[PYTHON] Denken Sie an Spezifikationen für die Entwicklung von Co-Filtering-Empfehlungs-Engines
Ich möchte eine Co-Filter-Empfehlung aussprechen, aber es gibt keine gute Open-Source-Bibliothek, und der ASP-Service beträgt im Grunde 50.000 Yen / Monat oder mehr. Ich habe keine andere Wahl, als es selbst zu machen
Was ist eine Co-Filter-Empfehlung?
Ich denke, das bekannteste Implementierungsbeispiel ist die Funktion "Leute, die dieses Produkt gekauft haben, haben auch dieses Produkt gekauft" von Amazon. Zuvor habe ich [Implementierung einer vereinfachten Version] eingeführt (http://qiita.com/haminiku/items/cdbf8eb488e0cf6a62fe). Dieser Artikel ist eine Fortsetzung der vereinfachten Version des Artikels.
Zitiert aus der Co-Filterung von Wikipedia
Collaborative Filtering (Collaborative Filtering, CF) ist eine Methode, die Präferenzinformationen vieler Benutzer sammelt und automatisch Rückschlüsse auf Informationen anderer Benutzer zieht, die ähnliche Präferenzen wie ein Benutzer haben. Es wird oft mit dem Mundpropaganda-Prinzip verglichen, das sich auf die Meinungen von Menschen mit ähnlichen Vorlieben bezieht.
 Da der Schrott und die Konstruktion von Mr. Haneda, einem Muskeltrainingsautor, der den Preis gleichzeitig mit dem Funken gewann, zuerst empfohlen wird, ist es Mr. Ryuishi Amazon. Der mit dem Naoki Award ausgezeichnete Stil ist auch ein guter Roman.
Da der Schrott und die Konstruktion von Mr. Haneda, einem Muskeltrainingsautor, der den Preis gleichzeitig mit dem Funken gewann, zuerst empfohlen wird, ist es Mr. Ryuishi Amazon. Der mit dem Naoki Award ausgezeichnete Stil ist auch ein guter Roman.
Kooperative Filterung ist eine tote Technologie
Wenn Sie im Internet fischen, gibt es ab 2005 einen japanischen Artikel. Außerdem sind die Unternehmen, die Empfehlungsdienste anbieten, überfüllt, und Sie können viele Unternehmen durch Suchen finden (obwohl sie alle teuer sind). Es scheint also, dass die Theorie, die aufgestellt werden kann, auf dem Markt ist.
Es scheint, dass die Co-Filterung im Allgemeinen durch Korrelation mit dem Jaccard-Koeffizienten realisiert wird. Die Formel zur Berechnung des Jaccard-Koeffizienten für Produkt X und Produkt A lautet wie folgt.
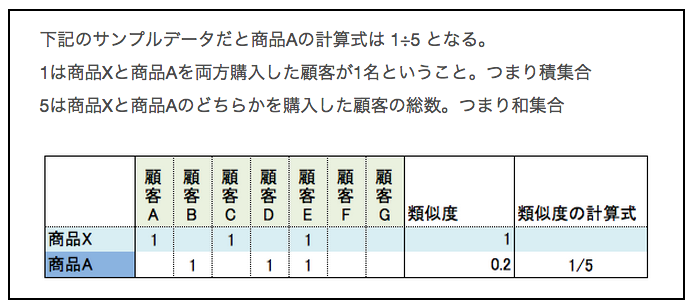
Wenn es also 1 Million Produkte gibt, muss der Jaccard-Koeffizient 1 Million Mal berechnet werden, um die aus Produkt X empfohlenen Produkte zu berechnen. Der Rechenaufwand explodiert. Diese Berechnungsmethode ist nicht realistisch.
Co-Filterung ist eine tote Technologie. Die Vorfahren, die auf die oben genannten Probleme gestoßen sind, haben verschiedene Lösungen angeboten. Amazon hat ein Papier veröffentlicht, das durch die Erstellung eines umgekehrten Index im Jahr 2003 gelöst werden kann.
Reverse-Index-Validierungscode
Beispiele zur Berechnung des Jaccard-Koeffizienten finden Sie im Internet, aber ich kann kein Beispiel finden, das durch Erstellen eines umgekehrten Index gelöst werden kann. Die einzige konkrete Sache, die ich fand, war [Ähnlichkeitsberechnung in Empfehlungen: Trends und Gegenmaßnahmen #DSIRNLP 4. 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji- Lassen Sie uns einen umgekehrten Index erstellen, indem wir uns auf das Material von suan-sofalseqing-xiang-todui-ce-number-dsirnlp-di-4hui-2013-dot-9-1 beziehen.
