[PYTHON] Verarbeitung und Beurteilung des Datenanalyseplans (Teil 2)
Schließlich [vorher](http: ///qiita.com/ynakayama/items/b3e3138231f910a0de77) ist diesmal der zweite Teil.
Kehren wir nun wieder zum Ausgangspunkt zurück. Warum Daten sammeln und analysieren? Das liegt daran, dass wir den Gewinn maximieren wollen. Um einen Gewinn zu erzielen, sammeln Sie die Materialien (Daten), die Ihrer Beurteilung zugrunde liegen, organisieren die Inhalte, betrachten sie und verbinden sie mit Ihren Aktionen, um einen Gewinn zu erzielen.
Mit anderen Worten, es gibt ein klares Motiv (Zweck), das zu Gewinn bei der Datenanalyse führt, und Wert wird nur dann geschaffen, wenn das Ergebnis der Analyse mit dem Handeln verknüpft ist.
Spiele und Investitionen
Lassen Sie uns hier über Investitionen sprechen.
Es gibt nicht für jeden die richtige Anlagemethode, aber es gibt einige Voraussetzungen, um beispielsweise einen Marktvorteil bei Aktien zu erzielen.
- Investieren ist ein Wahrscheinlichkeitsspiel
- Der Markt ist im Allgemeinen effizient, es gibt jedoch eine leichte Verzerrung
- Der Kapitalismus verbreitet sich selbst, so dass der Markt langfristig expandieren und die Aktienkurse zum Wirtschaftswachstum konvergieren werden.
Ich denke, das hat etwas mit klassischen artikelbasierten Social Games zu tun. Das heißt, 1. Es ist ein Spiel der Wahrscheinlichkeit, 2. Es gibt Verzerrung (Voreingenommenheit) und 3. Es gibt Inflation. Ob Sie den gewünschten Artikel durch Aufladen erhalten können oder nicht, ist eine Wahrscheinlichkeit. Mit anderen Worten, selbst wenn der gleiche Betrag an "Abrechnung" vorgenommen wird, gibt es eine Verzerrung in der Stärke der resultierenden Verbindung mit den erhaltenen "Gegenständen". Früher oder später werden alle Spieler stärker, was zu Inflation führt, und wenn starke neue Gegenstände eingeführt werden, wird der Wert früherer Gegenstände relativ sinken. Korrekt. Es gibt jedoch Unterschiede je nach System und Verwaltungsrichtlinie.
In jedem Fall gibt es Strategien, um die Wahrscheinlichkeit zu erhöhen, ohne sich auf versehentliche Jackpots zu verlassen. Nehmen Sie zum Beispiel eine Strategie, um die Anzahl der Versuche zu erhöhen. Selbst wenn es ein paar Treffer oder ein paar Treffer gibt, konvergiert es, wenn Sie lange fortfahren, zum Durchschnittswert. Dies ähnelt einer langfristigen Haltestrategie in Bezug auf Aktien. Wenn Sie eine Aktie über einen längeren Zeitraum in der Aktie halten, erhöht sich die Bewertung infolgedessen, selbst wenn es zu einem vorübergehenden Anstieg oder Abfall kommt. [Warren Buffet](http://d.hatena.ne.jp/keyword/%A5%A6%A5%A9%A1%BC%A5%EC%A5%F3%A1%A6%A5%D0%A5 % D5% A5% A7% A5% C3% A5% C8) ist berühmt. Dies ist jedoch eine Geschichte von "Lassen Sie uns eine gute Aktie für eine lange Zeit halten", und ich denke, dass es eine wichtige Voraussetzung ist, dass sich das Unternehmen "langfristig entwickeln" wird, indem es die Marke sorgfältig untersucht. Da zum Beispiel eine genaue Prüfung wichtig ist, ist es eine schlechte Idee, langfristige Aktien in einer sich schnell verändernden Auf- und Ab-Branche zu halten. Auch wenn dies nicht der Fall ist, denke ich, dass die Anzahl der Unternehmen, die zuversichtlich sein können, dass sie sich in dieser unsicheren Zeit langfristig entwickeln werden, recht begrenzt sein wird.
