[PYTHON] Da die Extraktion von Synonymen mit Word2Vec gut verlief, habe ich versucht, die Analyse zusammenzufassen
Einführung
Hallo, mein Name ist @To_Murakami und ich bin Datenwissenschaftler bei Speee. Ich bin kein Ingenieur, habe aber am Adventskalender des Unternehmens teilgenommen, um Analysebeispiele einschließlich Codierung zu verbreiten. Es ist fast Ende Dezember, nicht wahr? Heute möchte ich ein Beispiel für eine Analyse mit natürlicher Sprachverarbeitung namens Word2Vec vorstellen. Der Zweck der Implementierung dieser Logik ist, dass ich so etwas wie ** Detektor für Wortschwankungen (auch Wort) ** machen wollte. Warum können Sie die Wortnotationsschwankung von Word2Vec unterscheiden? Sobald Sie einen Überblick über die Funktionsweise haben (siehe unten), können Sie verstehen, warum.
Wie Word2Vec funktioniert (einfach)
Word2Vec ist buchstäblich ** ein Vektor von Wörtern . Natürlich sind Zahlen in den vektorisierten Inhalten enthalten. Mit anderen Worten, es ist möglich, die sprachlichen Daten von Wörtern zu quantifizieren!
Der Quantifizierungsmechanismus ist Lernen und Dimensionskomprimierung durch ein neuronales Netzwerk.
 Die obige Abbildung ist ein Beispiel für ein typisches Modell namens CBOW (Continuous Bug-of-Words). Jedes Wort in der Eingangsstufe wird als One-Hot-Vektor bezeichnet, und das "Flag" Ja "oder" Nein "wird durch" 0/1 "ausgedrückt. Hier wird die Vektorisierung des Wortes "kalt" durch Lernen berechnet. CBOW erfasst Informationen auch in mehreren Worten vorher und nachher und sendet sie an die Projektionsebene. Das gewichtete Lernen wird von der Projektionsschicht mit einem neuronalen Netzwerk durchgeführt, und der Wortvektor wird als Ausgabe berechnet. Die Anzahl der Dimensionen des Ausgabevektors und die Anzahl der Dimensionen der Eingabe können unterschiedlich sein. Sie kann bei der Modellierung angegeben werden. (Sie können auch steuern, wie viele Wörter vorher und nachher in die Projektionsebene eingefügt werden.)
Auf diese Weise wird jeder Wortvektor berechnet. Jede Zahl, aus der der Vektor besteht, gibt die Bedeutung und Eigenschaften des Wortes an. Die Idee dahinter basiert auf der Prämisse, dass " Wörter mit ähnlichen Bedeutungen und Verwendungen in einer ähnlichen Folge von Wörtern erscheinen **". Wenn wir diese Annahme akzeptieren, können wir annehmen, dass Wörter mit ähnlichen Vektoren ähnliche Bedeutungen haben. Wörter mit ähnlicher Notation und Synonyme mit derselben Bedeutung haben ähnliche Vektoren, sodass zu erwarten ist, dass sie auf einer Skala wie der Kosinusähnlichkeit extrahiert werden können.
Die obige Abbildung ist ein Beispiel für ein typisches Modell namens CBOW (Continuous Bug-of-Words). Jedes Wort in der Eingangsstufe wird als One-Hot-Vektor bezeichnet, und das "Flag" Ja "oder" Nein "wird durch" 0/1 "ausgedrückt. Hier wird die Vektorisierung des Wortes "kalt" durch Lernen berechnet. CBOW erfasst Informationen auch in mehreren Worten vorher und nachher und sendet sie an die Projektionsebene. Das gewichtete Lernen wird von der Projektionsschicht mit einem neuronalen Netzwerk durchgeführt, und der Wortvektor wird als Ausgabe berechnet. Die Anzahl der Dimensionen des Ausgabevektors und die Anzahl der Dimensionen der Eingabe können unterschiedlich sein. Sie kann bei der Modellierung angegeben werden. (Sie können auch steuern, wie viele Wörter vorher und nachher in die Projektionsebene eingefügt werden.)
