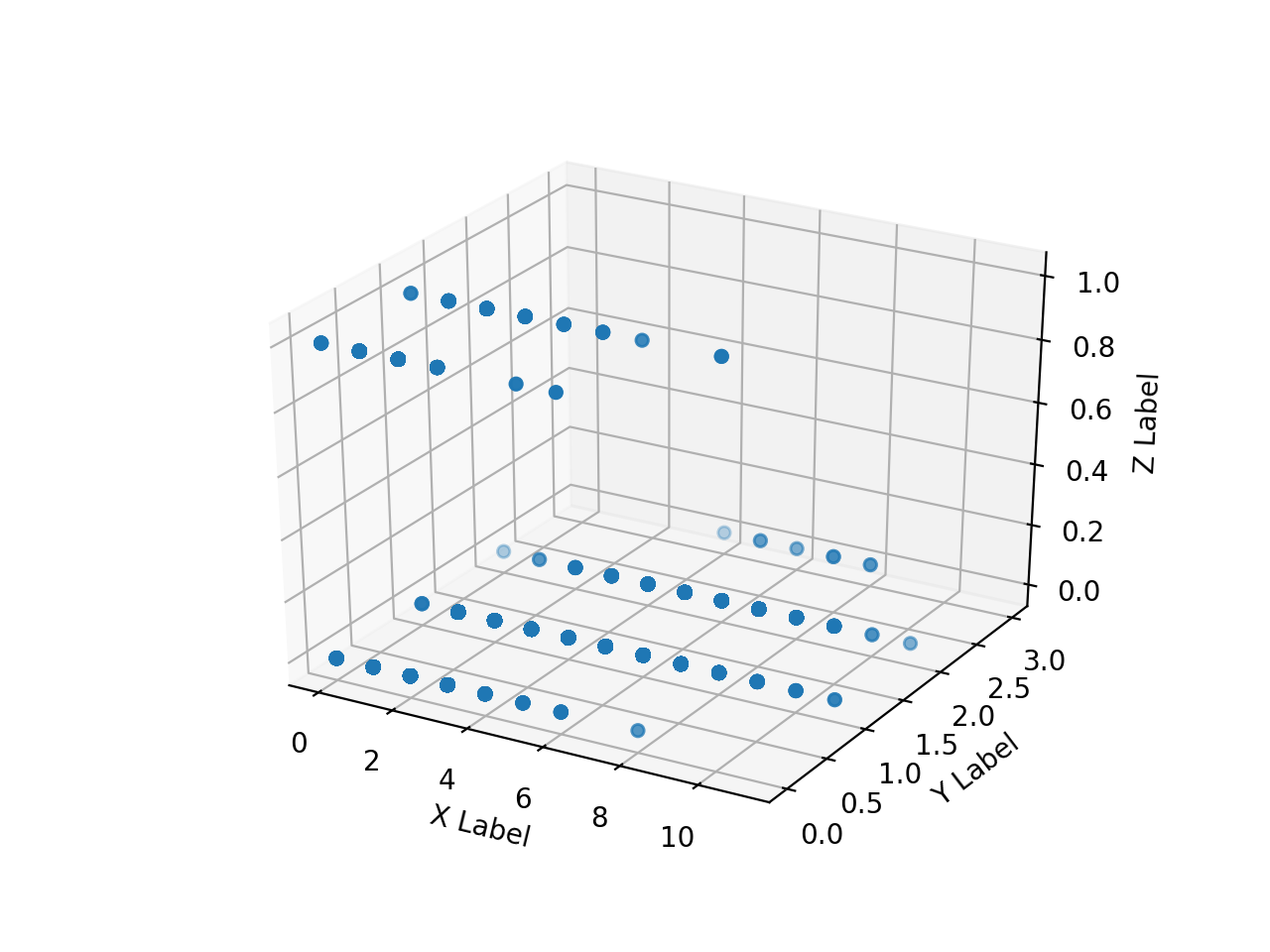
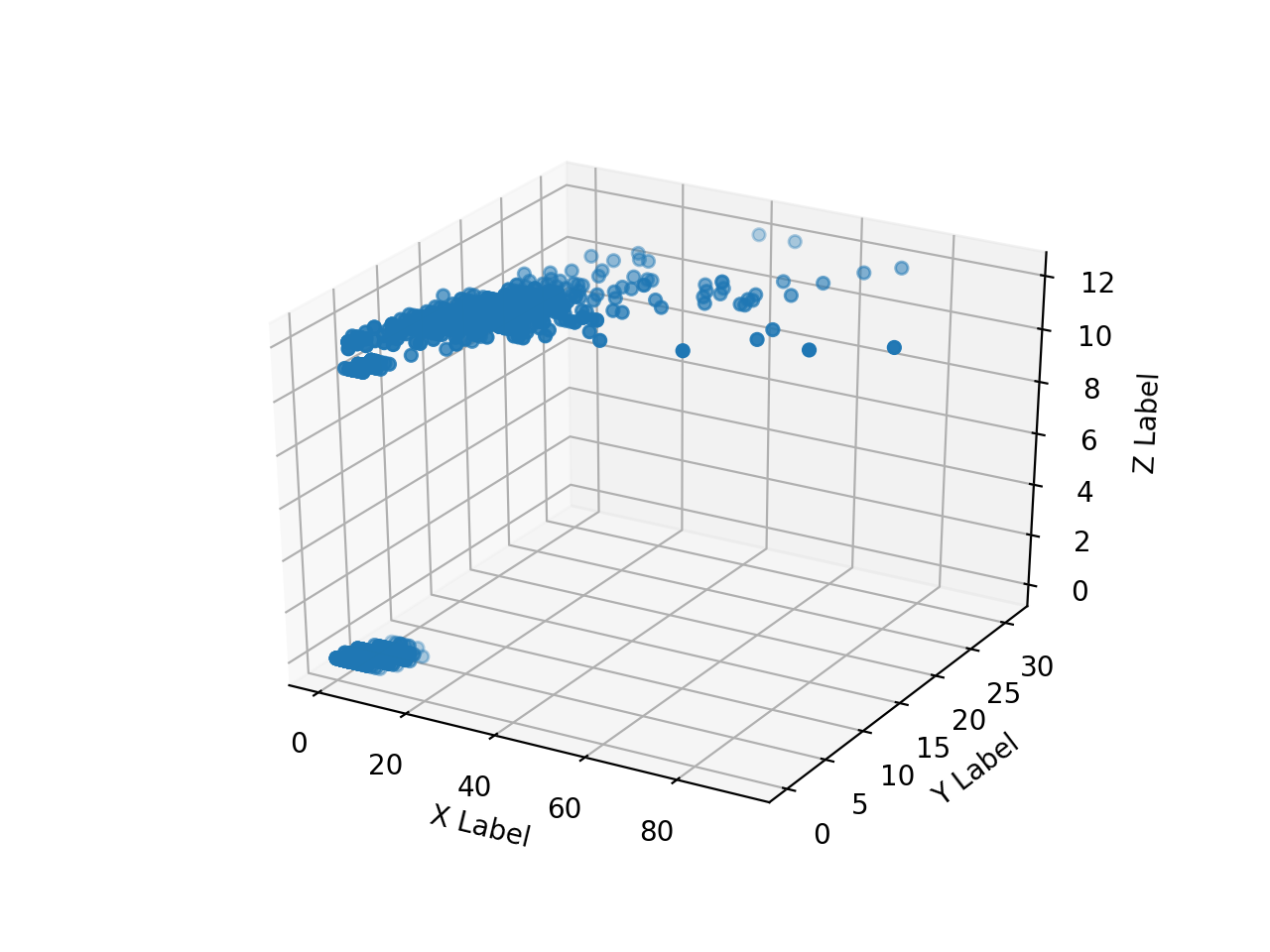
Der Array-Bereich von "ax.scatter ()" ist "[0: 10000]", "[500000: 510000]", "[5500000: 5510000]", "[755000000: 75510000]".
