[PYTHON] Verarbeitung und Beurteilung des Datenanalyseplans (Teil 1)
Bisher habe ich über praktische Methoden der Statistik geschrieben. Wenn Sie jedoch Statistik und messtechnische Ökonomie erwerben, können Sie die Zukunft nacheinander durch Datenanalyse vorhersagen und durch Investitionen in Aktien und dergleichen viel Geld verdienen? Nein, dann sollten sich Statistiker und Ökonomen der Investition in die Forschung widmen und zu diesem Zeitpunkt sehr reich werden.
Random Walker an der Wall Street sagt, dass viele professionelle Fondsmanager die Anlagemethode des zufälligen Kaufs der gesamten börsennotierten Aktie nicht übertroffen haben. Wissenschaftliche empirische Daten werden geschrieben. Die Unvorhersehbarkeit der Zukunft ist aufgrund des komplexen Faktorenmixes sehr schwer vorherzusagen.
Beispielsweise kann medizinische Statistik verwendet werden, um die Korrelation zwischen bestimmter Ernährung und Lebensstil und bestimmten Krankheiten zu untersuchen. Können wir so genau vorhersagen, wann Sie an einer Krankheit sterben werden? Natürlich nicht. Die Datenanalyse kann nicht genau vorhersagen, wann Sie sterben werden.
Mit anderen Worten, kausale Einsichten sind sehr wichtig.
Wenn Sie beispielsweise für Einkauf und Verkauf verantwortlich sind, welche Punkte von Produkten führen wahrscheinlich zu Verkäufen, wenn Sie Verkäufer sind, was sind die entscheidenden Faktoren, die zu Verträgen führen, und wenn Sie ein Personal sind, um Humanressourcen zu entwickeln, die zu den Gewinnen Ihres Unternehmens führen Was ist der Schlüssel, es ist wichtig, diese Punkte aus der Analyse der Daten zu klären.
Und es ist kein Supermann oder eine hexeähnliche Person, die sich selbst als Datenwissenschaftler bezeichnet, der schneidig erscheint und das Problem löst und geht, aber es ist ein Problem aufgrund ständiger täglicher Bemühungen und einiger statistischer Analysen an vorderster Front. Es ist ein Hinweis zu entdecken und zu lösen.
Wenn beispielsweise klar wird, dass ein bestimmtes Produkt zu einem bestimmten Zeitpunkt der Saison verkauft wird, kann die Computeranalyse nur den Schluss ziehen, dass wir mehr von diesem Produkt kaufen sollten. Wenn Sie jedoch eine Person sind, die an Geschäften und Produkten beteiligt war, muss der Kunde beispielsweise tatsächlich nach ~ ~ suchen und so weiter. Am Ende sind menschliche Einsicht und Urteilsvermögen erforderlich, was sehr wichtig ist.
Datenanalyseziel und Analyseplan
Nehmen wir dieses Mal einen Fall als Beispiel und betrachten den Ablauf der tatsächlichen Analyse und Verwendung der Daten.
Ich habe mit Flask in [zuvor] einen Gacha-Emulator erstellt (http://qiita.com/ynakayama/items/536de2f575086685f1de), aber dieses Mal ist das Thema auch ein soziales Spiel. Social Games sind als Materialien vertraut und praktisch, da sie für jeden zugänglich sind und tatsächlich echte Daten sammeln können.
Natürlich spielt es keine Rolle, ob es sich tatsächlich um Filialverkäufe, Verkäuferleistungen oder irgendetwas im sozialen Netzwerk handelt.
Der Umriss ist wie folgt.
- Einige soziale Spiele haben monatliche Veranstaltungen.
- Bei dieser Veranstaltung kämpfen die Teilnehmer um Punktzahlen und werden entsprechend ihrer Rangliste belohnt.
- Ranglistenbelohnungen und Grenzranglisten ändern sich jeden Monat.
Das Verfahren zur Analyse ist wie folgt.