Sparen Sie Geld, um die Anzahl der Versuche zu maximieren
Übrigens, selbst wenn Sie eine Strategie zur Erhöhung der Anzahl der Versuche verfolgen, kostet dies jedes Mal Geld, wenn Sie die Gacha drehen, und es gibt Raum für Einfallsreichtum, wie Sie effizient aufladen können. Es ist leicht zu verstehen, wie die Investition so gering wie möglich gehalten werden kann, indem der Einsatz verschiedener Ressourcen so weit unterdrückt wird, dass die Grenze im Ranking erreicht wird. Es ist wichtig, Grenzen zu identifizieren, anstatt blind zu investieren.
Erinnern wir uns an das vorherige Diagramm. Dies ist die Erhöhung der Punktzahl für die Ereignisse jedes Monats bis zum letzten Monat. Ziel ist es, daraus Trends zu ermitteln und die Punktzahl für das Ereignis im Februar vorherzusagen.
Ergreifen Sie den Trend
Wenn wir uns die visualisierten Daten ansehen, können wir sehen, dass es einige Punkte gibt.
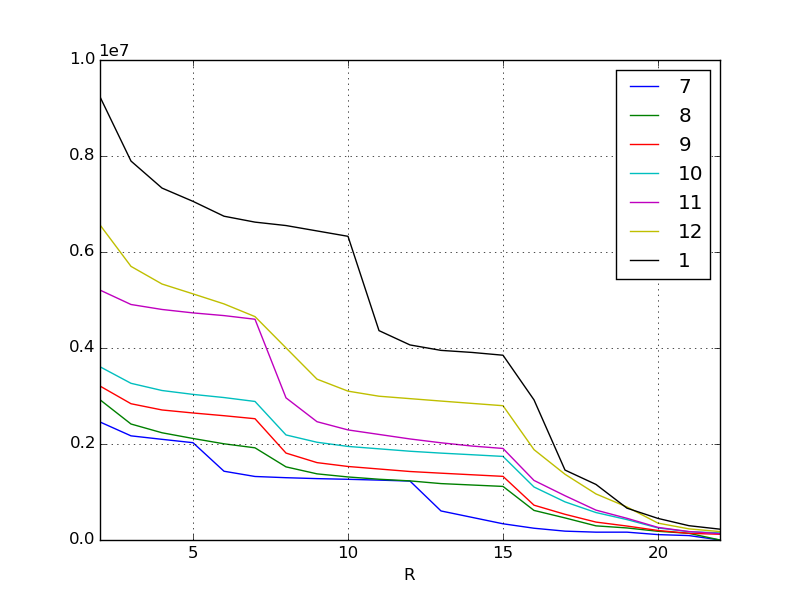
Zum Beispiel gibt es im November eine vertikal gebogene Klippe am höchsten Belohnungsrang. Außerdem gibt es im Januar eine Klippe an der unteren Belohnung. Einige Hypothesen können aufgestellt werden, indem dies und der Inhalt des Ereignisses hinzugefügt werden. Natürlich muss diese Hypothese vom Menschen berücksichtigt werden. Wenn es sich jedoch um ein verbraucherorientiertes Weltereignis handelt, können Sie die Informationen in sozialen Medien und Bulletin Boards verwenden, um die Meinungen der Menschen zu erfassen.
Zum Beispiel im November
- Attraktive neue Charaktere hinzugefügt (Top-Belohnungen sind beliebt, um sicherzustellen, dass Sie sie erhalten)
Oder im Januar
- Unmittelbar zuvor wurde ein neues System eingeführt, um die Effizienz beim Sammeln von Punkten zu verbessern.
- Seit der Ausstrahlung des CM im Winter sind viele neue Abrechnungsgruppen auf den Markt gekommen.
Und so weiter.
In jedem Fall kann gelesen werden, dass es in den Pausen, in denen sich der Inhalt der Belohnung ändert, einen großen Unterschied in der Punktzahl gibt. Wenn jedoch eine solche bemerkenswerte Änderung aufgrund qualitativer Faktoren auftritt, kann die Regressionsgleichung nicht gut abgeleitet werden.
Dieses Mal werden wir nach Beginn der Veranstaltung die täglichen Ergebnisse für den aktuellen Monat (Februar) aggregieren und untersuchen, wie sie mit den letzten drei Monaten verglichen wurden.
