Das Deep Learning-Framework "CNTK" von Microsoft ist jetzt mit Python kompatibel, was die Verwendung erheblich vereinfacht
Kennen Sie CNTK? Für diejenigen, die bereits eine Art Deep Learning-Framework verwendet haben, sagen die meisten von ihnen: "Ich weiß, dass MS da draußen ist ...".
Wenn ich Leute um mich herum frage, scheinen die Lernkosten für diejenigen hoch zu sein, die Artikel gesehen haben, die in DSL geschrieben wurden, bevor die Version veröffentlicht wurde. Es scheint, dass es ziemlich viele Menschen gibt, die nicht verstehen, welche Funktionen sie haben, weil es überhaupt nur wenige japanische Dokumente über CNTK gibt.
Daher möchte ich in diesem Artikel CNTK vorstellen, das einfacher zu verwenden ist, weil es mit Python kompatibel ist, indem Schlüsselwörter wie seine Funktionen und Unterschiede zu anderen Frameworks eingestreut werden.
"Open-source, Cross-platform Toolkit"
Offene Entwicklungsumgebung
Es ist Open Source und wird derzeit unter on GitHub entwickelt.
Plattformübergreifende Entwicklungsumgebung
Verfügbar unter Linux und Windows. Docker für Linux (https://hub.docker.com/r/microsoft/cntk/) ist ebenfalls verfügbar.
Diverse Schnittstellen
Folgendes wird derzeit unterstützt:
- C++
- Brainscript
- Python (NEW!)
Es wurde im Oktober 2016 auf Version 2.0 aktualisiert und schließlich wird auch Python unterstützt! (Tränen) Ich denke, viele Ingenieure, die maschinelles Lernen verwenden, sind Python-Benutzer, daher kann C ++ trotzdem mit Brainscript verwendet werden! Selbst wenn gesagt wird, sollten ungefähr 132 von 100 Menschen "Burein Sukuriputo ... ??" sein. Ich denke jedoch, dass die Lernkosten dank Pythons Unterstützung sofort gesunken sind.
"Scalability"
Ich denke, das Attraktivste an CNTK ist seine Skalierbarkeit.
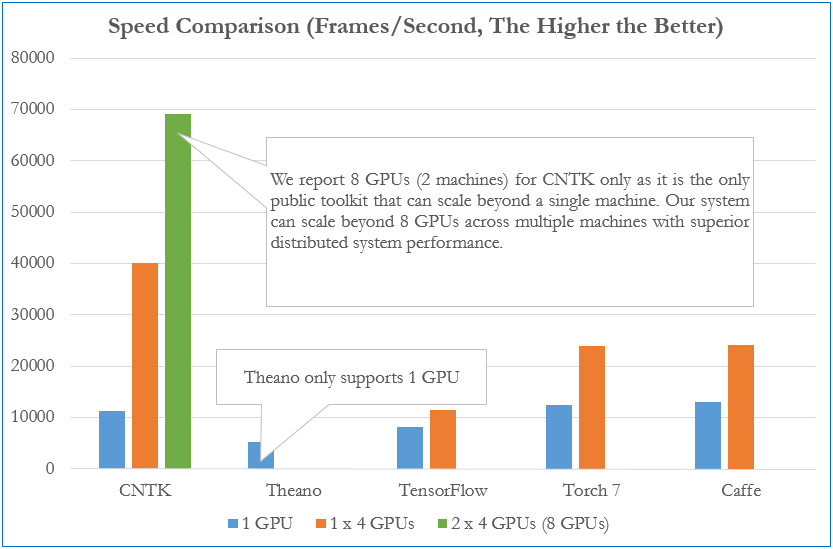
Die obige Abbildung ist ein Vergleich der Lerngeschwindigkeiten für jedes Framework (*). Wir vergleichen, wie viele Frames pro Sekunde von einem vollständig verbundenen 4-Schicht-Neuronalen Netzwerk verarbeitet werden können. Mit einer GPU ist die Geschwindigkeit für jedes Framework nahezu gleich, aber mit mehreren Computern / mehreren GPUs können Sie feststellen, dass CNTK überwiegend höher ist als die anderen.
- Vergleich Stand Dezember 2015
 "Benchmarking State-of-the-Art Deep Learning Software Tools"
"Benchmarking State-of-the-Art Deep Learning Software Tools"
Darüber hinaus ist dies ein Benchmark für vollständig verbundenes AlexNet, ResNet und LSTM (*). Sie können sehen, dass CNTK die schnellste Leistung bei Full Join und LSTM aufweist. Übrigens war AlexNet mit Caffe am schnellsten und ResNet mit Torch am schnellsten. Der Benchmark zeigt auch, dass CNTK bei allen Modellen Vorreiter im Deep Learning-Framework ist und den bekanntesten TensorFlow übertrifft. (Das war ziemlich überraschend ...)
