[PYTHON] Kernel SVM (make_circles)
■ Einführung
Dieses Mal werde ich die Implementierung einer einfachen Kernel-SVM zusammenfassen.
[Zielgruppe Leser]
・ Diejenigen, die einfachen Code von Kernel-SVM lernen möchten
・ Diejenigen, die die Theorie nicht verstehen, aber die Implementierung sehen und ein Bild usw. geben möchten.
■ Kernel-SVM-Prozedur
Fahren Sie mit den nächsten 7 Schritten fort.
- Vorbereitung des Moduls
- Datenaufbereitung
- Datenvisualisierung
- Erstellen Sie ein Modell
- Modellplot
- Ausgabe des vorhergesagten Wertes
- Modellbewertung
1. Vorbereitung des Moduls
Importieren Sie zunächst die erforderlichen Module.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_circles
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import confusion_matrix, classification_report
## 2. Datenaufbereitung Dieses Mal verwenden wir den von sklearn bereitgestellten Datensatz make_circles.
Holen Sie sich zuerst die Daten, standardisieren Sie sie und teilen Sie sie dann auf.
X , y = make_circles(n_samples=100, factor = 0.5, noise = 0.05)
std = StandardScaler()
X = std.fit_transform(X)
Bei der Standardisierung beispielsweise wird der Einfluss der Merkmalsgrößen (erklärende Variablen) groß, wenn es zweistellige und vierstellige Merkmalsgrößen gibt. Die Skala wird durch Anpassen so ausgerichtet, dass der Durchschnitt 0 und die Varianz für alle Merkmalsgrößen 1 beträgt.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=123)
print(X.shape)
print(y.shape)
# (100, 2)
# (100,)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# (70, 2)
# (70,)
# (30, 2)
# (30,)
3. Datenvisualisierung
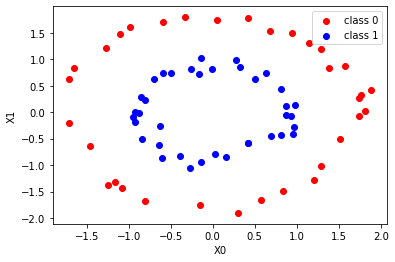
Schauen wir uns das Datenplot vor der Binärisierung in der Kernel-SVM an.
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c = "red", label = 'class 0' )
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c = "blue", label = 'class 1')
ax.set_xlabel('X0')
ax.set_ylabel('X1')
ax.legend(loc = 'best')
plt.show()
Merkmalsmenge entsprechend Klasse 0 (y_train == 0) (X0 ist horizontale Achse, X1 ist vertikale Achse): Rot
Merkmalsmenge entsprechend Klasse 1 (y_train == 1) (X0 ist die horizontale Achse, X1 ist die vertikale Achse): Blau
 Das Obige ist ein bisschen langwieriger Code, aber er kann kurz und prägnant sein.
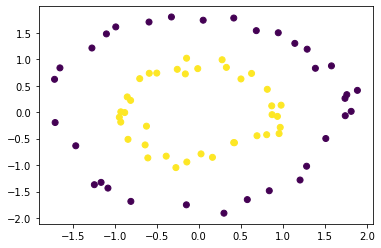
Das Obige ist ein bisschen langwieriger Code, aber er kann kurz und prägnant sein.
plt.scatter(X_train[:, 0], X_train[:, 1], c = y_train)
plt.show()
4. Erstellen Sie ein Modell
Erstellen Sie eine Instanz der Kernel-SVM und trainieren Sie sie.
svc = SVC(kernel = 'rbf', C = 1e3, probability=True)
svc.fit(X_train, y_train)
Diesmal ist eine lineare Trennung (durch eine gerade Linie getrennt) bereits unmöglich, daher wird im Argument kernel = 'rbf' gesetzt.
C ist ein Hyperparameter, den Sie selbst anpassen, während Sie die Ausgabewerte und Diagramme betrachten.
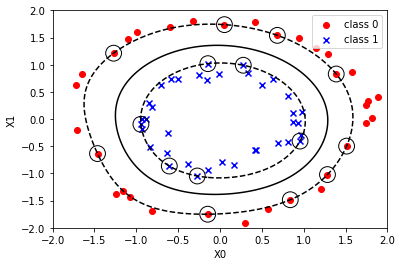
5. Modellplot
Nachdem Sie ein Modell der Kernel-SVM haben, zeichnen Sie es und überprüfen Sie es.
Die erste Hälfte entspricht genau dem obigen Streudiagrammcode. Danach ist es etwas schwierig, aber Sie können andere Daten zeichnen, indem Sie sie einfach so einfügen, wie sie sind. (Einige Feineinstellungen sind erforderlich)
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c='red', marker='o', label='class 0')
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c='blue', marker='x', label='class 1')
xmin = -2.0
xmax = 2.0
ymin = -2.0
ymax = 2.0
xx, yy = np.meshgrid(np.linspace(xmin, xmax, 100), np.linspace(ymin, ymax, 100))
xy = np.vstack([xx.ravel(), yy.ravel()]).T
p = svc.decision_function(xy).reshape(100, 100)
ax.contour(xx, yy, p, colors='k', levels=[-1, 0, 1], alpha=1, linestyles=['--', '-', '--'])
ax.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1],
s=250, facecolors='none', edgecolors='black')
ax.set_xlabel('X0')
ax.set_ylabel('X1')
ax.legend(loc = 'best')
plt.show()
6. Ausgabe des vorhergesagten Wertes
Mit dem erstellten Modell geben wir den vorhergesagten Wert der Klassifizierung an.
y_proba = svc.predict_proba(X_test)[: , 1]
y_pred = svc.predict(X_test)
print(y_proba[:5])
print(y_pred[:5])
print(y_test[:5])
# [0.99998279 0.01680679 0.98267058 0.02400808 0.82879465]
# [1 0 1 0 1]
# [1 0 1 0 1]
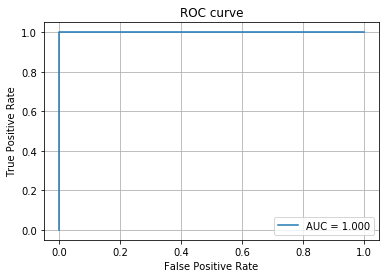
## 7. Leistungsbewertung Verwenden Sie die ROC-Kurve, um den Wert der AUC zu ermitteln.
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
auc_score = roc_auc_score(y_test, y_proba)
plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score))
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
print('accuracy:',accuracy_score(y_test, y_pred))
print('f1_score:',f1_score(y_test, y_pred))
# accuracy: 1.0
# f1_score: 1.0
classes = [1, 0]
cm = confusion_matrix(y_test, y_pred, labels=classes)
cmdf = pd.DataFrame(cm, index=classes, columns=classes)
sns.heatmap(cmdf, annot=True)
print(classification_report(y_test, y_pred))
'''
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 13
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
'''

■ Endlich
Basierend auf den obigen Schritten 1 bis 7 konnten wir ein Modell erstellen und die Leistung des Kernel-SVM bewerten.
Wir hoffen, dass es Anfängern helfen wird.