Explorative Datenanalyse
Bei der explorativen Datenanalyse werden Daten aus verschiedenen Blickwinkeln betrachtet, um "geeignete Zwecke und Hypothesen zu ermitteln".
Ursprünglich habe ich wiederholt betont, dass die Datenanalyse einen klaren Zweck und eine klare Hypothese erfordert, aber in erster Linie in Situationen, in denen das Analyseziel nicht über die erforderlichen Kenntnisse verfügt oder der tatsächliche Zustand des Ziels nicht gut verstanden wird Es ist notwendig, einen Blick auf die Daten zu werfen, um den Zweck und die Hypothese von zu erhalten. Dies ist ein Ansatz, der in der Welt der Statistik als explorative Datenanalyse bezeichnet wird.
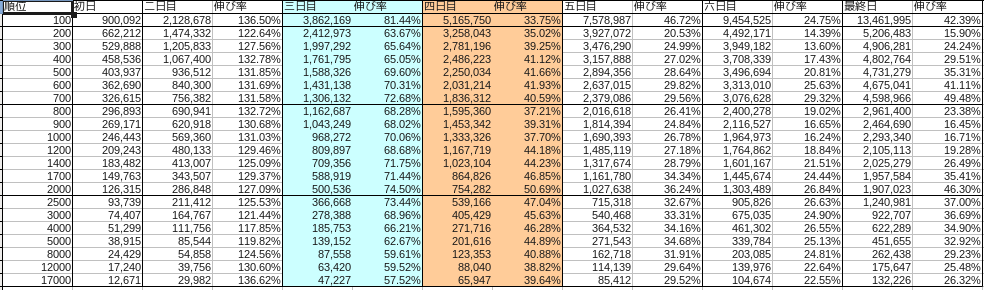
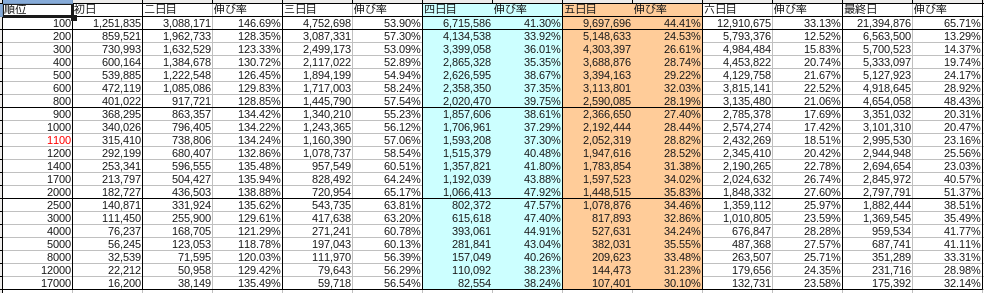
Die Aufteilung jedes Monats war wie folgt.
November
Dezember
Januar
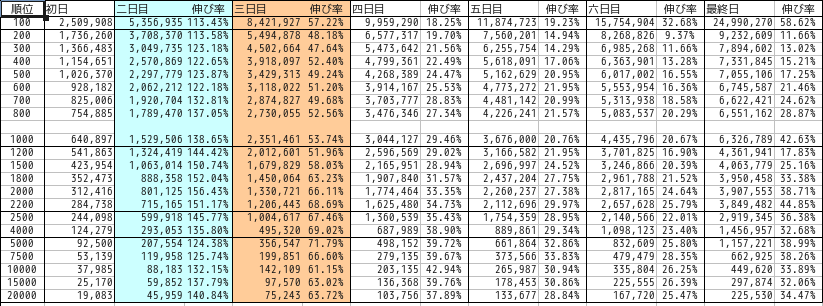
Blau steht für Samstag und Rot für Sonntag.
Lassen Sie uns zunächst das Ziel auf die höchste Belohnung als Ziel eingrenzen. Wir werden den Übergang des Grenzwerts, der die höchste Belohnung eines jeden Monats darstellt, als Datensatz verwenden. IPython ist weiterhin nützlich, um die explorative Datenanalyse voranzutreiben.
Hier wird davon ausgegangen, dass der Februar bis zur Mitte der Veranstaltung (Tag 4) vergangen ist.