- Vergleich Stand August 2016
"Efficient network authoring" CNTK hat Folgendes entwickelt, um ein neuronales Netzwerk so effizient und einfach wie möglich zu erstellen.
- ** Kompositionsfähigkeit, mit der Sie jedes neuronale Netzwerk aufbauen können, indem Sie einfache Komponenten kombinieren **
- ** Behandle das neuronale Netzwerk als Funktionsobjekt **
Angenommen, ein neuronales Netzwerk mit Vorwärtsausbreitung mit zwei verborgenen Schichten wird durch eine mathematische Formel wie folgt ausgedrückt.

In CNTK können Sie in einer Form schreiben, die einer mathematischen Formel ähnelt.
h1 = Sigmoid(W1 * x + b1)
h2 = Sigmoid(W2 * h1 + b2)
P = Softmax(Wout * h2 + bout)
ce = CrossEntropy(y, P, tag='criterion')
Da CNTK neuronale Netze als Funktionsobjekte behandelt, ist es sehr kompatibel mit der Beschreibung neuronaler Netze (einschließlich tiefer neuronaler Netze), die sehr große und komplexe "Funktionen" sind. Dank der Python-Unterstützung können Sie die Struktur Ihres neuronalen Netzwerks präziser schreiben.
Das Folgende ist beispielsweise ein Beispielbild eines CNN-Netzwerks (Convolutional Neural Network), das üblicherweise in Bilderkennungssystemen verwendet wird.
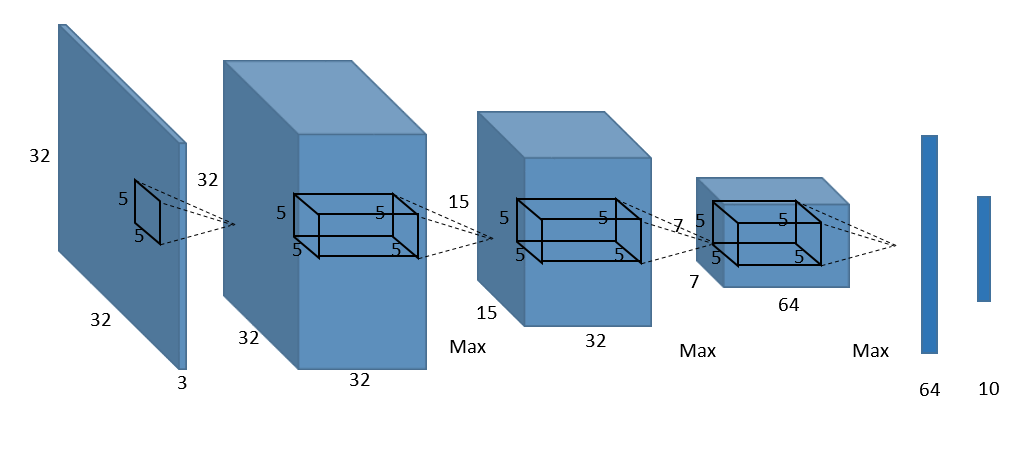
Wenn Sie die obige Netzwerkkonfiguration direkt in CNTK schreiben,
def create_basic_model(input, out_dims):
net = Convolution((5,5), 32, init=glorot_uniform(), activation=relu, pad=True)(input)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Convolution((5,5), 32, init=glorot_uniform(), activation=relu, pad=True)(net)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Convolution((5,5), 64, init=glorot_uniform(), activation=relu, pad=True)(net)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Dense(64, init=glorot_uniform())(net)
net = Dense(out_dims, init=glorot_uniform(), activation=None)(net)
return net
Sie können so schreiben. Dies macht den Code jedoch redundanter, wenn die Anzahl der verborgenen Schichten zunimmt. Wie ich bereits sagte, konzentriert sich CNTK so auf *** Composability ***, dass Sie es einfacher und effizienter schreiben können:
def create_model(input, out_dims):
with default_options(activation=relu):
model = Sequential([
For(range(3), lambda i: [
Convolution((5,5), [32,32,64][i], init=glorot_uniform(), pad=True),
MaxPooling((3,3), strides=(2,2))
]),
Dense(64, init=glorot_uniform()),
Dense(out_dims, init=glorot_uniform(), activation=None)
])
return model(input)
Verwenden Sie Sequential (), um jede Ebene zu gruppieren, die in einer horizontalen geraden Linie verbunden ist. Wenn Sie dieselbe Aktivierungsfunktion oder Verzerrung in mehreren Ebenen verwenden möchten, verwenden Sie default_options (), um die vorherige zu implementieren. Ich kann das Netzwerk effizienter schreiben als das Beispiel.