Anmerkung Aufgrund der Zweckmäßigkeit des Bildes ist der Bereich, in dem der Pixelwert (Z) der Lehrerdaten einen gewissen Wert annimmt, erheblich nach hinten vorgespannt. Es ist ersichtlich, dass die gleichen HH- und HV-Werte in zwei Klassen unterteilt sind. Es ist also rücksichtslos, nur HH und HV in zwei Klassen einzuteilen, aber jetzt wollen wir sehen, was wir damit erreichen können.
2.3 Erstellen Sie ein 3-Kanal-Bild
HH, HV 1-Kanal-Bilder werden gestapelt, um 3-Kanal-Bilder zu erstellen.
Ich dachte, es wäre gut, das oben erwähnte Numpy-Array zu stapeln, aber im Mehrkanalbild ist das 2D-Array nicht für die Anzahl der Kanäle gestapelt, sondern Ein 1D-Array mit der Länge der Anzahl der Kanäle wurde in XY aufgereiht.
Erstellen Sie dazu zunächst ein Array von 3 nebeneinander angeordneten 2D-Arrays (imgx) und ändern Sie dann mit transponieren () die "Achse", um die Kanalrichtung zur innersten (imgy) zu machen.
imgx = np.array([imgs[0], imgs[1], imgs[1]*0])
imgy = imgx.transpose(1,2,0)
imgz = imgy * 16
io.imshow(imgz)
io.show()
Da 3 Kanäle erforderlich sind, wird \ * 0 verwendet, um alle 0 Ebenen zu erstellen und einzuschließen. Da der Pixelwert zu klein ist, wird er um \ * 16 korrigiert, damit er unterschieden werden kann (imgz).
Da es eine große Sache ist, werde ich versuchen, es neben dem Originalbild anzuzeigen.
im21 = cv2.hconcat([gray2rgb(imgs[0]*16), gray2rgb(imgs[1]*16)])
im22 = cv2.hconcat([gray2rgb(imgs[2]*16), imgz])
im2 = cv2.vconcat([im21, im22])
io.imshow(im2)
io.show()
Gray2rgb () wird verwendet, um die Anzahl der Kanäle beim Beitritt abzugleichen.
3. Klassifizierung - SVM
3.1 SVM
Kommen wir zurück zur Geschichte. Nachdem Sie ein H x B 1-Kanal-Bild gelesen haben, formen Sie es in 1 x H \ * W um. Wenn dies durch Stapeln von 2 Bildern transponiert wird, werden die Pixelwerte von 2 Bildern für jedes Pixel angeordnet, und wenn es auch so eingestellt wird, dass das Anmerkungsbild auf 1 x H \ * W umgeformt wird, scheint es, dass mit SVM ein Klassifizierer erstellt werden kann.
import sklearn.svm
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time
def reshape_and_calc(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
print(rimg[0].shape, rimg[0].dtype, rimg[0].ndim)
train = np.vstack((rimg[0], rimg[1])).transpose()
label = rimg[2][0]
print(train.shape, label.shape)
train = train / 16.0 # [0..255]Zu[0..1)Entspricht 16 mal danach
label = np.where(label>10, 1, 0)
print(train)
print(label)
Erschreckenderweise handelt es sich bei den vom Training zu verzehrenden Daten um eine N x 2-Matrix, aber die von svm of scikit-learn verzehrte Bezeichnung (Zielvariable) ist ein 1 x N-Vektor (also "transponieren ()" bei der Berechnung von "Zug"). Es ist angehängt). Warum ist es vertikal und horizontal unterschiedlich?
Geben Sie danach das SVM-Klassifiziererobjekt vollständig wie unten gezeigt ein und serialisieren Sie sich schließlich mit joblib.
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
svm.fit(train, label)
joblib.dump(svm, 'svmmodel.sav')
Diese svm.fit () nimmt jedoch viel Zeit in Anspruch und macht keine Fortschritte, sodass sie irgendwo hängen bleibt, ob sie wirklich berechnet. Egal wie lange ich warte, ich kann nicht sagen, ob es nutzlos ist.
Ich frage mich also, ob es in Ordnung ist, dies zu tun, aber ich werde versuchen, die Daten nach und nach auszuschneiden und nacheinander zu trainieren. Der folgende Code hat funktioniert.