#Schneiden Sie Daten zu den besten Belohnungen für jeden Monat aus
df201411 = pd.read_csv("201411.csv", index_col=0)
df201412 = pd.read_csv("201412.csv", index_col=0)
df201501 = pd.read_csv("201501.csv", index_col=0)
df201502 = pd.read_csv("201502.csv", index_col=0)
#Extrahieren Sie die obersten Belohnungslinien in eine Reihe
s201411 = df201411.ix[700, :]
s201412 = df201412.ix[800, :]
s201501 = df201501.ix[1000, :]
s201502 = df201502.ix[1000, :]
#Der Einfachheit halber Index zur Nummer
s201411.index = np.arange(1, len(s201411) + 1)
s201412.index = np.arange(1, len(s201412) + 1)
s201501.index = np.arange(1, len(s201501) + 1)
s201502.index = np.arange(1, len(s201502) + 1)
#Verketten Sie die Serien jedes Monats zu einem Datenrahmen
df = pd.concat([s201411, s201412, s201501, s201502], axis=1)
#Machen Sie Spaltennummern
df.columns = [11, 12, 1, 2]
#Visualisieren
df.plot()
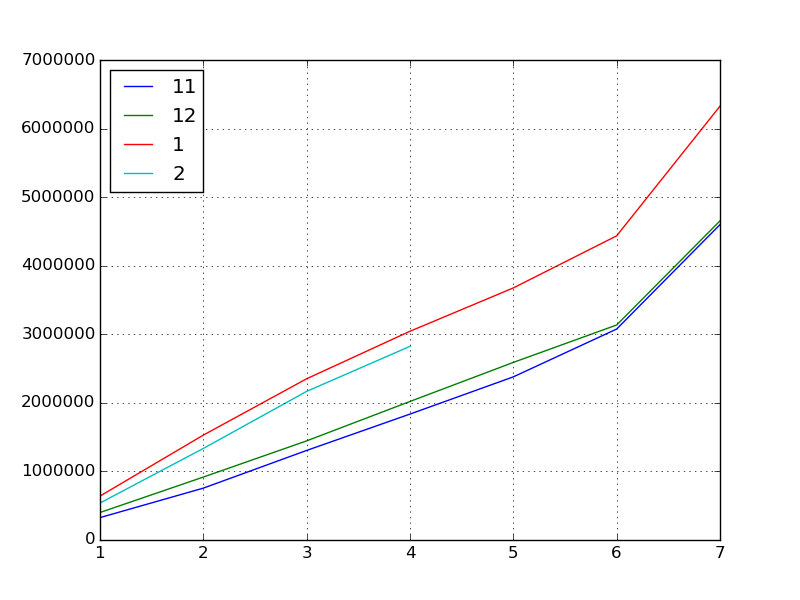
Als nächstes finden wir die grundlegenden Statistiken.
#Grundlegende Statistiken
df.describe()
#=>
# 11 12 1 2
# count 7.000000 7.000000 7.000000 4.000000
# mean 2040017.285714 2166375.142857 3143510.857143 1716607.750000
# std 1466361.613186 1444726.064645 1897020.173703 993678.007807
# min 326615.000000 401022.000000 640897.000000 539337.000000
# 25% 1031257.000000 1181755.500000 1940483.500000 1136160.000000
# 50% 1836312.000000 2020470.000000 3044127.000000 1751315.500000
# 75% 2727857.000000 2862782.500000 4055898.000000 2331763.250000
# max 4598966.000000 4654058.000000 6326789.000000 2824463.000000
#Korrelationskoeffizient
df.corr()
#=>
# 11 12 1 2
# 11 1.000000 0.999157 0.996224 0.996431
# 12 0.999157 1.000000 0.998266 0.997345
# 1 0.996224 0.998266 1.000000 0.999704
# 2 0.996431 0.997345 0.999704 1.000000
#Mitverteilt
df.cov()
#=>
# 11 12 1 2
# 11 2.150216e+12 2.116705e+12 2.771215e+12 6.500842e+11
# 12 2.116705e+12 2.087233e+12 2.735923e+12 6.893663e+11
# 1 2.771215e+12 2.735923e+12 3.598686e+12 1.031584e+12
# 2 6.500842e+11 6.893663e+11 1.031584e+12 9.873960e+11
Was können wir hier lernen?