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
#Produkt ID:10 Käufer
from collections import defaultdict
ITEM_10_BUY_USERS = ['A', 'C', 'E', 'G']
#Kaufhistorie des Käufers(Index umkehren)
INDEX_BASE = 'INDEX_BUY_HISTORY_USER_{}'
INDEX = {
'INDEX_BUY_HISTORY_USER_A': [10, 20, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_B': [20, 20, 50, 60, 70],
'INDEX_BUY_HISTORY_USER_C': [10, 30, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_D': [30, 40, 50, 60],
'INDEX_BUY_HISTORY_USER_E': [10],
'INDEX_BUY_HISTORY_USER_F': [70, 80, 90],
'INDEX_BUY_HISTORY_USER_G': [10, 70, 90],
}
#Berechnen Sie die Ähnlichkeit mit dem umgekehrten Index
result = defaultdict(int)
for user_id in ITEM_10_BUY_USERS:
#Holen Sie sich die Kaufhistorie für jeden Benutzer von INDEX
buy_history = INDEX.get(INDEX_BASE.format(user_id))
#Aggregieren Sie die Anzahl der gekauften Artikel
for item_id in buy_history:
result[item_id] += 1
l = []
for key in result:
l.append((key, result[key]))
#Zeigen Sie die Ähnlichkeit der Ergebnisse
l.sort(key=lambda x: x[1], reverse=True)
print l
>>> [(10, 4), (90, 3), (50, 2), (60, 2), (70, 1), (20, 1), (30, 1)]
Es wurde gefunden, dass die Produkte mit hoher Ähnlichkeit zu Produkt 10 die höchste Korrelation in der Reihenfolge von Produkt 90, Produkt 50 und Produkt: 60 aufweisen. Bei dieser Methode ist der Rechenaufwand kleiner als der Jaccard-Koeffizient, der die Ähnlichkeit mit allen Produkten berechnet, und es scheint möglich zu sein, den Rechenaufwand durch Steuern der Anzahl der Benutzer zu steuern, auf die Bezug genommen wird.
Das Herzstück der Empfehlungs-Engine ist die Aktualisierungsgeschwindigkeit
Zum Beispiel betreiben wir eine Verkaufsstelle mit 1 Million Produkten und 1 Million Benutzern. "Spark", das am 11. März 2015 veröffentlicht wurde, wurde ab dem Veröffentlichungsdatum ein großer Erfolg und verkaufte sich an einem Tag 50.000 Mal. Wenn es viele Produkte gibt, findet einmal pro Woche ein kleines Festival statt. Es scheint also, dass die Aktualisierung der Empfehlungen von 1 Million Produkten direkt zum Umsatz führt.
Der Rechenaufwand ist jedoch enorm. In der Welt des Wettbewerbs können Sie schnell aktualisieren. Als eine für die Empfehlungsmaschine erforderliche Funktion kann es erforderlich sein, einen Mechanismus zu haben, der eine parallele Berechnung ermöglicht. Wenn der Hersteller mir sagt, dass das Aktualisierungsintervall nicht auf 1/4 reduziert werden kann, aktualisiere ich jetzt mit 4 Einheiten. Wenn ich also mit 16 Einheiten rechne, was 4-mal ist, ist es 1/4. Da eine Einheit 50.000 Yen pro Monat kostet, erhöhen sich die monatlichen Kosten um 5 x 12 = 600.000 Yen. Es wäre schön, wenn Sie antworten könnten. (Der Produzent sollte gehen und der Ingenieur sollte in der Lage sein, pünktlich zurückzukehren.)
Ich denke, Redis ist gut für das Backend
Ich denke, Redis ist ein gutes Backend für die Empfehlungs-Engine. Verwelkt, relativ schnell zu lesen, von AWS bereitgestellt und mit einem einzigen Thread kompatibel. Bei ordnungsgemäßer Verwendung sind die Daten also garantiert atomar und die E / A sind schneller als RDS. Es ist auch einfach zu bedienen, da es Bibliotheken von Ruby, PHP, Node.js und Perl gibt. Garantiert Atomic zu sein bedeutet Thread-sicher. Mit anderen Worten wird davon ausgegangen, dass es die Bedingungen erfüllt, die als Backend für die parallele Berechnung verwendet werden können.
