[PYTHON] Datenbereinigung Umgang mit fehlenden und Ausreißern
Ich werde über den Umgang mit Ausreißern und fehlenden Werten bei der Datenbereinigung schreiben. Stellen Sie sich vor, Sie laufen auf Jupyter.
Datenaufbereitung
Zunächst Datenaufbereitung Mit der Funktion make_classification von scikit-learn können Sie ganz einfach Daten erstellen. Bereiten Sie sie also vor.
Referenz: http://overlap.hatenablog.jp/entry/2015/10/08/022246
Lesen wir die Daten.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data = pd.read_csv('2d_data.csv', header = None)
Die diesmal vorbereiteten Daten sehen so aus
data = data.as_matrix()
data
#Ausgabe
array([[ 1.00000000e+00, -7.42847611e+00, 1.50990301e+00],
[ 0.00000000e+00, 2.98069292e+00, 1.96082119e+00],
[ 0.00000000e+00, 3.98825476e+00, 4.63638899e+00],
[ 1.00000000e+00, -5.78943741e+00, -4.62161424e+00],
[ 1.00000000e+00, -4.89444674e+02, -3.26972997e+02],
[ 1.00000000e+00, -1.93394930e+00, -4.72763616e-02],
[ 0.00000000e+00, -1.61177146e+00, 5.93220121e+00],
[ 1.00000000e+00, -6.67015188e+00, nan],
[ 1.00000000e+00, -2.93141529e+00, -1.04474622e-01],
[ 0.00000000e+00, -7.47618437e-02, 1.07000182e+00],
[ 1.00000000e+00, -2.69179269e+00, 4.16877367e+00],
[ 0.00000000e+00, nan, 3.45343849e+00],
[ 0.00000000e+00, -1.35413500e+00, 3.75165665e+00],
[ 1.00000000e+00, -6.22947550e+00, -1.20943430e+00],
[ 0.00000000e+00, 2.77859414e+00, 7.58210258e+00],
[ 1.00000000e+00, -5.71957792e+00, -2.43509341e-01],
[ 0.00000000e+00, 9.28321714e-01, 3.20852039e+02],
[ 0.00000000e+00, 8.50475089e+01, 2.90895510e+00],
[ 1.00000000e+00, -6.02948927e+00, -1.83119942e+00],
[ 0.00000000e+00, 1.11602534e+00, 3.35360162e+00]])
Sie können Ausreißer und fehlende Werte (Nan) überprüfen. Teilen wir es in x- und y-Daten.
X = data[:,1:3]
y = data[:,0].astype(int)
X.shape, y.shape
#Ausgabe
((20, 2), (20,))
Zeichnen wir nun die erste und zweite Spalte der X-Daten.
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='Blues');
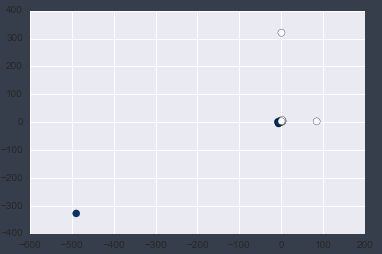
Sie können die Ausreißer durch Zeichnen deutlich erkennen.
So geben Sie fehlende Werte ein
Sie können Nan mit np.isnan () überprüfen. Wenn ein Wert fehlt, wird True zurückgegeben.
np.isnan(X[:, 0]),np.isnan(X[:, 1])
#Ausgabe
(array([False, False, False, False, False, False, False, False, False,
False, False, True, False, False, False, False, False, False,
False, False], dtype=bool),
array([False, False, False, False, False, False, False, True, False,
False, False, False, False, False, False, False, False, False,
False, False], dtype=bool))
Jetzt erstellen wir "X1" und "y1" ohne fehlende Werte.
X1 = X[~np.isnan(X[:, 1]) & ~np.isnan(X[:, 0])]
y1 = y[~np.isnan(X[:, 1]) & ~np.isnan(X[:, 0])]
X1, y1
#Ausgabe
Out[139]:
(array([[ -7.42847611e+00, 1.50990301e+00],
[ 2.98069292e+00, 1.96082119e+00],
[ 3.98825476e+00, 4.63638899e+00],
[ -5.78943741e+00, -4.62161424e+00],
[ -4.89444674e+02, -3.26972997e+02],
[ -1.93394930e+00, -4.72763616e-02],
[ -1.61177146e+00, 5.93220121e+00],
[ -2.93141529e+00, -1.04474622e-01],
[ -7.47618437e-02, 1.07000182e+00],
[ -2.69179269e+00, 4.16877367e+00],
[ -1.35413500e+00, 3.75165665e+00],
[ -6.22947550e+00, -1.20943430e+00],
[ 2.77859414e+00, 7.58210258e+00],
[ -5.71957792e+00, -2.43509341e-01],
[ 9.28321714e-01, 3.20852039e+02],
[ 8.50475089e+01, 2.90895510e+00],
[ -6.02948927e+00, -1.83119942e+00],
[ 1.11602534e+00, 3.35360162e+00]]),
array([1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0]))
So entfernen Sie den Ausreißer
X2 = X1[(abs(X1[:, 0] < 10)) & (abs(X1[:, 1]) < 10)]
y2 = y1[(abs(X1[:, 0] < 10)) & (abs(X1[:, 1]) < 10)]
Wenn Sie es so schreiben, wird eine Zahl von 10 oder mehr wie folgt zurückgegeben.
(array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True, True], dtype=bool),
array([ True, True, True, True, False, True, True, True, True,
True, True, True, True, True, False, True, True, True], dtype=bool))
Entfernen wir die Ausreißer.
X2 = X1[(abs(X1[:, 0] < 10)) & (abs(X1[:, 1]) < 10)]
y2 = y1[(abs(X1[:, 0] < 10)) & (abs(X1[:, 1]) < 10)]
Lassen Sie es uns planen.
plt.scatter(X2[:, 0], X2[:, 1],c = y2, s=50, cmap='Blues');
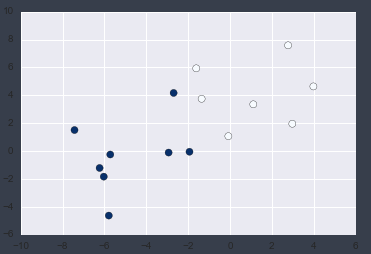
Ich konnte bestätigen, dass es keine Ausreißer gab!
Recommended Posts