Auf diese Weise wird jeder Wortvektor berechnet. Jede Zahl, aus der der Vektor besteht, gibt die Bedeutung und Eigenschaften des Wortes an. Die Idee dahinter basiert auf der Prämisse, dass " Wörter mit ähnlichen Bedeutungen und Verwendungen in einer ähnlichen Folge von Wörtern erscheinen **". Wenn wir diese Annahme akzeptieren, können wir annehmen, dass Wörter mit ähnlichen Vektoren ähnliche Bedeutungen haben. Wörter mit ähnlicher Notation und Synonyme mit derselben Bedeutung haben ähnliche Vektoren, sodass zu erwarten ist, dass sie auf einer Skala wie der Kosinusähnlichkeit extrahiert werden können.
- Ich habe vor ungefähr einem halben Jahr einen verwandten Artikel gepostet. Siehe. http://qiita.com/To_Murakami/items/6bd5638689166ec4821c
Hast du ein genaues Wort bekommen?
Ist die Anzeige im Abschnitt Mechanik tatsächlich korrekt? Ich habe 11000 Schönheitsartikel gecrawlt, einen Korpus erstellt und versucht, ihn zu überprüfen. Zusammenfassend konnte ich Wörter extrahieren, die ähnlicher waren als ich erwartet hatte **! Im Folgenden werde ich einige Beispielbeispiele geben.
<< Beispiel 1: "Diät" >>
 Die "Diätmethode" und die "Diätmethode" sind nur die Ausgabe für diesen Zweck.
"Nähe" wird durch ** Kosinusähnlichkeit ** des Zwei-Wort-Vektors bewertet ("Punktzahl" oben). Je ähnlicher die Wortfolge ist, desto höher ist die Ähnlichkeit.
"Diätmethode" hat aufgrund der Schwankung der Notation die gleiche Bedeutung wie "Diät". Wörter wie "Ausdünnen" und "Gewichtsverlust" haben den gleichen Zweck und die gleiche Bedeutung wie Diäten und weisen einen hohen Grad an Ähnlichkeit auf.
Die "Diätmethode" und die "Diätmethode" sind nur die Ausgabe für diesen Zweck.
"Nähe" wird durch ** Kosinusähnlichkeit ** des Zwei-Wort-Vektors bewertet ("Punktzahl" oben). Je ähnlicher die Wortfolge ist, desto höher ist die Ähnlichkeit.
"Diätmethode" hat aufgrund der Schwankung der Notation die gleiche Bedeutung wie "Diät". Wörter wie "Ausdünnen" und "Gewichtsverlust" haben den gleichen Zweck und die gleiche Bedeutung wie Diäten und weisen einen hohen Grad an Ähnlichkeit auf.
<< Beispiel 2: "Modisch" >>
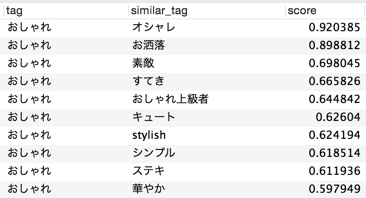 Immerhin zeigen "modisch" und "modisch", die gleichbedeutend mit Notationsschwankungen sind, ein hohes Maß an Ähnlichkeit. Darauf folgen Wörter, die einen Eindruck oder eine Bewertung von "modisch" vermitteln.
Immerhin zeigen "modisch" und "modisch", die gleichbedeutend mit Notationsschwankungen sind, ein hohes Maß an Ähnlichkeit. Darauf folgen Wörter, die einen Eindruck oder eine Bewertung von "modisch" vermitteln.
<< Beispiel 3: "Make" >>
 Bei einer Vielzahl von Wörtern wie make stehen die Wörter, die ein bestimmtes make angeben, an erster Stelle (da sie in einem ähnlichen Kontext verwendet werden).
Bei einer Vielzahl von Wörtern wie make stehen die Wörter, die ein bestimmtes make angeben, an erster Stelle (da sie in einem ähnlichen Kontext verwendet werden).
<< Beispiel 4: "Aoi Miyazaki" >>
 Sie können sehen, wie Aoi Miyazaki von Menschen auf der Welt gesehen wird (^ _ ^;)
Sie können sehen, wie Aoi Miyazaki von Menschen auf der Welt gesehen wird (^ _ ^;)
<< Beispiel 5: "Denim" >>
 Die Kleidung, die den gleichen Unterteilen entspricht, wird ebenfalls angezeigt, zeigt aber auch die Koordination des Oberkörpers an, die gut zu Denim passt.