- Punktzahl "Inflation" beschleunigt sich im November, Dezember und Januar stetig.
- Besonders im Januar (was aus dem Korrelationskoeffizienten abgelesen werden kann)
- Es wurde im letzten Monat aufgeblasen, daher wird es möglicherweise auch im Februar aufgeblasen.
Vier Tage nach dem eigentlichen Beginn der Veranstaltung im Februar, als ich den Deckel öffnete, sank die Punktzahl.
Dies wurde noch nie getan, einschließlich der Daten, die beim letzten Mal veröffentlicht wurden. Es ist seit langer Zeit gestiegen (Inflation), aber es ist gefallen.
Wir werden wieder einige Hypothesen aufstellen.
- Diesen Monat gab es viele sogenannte Sammlungsveranstaltungen wie spezielle Gachas
- Winter CM Neueinsteiger nahmen im Januar an der Veranstaltung teil, ohne genügend Kraft zu haben, und führten einen unvernünftigen Kampf und brannten aus
- Die Industrie geht jeden Februar zurück
- Zehn Monate sind vergangen, seit der Dienst gestartet wurde, und viele Leute haben 10 Belohnungsgegenstände, und der Wettbewerb hat sich verlangsamt, da sie 10 Decks gefüllt haben.
- Alle haben angefangen zu sparen, weil der letzte Monat überfüllt war
Es gibt viele Möglichkeiten.
Da der Korrelationskoeffizient jedoch für jedes Wachstum in jedem Monat hoch ist, kann beurteilt werden, dass es gut erscheint, den Score am Ende des Ereignisses anhand des täglichen Wachstums in den letzten 3 Monaten vorherzusagen.
Erfassen Sie die Zunahme und Abnahme der Punktzahl
Daher können wir das Wachstum dieser Punktzahl als ** prozentuale Veränderung ** erfassen.
Anstiegs- / Abfallrate ist eine Anlagedauer und ein Indikator für Preisschwankungen. Vergleichen Sie die beiden Zeitpunkte, um festzustellen, um wie viel Prozent der Wert des Fonds steigt oder fällt. Berechnen wir hier die Zu- / Abnahmerate, indem wir die Erhöhung der Punktzahl als Muster für Änderungen des Fondspreises betrachten.
#Wachstumsrate vom Vortag
df.pct_change()
#=>
# 11 12 1 2
# 1 NaN NaN NaN NaN
# 2 1.315821 1.288455 1.386508 1.475449
# 3 0.726815 0.575413 0.537399 0.623495
# 4 0.405916 0.397485 0.294568 0.303079
# 5 0.295578 0.281922 0.207571 NaN
# 6 0.293197 0.210570 0.206691 NaN
# 7 0.494807 0.484321 0.426303 NaN
#Bei der Umsetzung wird es die Wachstumsrate des Vormonats
df.T.pct_change()
#=>
# 1 2 3 4 5 6 7
# 11 NaN NaN NaN NaN NaN NaN NaN
# 12 0.227813 0.213304 0.106925 0.100287 0.088689 0.019129 0.011979
# 1 0.598159 0.666635 0.626419 0.506643 0.419258 0.414710 0.359413
# 2 -0.158465 -0.127103 -0.078220 -0.072160 NaN NaN NaN
Die Wachstumsrate vom Vortag ist in jedem Monat gleich. Wir können sehen, dass die Wachstumsrate leicht variiert, je nachdem, ob es sich um einen Feiertag oder einen Wochentag handelt. Die Wachstumsrate ist jedoch am zweiten Tag am höchsten, verlangsamt sich dann und wächst am letzten Tag um 40 bis 50%.
Betrachtet man das Wachstum des Vormonats am selben Tag, so ist der Februar negativ geworden.
pct_change = df.T.pct_change() #Wachstumsrate gegenüber dem Vormonat
def estimated_from_reference(day):
return df.ix[7, 1] * (1 + df.T.pct_change().ix[2, day])
estimated = [estimated_from_reference(x) for x in range(1, 7)]
print(estimated)
#=>
[5324211.8451061565, 5522634.3150592418, 5831908.3162212763, 5870248.3304103278, nan, nan]
#Erwartete endgültige Grenzbewertung basierend auf Tag 1, Tag 2, Tag 3 und Tag 4
Ich habe es so verstanden.