- Klären Sie den Zweck
- Sammeln Sie Daten
- Daten organisieren und verarbeiten
- Erfassen Sie Trends
- Verwenden Sie als Grundlage für die Beurteilung
Klären Sie den Zweck
Warum analysieren Sie dieses Ereignis? Bevor wir die Daten analysieren können, müssen wir zunächst den Zweck klären.
- Nehmen Sie an der Veranstaltung dieses Monats teil
- Prognostizieren Sie die Grenze dieses Monats in gewissem Maße anhand früherer Daten
- Wenn Sie die Grenze vorhersagen können, können Sie den Investitionsbetrag auf das erforderliche Minimum beschränken
Ranking ist ein effektiver Weg, um die Abrechnung in sozialen Spielen voranzutreiben. Angenommen, Sie haben 10.000 weitere Punkte, um die gewünschte Belohnung zu erhalten. Sie müssen nur 1.000 Yen für 10 Artikel bezahlen. Deshalb berechnen wir 1.000 Yen, aber Rivalen denken natürlich genauso und berechnen 1.000 Yen. Dies erhöht die Grenzpunktzahl, sodass sich das Ranking schließlich nicht erhöht.
Es soll ein bisschen mehr sein, ein bisschen mehr, aber es ist ein Mechanismus, bei dem Ihnen eine große Menge Geld berechnet wird, wenn Sie es wiederholen.
Weiter oben im Spielgeist, der Sie dazu bringt, für so etwas eine Gebühr zu erheben Um den bodenlosen Sumpf des Ereignisses zu vermeiden, wird die Grenze der Rangliste irgendwann landen Sagen Sie Ihre Punktzahl bis zu einem gewissen Grad voraus und investieren Sie so viel Geld, wie Sie benötigen, um die endgültige Punktzahl zu erzielen, unabhängig von Ihrem aktuellen Ranking. Der Zweck dieser Analyse ist es, diese Punktzahl so genau wie möglich zu schätzen.
Daten sammeln
In jedem Fall müssen wir Daten sammeln, aber bei der Datenanalyse ist dieser Erfassungsprozess oft eine schwere Belastung.
Hier sind einige Beispieldaten.
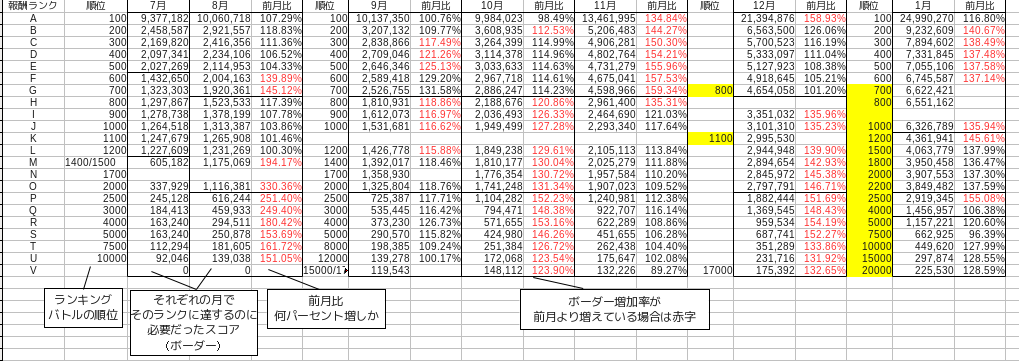
Dies sind Daten, die nur die endgültige Punktzahl des Ereignisses für etwa ein halbes Jahr, dh von Juli letzten Jahres bis Januar dieses Jahres, erfassen.
Die Punktzahl, die jeden Monat zur Grenze wird, schwankt ein wenig, aber im Grunde ist die höchste Belohnung = 100. Platz = Rang A, die obere Belohnung = 700 bis 800. Platz = Rang G und die untere Belohnung = 2000 bis 2200. Platz = Rang O. In der Tabelle sind sie durch schwarze Linien getrennt. Der Rang dient der Vereinfachung und wird nach Ermessen des Autors von oben nach unten als A, B, C zugewiesen. Da die Reihenfolge der Grenzteilung jeden Monat anders ist, stellen Sie sich den Rang von oben vor.