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
#print(train_X, test_X, train_y, test_y)
print('data splitted', train_X.shape, test_X.shape, train_y.shape, test_y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
svm.fit(train_X[offset:L2], train_y[offset:L2])
offset += L
print('done')
y_pred = svm.predict(test_X)
print('Misclassified samples: %d' % (test_y != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(test_y, y_pred))
Ein solches Protokoll bleibt bestehen.
fitting 76349440 / 76548774 706.0181198120117 sec
fitting 76414976 / 76548774 706.6317739486694 sec
fitting 76480512 / 76548774 707.2629809379578 sec
fitting 76546048 / 76548774 707.8376820087433 sec
done
Misclassified samples: 54996
Accuracy: 1.00
Er handhabte 76.548.774 Punkte in 707 Sekunden.
Ich wurde plötzlich süchtig danach, als die Überprüfung in einer anderen Dateigruppe durchgeführt wurde, und ich wollte nicht train_test_split, weil ich alle Daten in das Training einbauen wollte.
3.2 SVM-Klassifizierung - Gleichgewicht zwischen positiv und negativ
train_test_split () schneidet einen Satz für das Training und einen Satz für die Überprüfung zur Bewertung der Lernergebnisse aus einem Satz von Trainingsdaten und Labels aus. Übrigens scheint es, dass Shuffle zufällig hinzugefügt wird.
Hier ist es jedoch eine Verschwendung, ein Teil für die Auswertung zu drehen. Da die Auswertung in einer anderen Datei erfolgt, nehmen wir an, dass Sie die gesamte Datei für Trainingsdaten verwenden möchten und nicht "train_test_split ()" verwenden.
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
Wenn Sie einfach den Teil von "train, label" in "train_X, train_y" einfügen, wird er abgelehnt, da die Eile-Label-Daten nur korrekte Beispiele enthalten.
ValueError: The number of classes has to be greater than one; got 1 class
Wenn Sie sich das vorstellen, war die Quelle dieser Lehrerdaten ein einzelnes Bild mit Pixelwerten, und der einzige andere Teil der Klasse war der kleine Bereich am unteren Rand des Bildes. Wenn Sie den Pixelwert von oben einklemmen, wird nur eine Klasse eingeschlossen, wenn Sie nicht wesentlich vorrücken.
Die Verbesserungsmethode besteht darin, die gleiche Anzahl von Pixeln für beide Klassen = 0 und = 1 zu extrahieren, sie zu kombinieren, sie für alle Fälle zufällig zu mischen und sie in der Reihenfolge von oben zu verarbeiten, jeweils 65536. Um die gleiche Anzahl aus beiden Klassen zu extrahieren, benötigen die mehr Klassen ein zufälliges Mischen und werden kombiniert und erneut gemischt.
Als ich es versuchte, war das extrem langsam. Es wird gesagt, dass es schnell ist, weil es numpy ist, aber es ist natürlich langsam, wenn Sie dies tun.
In einer Datei betrug die Anzahl der Pixel 95.685.968, von denen 4.811.822 positiv und negativ waren, sodass 9.623.644 Punkte extrahiert wurden. Es gibt zwei Werte für HH und VV pro Punkt, und es ist ein 64-Bit-Gleitkommawert, wenn er mit [0, 1) standardisiert ist, also 96 Millionen Punkte x 2 x 8 Bytes Die Eingabedaten wurden durch Extrahieren von 153,6 M aus 1,54 G erstellt.