- Ich denke, die ideale Implementierung ist eine Methode, bei der das Backend mit data_handler ausgewählt werden kann.
Spezifikation
- Pip Installation ist möglich
- Es hat eine Tag-Funktion und kann für jedes Tag empfohlen werden.
- Die Aktualisierung der empfohlenen Produkte kann parallel ausgeführt werden
- Erhältlich bei Ruby und PHP
- Das Produkt kann gelöscht werden
- Die Kaufhistorie des Benutzers kann bearbeitet werden
- Benutzer kann gelöscht werden
Leistungs Ziel
Mit 1 Million Produkten, 1 Million Benutzern und durchschnittlich 50 Einkäufen pro Benutzer
- Alle Empfehlungsaktualisierungen können innerhalb von 4 Stunden auf einem einzelnen MacBook Pro abgeschlossen werden
- Die Aktualisierung der empfohlenen Produkte sollte innerhalb von 10 Sekunden mit einem MacBook Pro pro Produkt abgeschlossen sein
Ich wünschte, ich könnte es so nennen
[sample]Zum Zeitpunkt der Einführung in das neue System
#Registrieren Sie alle Produkte
for goods in goods.get_all():
Recomender.register(goods.id, tag=goods.tag)
#Registrieren Sie die gesamte Kaufhistorie
for user in user.get_all():
Recomender.like(user.id, user.history.goods_ids)
# sample1.Aktualisieren Sie die Empfehlungen für alle Produkte(Einzelfaden)
Recomender.update_all()
# sample2.Aktualisieren Sie die Empfehlungen für alle Produkte(Multithread-Thread)
Recomender.update_all(proc=4)
# sample3.Aktualisieren Sie die Empfehlungen für alle Produkte(4 parallele Cluster x 4 parallel)
#Paralleler Cluster.1 Erste Hälfte aller Produkte 1/Berechnen Sie 4
Recomender.update_all(proc=4, scope=[1, 4])
#Paralleler Cluster.2 Erste Hälfte aller Produkte 1/Berechnen Sie 4
Recomender.update_all(proc=4, scope=[2, 4])
#Paralleler Cluster.3 Zweite Hälfte aller Produkte 1/Berechnen Sie 4
Recomender.update_all(proc=4, scope=[3, 4])
#Paralleler Cluster.4 Zweite Hälfte aller Produkte 1/Berechnen Sie 4
Recomender.update_all(proc=4, scope=[4, 4])
sample_code
#Neuer Produktzusatz
new_goods_id = 2100
tag = "book"
Recomender.register(new_goods_id, tag=tag)
#Die Person, die dieses Produkt gekauft hat, hat dieses Produkt auch gekauft. Holen Sie sich 5
goods_id = 102
print Recomender.get(goods_id, count=5)
>>> [802, 13, 45, 505, 376]
#Aktualisieren Sie die Empfehlungen für bestimmte Produkte
Recomender.update(goods_id)
#Aktualisieren Sie die Empfehlungen für alle Produkte
Recomender.update_all()
#Herr A ist Ware_IDs kaufen
user_id = "dd841cad-b7cf-473b-9006-77823ad5e006"
goods_ids = [102, 102, 103, 104]
Recomender.like(user_id, goods_ids)
recommendation_data_update
#Produktetikett ändern
new_tag = "computer"
Recomender.change_tag(goods_id, new_tag)
#Produkt löschen
Recomender.remove(goods_id)
#Benutzer löschen
Recomender.remove_user(user_id)
Alles was Sie tun müssen, ist es zu schaffen ... es zu schaffen ... ke .... tsu ......... ke .....
Referenz
- Kooperative Filterung von Toshiyuki Masui
- [Ähnlichkeitsberechnung in Empfehlungen Die Tendenz und Gegenmaßnahmen #DSIRNLP 4. 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji-suan-sofalseqing-xiang-todui-ce- number-dsirnlp-di-4hui-2013-dot-9-1)
- Amazon.com Recommendations Item-to-Item Collaborative Filtering
Es wurde abgeschlossen
Kooperative Filterung RealTime-Empfehlungs-Engine veröffentlicht Ich freue mich darauf, mit Dir zu arbeiten.
Recommended Posts