Außerdem ist die Monatsrate ein Prozentsatz, der angibt, um wie viel sich die Punktzahl, die zur Grenze des Rankings wurde, gegenüber dem Vormonat erhöht hat. Dies kann berechnet werden, indem der aktuelle Monat durch den Vormonat geteilt wird.
Daten organisieren und verarbeiten
Selbst das Sammeln von Daten auf diese Weise ist eine ziemliche Belastung. Einige Erfassungsprozesse können jedoch automatisiert werden.
Es besteht jedoch weiterhin Bedarf an einem Prozess zum Organisieren der Daten, selbst nachdem diese in einer Datenbank erfasst wurden, beispielsweise über Sensoren oder automatisierte Tools. Da dies eine Phase der Verarbeitung durch menschliche Hände ist, kann sie nicht vollständig automatisiert werden.
Visualisieren und sehen Sie zunächst den Gesamttrend. Die Visualisierung von Daten ist vorerst ein grundlegender Prozess in den Grundlagen. Die Methode ist die Grundlage für Pandas, daher denke ich, dass sie nicht mehr erklärt werden muss.
df = pd.read_csv("data.csv", index_col=0) #Lesen Sie die Daten
lines = df.interpolate(method="linear") #Füllen Sie die fehlenden Daten aus
plt.figure()
lines.plot() #Zeichnen Sie das Liniendiagramm
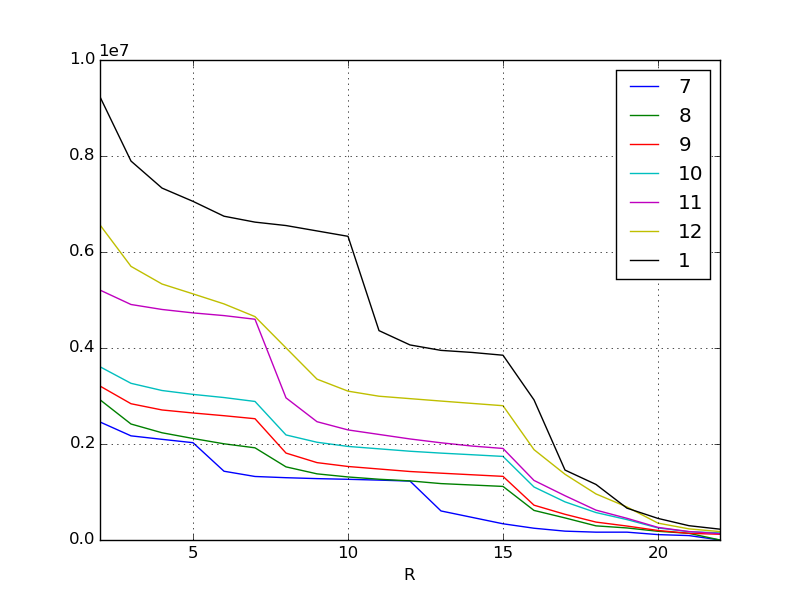
Die X-Achse ist der Rand der Rangfolge. Je höher sie ist, desto höher geht sie nach links. Die Y-Achse ist die Punktzahl. Jede Zeile repräsentiert einen Monat, aber wie Sie auf einen Blick aus den Originaldaten ersehen können, steigt die erforderliche Punktzahl jeden Monat. Insbesondere die jüngste Inflation im Januar und November ist erstaunlich.
Da die Menschen immer mehr Geld ausgeben und stärker werden, werden die Punktzahlen, die sie verdienen, natürlich auch von Monat zu Monat höher. Ich denke, diese Art von Phänomen kann in den meisten sozialen Spielen beobachtet werden. Das Phänomen wurde erneut visualisiert.
Im obigen Beispiel wurden fehlende Werte linear interpoliert. pandas.DataFrame.interpolate kann fehlende Werte basierend auf verschiedenen Kriterien interpolieren und ausfüllen. Es ist eines der mächtigen Merkmale von Pandas.
Fahren Sie mit dem zweiten Teil fort.
Recommended Posts