Die Kleidung, die den gleichen Unterteilen entspricht, wird ebenfalls angezeigt, zeigt aber auch die Koordination des Oberkörpers an, die gut zu Denim passt.
<< Beispiel 6: "Fett" >>
 Es ist unversöhnlich (^ _ ^;)
Es ist unversöhnlich (^ _ ^;)
<< Beispiel 7: "Weihnachten" >>
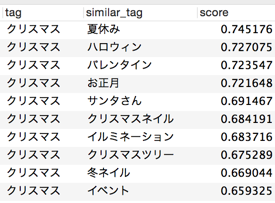 Vielleicht, weil es sich um einen Artikel zum Thema Schönheit handelt, werden Wörter aufgelistet, die sich auf Ereignisse und Ereignisse beziehen. Wenn es sich bei dem Korpus um ein bestimmtes persönliches Blog handelt, kann sich die Ausgabe ändern.
Vielleicht, weil es sich um einen Artikel zum Thema Schönheit handelt, werden Wörter aufgelistet, die sich auf Ereignisse und Ereignisse beziehen. Wenn es sich bei dem Korpus um ein bestimmtes persönliches Blog handelt, kann sich die Ausgabe ändern.
Einfallsreichtum
Wenn Sie sich auf die ** Datenvorverarbeitung ** konzentrieren, wird der Inhalt der Ausgabe viel besser. Die Vorverarbeitung ist eine morphologische Analyse. Sie können unnötige Wörter löschen und die Zeichenfolgen trennen, um die gewünschten Wörter zu erhalten.
① Erweiterung des Wörterbuchs
Ich habe durch Aktualisierung von "mecab-ipadic-NEologd" gelernt (ich denke, viele Leute wissen das). Zusätzlich zu NEologd haben wir ** ein Benutzerwörterbuch für unbekannte Wörter hinzugefügt, das durch unsere eigene Logik erhalten wurde **. Die richtige Nomenklatur und die neuesten Wörter wie Produktnamen wurden im Benutzerwörterbuch hinzugefügt.
② Stoppwort
Es wurde eine Liste von Wörtern hinzugefügt, die nicht für die Vektorisierung als Stoppwörter ausgewertet werden. Es wird in der Form vorliegen, die Zeichenfolgen und Allzweckwörter ausschließt.
Implementierung
Ich habe eine Bibliothek namens ** gensim ** benutzt. Mit gensim können Sie es in ** praktisch nur wenigen Zeilen ** implementieren. Ein wenig bequem ♪
- E / A von DB wird weggelassen.
Python
#!/usr/bin/python
# -*- coding: utf-8 -*-
from gensim.models import word2vec
import cython
from sqlalchemy import *
import pandas as pd
# fetch taglist from DB
engine_my = create_engine('mysql+mysqldb://pass:user@IP:port/db?charset=utf8&use_unicode=0',echo=False)
connection = engine_my.connect()
cur = connection.execute("select distinct(name) from tag;")
tags = []
for row in cur:
# need to decode into python unicode because db preserves strings as utf-8
# need to treat character sets altogether in one format
tags.append(row["name"].decode('utf-8'))
connection.close()
# Import text file and make a corpus
data = word2vec.Text8Corpus('text_morpho.txt')
# Train input data by Word2Vec(in option below, take CBOW method)
# Take about 5 min when training ~11000 documents
model = word2vec.Word2Vec(data, size=100, window=5, min_count=5, workers=2)
# Save temporary files
model.save("W2V.model")
# make similar word list (dict type)
similar_words = []
for tag in tags:
try:
similar_word = model.most_similar(positive=tag)
for i in range(10):
similar = {}
similar['tag'] = tag
similar['similar_tag'] = similar_word[i][0]
similar['score'] = similar_word[i][1]
similar_words.append(similar)
except:
pass
# Conver dict into DataFrame to filter data easily
df_similar = pd.DataFrame.from_dict(similar_words)
df_similar_filtered = df_similar[df_similar['similar_tag'].isin(tags)]
df_similar = df_similar.ix[:,['tag', 'similar_tag', 'score']]
Recommended Posts