def reshape_them(imgs):
rimg = list(map(lambda i: i.reshape([1, -1]), imgs))
train = np.vstack((rimg[0], rimg[1])).transpose()
teach = rimg[2][0]
print(train.shape, teach.shape)
train = train / 256.0
teach = np.where(teach>10, 1, 0)
return [train, teach]
def balance(data):
train_x = data[0]
train_y = data[1]
mask = train_y == 1
train_x_pos = train_x[mask]
train_x_neg = train_x[np.logical_not(mask)]
sample = min(len(train_x_pos), len(train_x_neg))
train_y_balance = [1 for i in range(sample)] + [0 for i in range(sample)]
print('shrink length to', len(train_y_balance))
if len(train_x_pos) < len(train_x_neg):
np.random.shuffle(train_x_neg)
else:
np.random.shuffle(train_x_pos)
train_x_balance = np.concatenate([train_x_pos[:sample], train_x_neg[:sample]])
print("shuffled and concatenated", train_x_balance.shape)
Y = np.hstack([train_x_balance, np.array(train_y_balance).reshape([len(train_y_balance),1])])
#print(Y.shape)
np.random.shuffle(Y)
print(Y[:,0:2], Y[:,2].transpose())
return([Y[:,0:2], Y[:,2].transpose()])
def run(train_X, train_Y, model):
print(train_X.shape, train_Y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
#print(train_X[offset:L2], train_Y[offset:L2])
model.fit(train_X[offset:L2], train_Y[offset:L2])
offset += L
print('done')
(X, Y) = reshape_them(imgs)
(X, Y) = balance([X, Y])
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
run(X, Y, svm)
3.3 SVM-Nach dem Lernen
Das Lernen selbst wurde auf AWS durchgeführt. Wenn das Lernen beendet ist
joblib.dump(svm, modelfile)
Das SVM-Objekt wird als Homura serialisiert. Bringen Sie dies auf Ihren lokalen PC Für die vorliegende Datei
with open(modelfile, mode="rb") as f:
svm = joblib.load(f)
M = len(X)
L=65536
offset=0
start_time = time.time()
y_pred = []
while offset < M:
print('prediciting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
_Y = svm.predict(X[offset:L2])
y_pred.append(_Y)
#print('Misclassified samples: %d' % (Y[offset:L2] != _Y).sum())
#print('Accuracy: %.2f' % accuracy_score(Y[offset:L2], _Y))
offset += L
predicted = np.concatenate(y_pred).reshape(imgs[2].shape)
io.imshow(predicted)
io.show()
im2 = cv2.hconcat([predicted*10.0, imgs[2]*1.0])
io.imshow(im2)
io.show()
Wenn Sie den vorhergesagten Wert löschen und kombinieren und zum Bild zurückgeben, können Sie anscheinend beurteilen, wie sehr er als Bild aussieht.
Wenn ich es versuche, unterscheiden sich die Modulnamen zwischen Linux in der AWS-Umgebung und Python im lokalen MacOS geringfügig, wie unten gezeigt, und ich kann es nicht lesen.
File "/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/pickle.py", line 1426, in find_class
__import__(module, level=0)
ModuleNotFoundError: No module named 'sklearn.svm._classes'
Sicher, wenn Sie sich den Anfang der Serialisierungsdatei ansehen, wenn Sie es mit AWS machen
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 5f |..csklearn.svm._|
00000010 63 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 |classes.SVC.q.).|
00000020 71 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 |q.}q.(X....decis|
00000030 69 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 |ion_function_sha|
00000040 70 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 0a |peq.X....ovrq.X.|
Es gibt Ansco, aber wenn ich versuche, es auf Mac zu spucken
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 63 |..csklearn.svm.c|
00000010 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 71 |lasses.SVC.q.).q|
00000020 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 69 |.}q.(X....decisi|
00000030 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 70 |on_function_shap|
00000040 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 06 00 |eq.X....ovrq.X..|
Es gibt keine Ansco wie. Nun, an einem solchen Ort gibt es eine Unschärfe.
Ich konnte nicht anders, also habe ich versucht, mit AWS Vorhersagen zu treffen, aber im Gegensatz zum Lernen ist es nur eine Pfadberechnung, aber es ist tödlich langsam. Wie oben erwähnt, gibt es keine Extraktion, um die Zahlen positiv und negativ zu machen, daher gibt es viele Berechnungspunkte, aber es ist immer noch langsam.
ex73: prediciting 65929216 / 0.9993775530341474 9615.45419716835 sec
ex75: prediciting 70975488 / 0.9991167432331827 10432.654431581497 sec
Es war ein 2,8-stündiger Kurs pro Datei.
 Links vorhergesagt, rechtes Etikett
Links vorhergesagt, rechtes Etikett