Oder Sie können nach den Ergebnissen für den kommenden 5., 6. und letzten Tag fragen.
def estimated_from_perchange(criteria, day):
return df.ix[criteria, 2] * (1 + df.pct_change().ix[day, 1])
#Berechnen Sie die Punktzahl am 5. Februar aus der Rate der Zunahme / Abnahme am 4. bis 5. Januar
df.ix[5, 2] = estimated_from_perchange(4, 5)
#=> 3410740.086731
#Auch am 6. Tag
df.ix[6, 2] = estimated_from_perchange(5, 6)
#=> 4115709.258368
#Letzter Tag
df.ix[7, 2] = estimated_from_perchange(6, 7)
#=> 5870248.330410
Dies füllt die fehlenden Werte im Datenrahmen aus. Daraus konnte vorhergesagt werden, dass ab dem 4. Tag 5,87 Millionen Punkte die Grenze der Top-Belohnungen darstellen würden.
Verwenden Sie als Grundlage für die Beurteilung
Übrigens waren die richtigen Antwortdaten am 5. Tag 3487426 Punkte (102,2% des vorhergesagten Wertes am 4. Tag), am 6. Tag 4094411 Punkte (99,5%) und am letzten Tag 5728959 Punkte (97,5%). Wenn Sie also 5,87 Millionen Punkte haben, können Sie es sich leisten. Das Ergebnis ist, dass Sie die höchste Belohnung gewonnen haben.
| Tage | Prognose | Ergebnis | Unterschied |
|---|---|---|---|
| Tag 5 | 3410740 | 3487426 | 102.2% |
| Tag 6 | 4115709 | 4094411 | 99.5% |
| Letzter Tag | 5870248 | 5728959 | 97.5% |
Die Ergebnisse der explorativen Datenanalyse können in Leistungsstarke Funktionen von IPython programmiert und gespeichert werden, sodass sie täglich berechnet werden, während der Fortschritt des Ereignisses verfolgt wird. Es wurde gezeigt, dass Grenzen mit extrem hoher Genauigkeit vorhergesagt werden können.
schließlich
In der Welt der Investitionen [Anstiegs- und Abfallverhältnis](http://ja.wikipedia.org/wiki/%E9%A8%B0%E8%90%BD%E3%83%AC%E3%82%B7%E3%82 Es gibt einen Index namens% AA). Dies ist ein kurzfristiger Indikator für das Verhältnis der Zu- / Abnahmerate zu allen Beständen. An diesem technischen Indikator können Sie ablesen, ob die Aktie überkauft ist.
Werfen wir einen Blick auf den Nikkei-Durchschnitt vom 4. März 2015.
Anstiegs- und Abfallverhältnis Nikkei durchschnittliche Vergleichstabelle http://nikkei225jp.com/data/touraku.html
An diesem Tag gingen die Verkäufe voraus und der Nikkei-Durchschnitt fiel am Morgen um 200 Yen. Wenn Sie sich das Auf- und Ab-Verhältnis kurz zuvor ansehen, sehen Sie tatsächlich eine sehr hohe Zahl von 130 bis 140. Dies deutet im Wesentlichen darauf hin, dass der Markt bullisch und überkauft ist, und ist ein Zeichen dafür, dass der Nikkei-Durchschnitt danach sinken wird. Nach dem tatsächlichen Rückgang von 200 Yen kehrte der Verhältniswert in den normalen Bereich zurück, und Rückkäufe erfolgten und erholten sich.
Auf diese Weise kann gesagt werden, dass gemeinsame Methoden auf die grundlegenden Teile sowohl der numerischen Analyse einer kleinen Welt wie eines Spiels als auch der Analyse einer großen Welt der Finanzwirtschaft angewendet werden können. Natürlich kann es aufgrund plötzlicher Kataklysmen zu unvorhergesehenen Umständen kommen, aber die Haltung, Dinge täglich wissenschaftlich zu analysieren, ist sehr wichtig.
Recommended Posts