Außerdem werden in CNTK Komponenten wie CNN, ResNet und RNN, die im Allgemeinen verwendet werden, als APIs (*) vorbereitet, sodass es sehr für ** "diejenigen geeignet ist, die das neuronale Netzwerk selbst bis zu einem gewissen Grad verstehen" **. Es ist ein Mechanismus, der es einfach macht.
- Ich habe eine typische Python-API für CNTK als [Anhang] unten geschrieben. Überprüfen Sie daher bitte, was verfügbar ist, wenn Sie möchten.
"Efficient execution"
Wie oben erwähnt, ist einer der Vorteile der Verwendung von CNTK eine hohe Leistung, wie z. B. eine schnelle Lerngeschwindigkeit während des Trainings und die effiziente Verwendung mehrerer GPUs. Diese sind jedoch für CNTK wie folgt einzigartig. Weil es die Funktion hat.
- ** In Grafikdarstellung konvertieren und lernen **
- ** Proprietärer paralleler Lernalgorithmus **
Lernen Sie, indem Sie in eine Diagrammdarstellung konvertieren
h1 = Sigmoid(W1 * x + b1)
h2 = Sigmoid(W2 * h1 + b2)
P = Softmax(Wout * h2 + bout)
ce = CrossEntropy(y, P, tag='criterion')
Ich werde das neuronale Netzwerk mit Vorwärtsausbreitung mit zwei verborgenen Schichten nachdrucken, die ich zuvor als Beispiel genommen habe. In CNTK wird das obige Skript zunächst in eine Darstellung namens Berechnungsdiagramm konvertiert, wie unten gezeigt.

Zu diesem Zeitpunkt sind die Knoten im Diagramm Funktionen und die Kanten sind die Werte. Indem Sie zuerst auf diese Weise in eine Diagrammdarstellung konvertieren,
- ** Lernen durch automatische Differenzierung **
- ** Voroptimierung reduziert Laufzeitspeicher und Berechnungskosten **
Kann realisiert werden.
Ausgestattet mit einem einzigartigen parallelen Lernalgorithmus
Block-Momentum SGD

Ab CNTK Version 1.5 [Block-Momentum SGD](https://www.microsoft.com/en-us/research/publication/scalable-training-deep-learning-machines-incremental-block-training-intra-block- Es implementiert eine Technologie namens Parallel-Optimierung-Block-Modell-Update-Filterung /).
Dies eliminiert die Kommunikationskosten zwischen GPUs erheblich und ermöglicht schnellere Geschwindigkeiten über mehrere GPUs hinweg, während die Genauigkeit erhalten bleibt.
In der oben gezeigten Aufgabe war die Ausführung auf 64 GPU-Clustern mehr als 50-mal besser als auf einem.
1-bit SGD Der Engpass bei der verteilten Verarbeitung auf der GPU sind die Kommunikationskosten. CNTK ist jedoch 1-Bit-SGD -training-of-language-dnns /), eine Technologie, die Kommunikationskosten durch Quantisierung des Gradienten auf 1 Bit eliminieren kann. Infolgedessen kann die Lerngeschwindigkeit während des Trainings des neuronalen Netzwerks verbessert werden, so dass die Kommunikationskosten bei der Durchführung der Parallelverarbeitung erheblich reduziert werden können.
abschließend
Was haben Sie gedacht. Ich habe die Funktionen von CNTK mit ein paar Punkten vorgestellt, aber ich denke, Sie haben es vielleicht nicht gewusst. Was ist diesmal CNTK? Da ich mich darauf konzentriert habe, habe ich mich nicht mit dem Erstellen der Umgebung befasst, aber die Unterstützung für Python hat das Erstellen der Umgebung viel einfacher gemacht. Außerdem ist das Jupyter Notebook-basierte Tutorial sehr umfangreich. Wenn Sie also nach dem Lesen dieses Artikels an CNTK interessiert sind, versuchen Sie es bitte mit CNTK im Tutorial! Wenn Sie Fragen zur Umgebungskonstruktion oder zum Lernprogramm haben, Führen Sie eine Stilkonvertierung mit MS Deep Learning Framework CNTK durch. Was ist, wenn Sie Goch in der Grundschule zeichnen lassen? und Tutorial "CNTK" der Microsoft Deep Learning Library werden ausführlich beschrieben. Bitte schauen Sie dort.
Es wäre großartig, wenn die Anzahl der Personen, die diesen Artikel lesen und sagen: "Lassen Sie uns CNTK für einen Moment berühren", so weit wie möglich zunehmen würde! :) :)
[Anhang] Beispiel einer Python-API für CNTK
- basic blocks:
- LTSM(), GRU(), RNNUnit()
- ForwardDeclaration(), Tensor[], SparseTensor[], Sequence[], SequenceOver[]
- layers:
- Dence(), Embedding()
- Convolution(), Convolution1D(), convolution3D(), Deconvolution()
- MaxPooling(), AveragePooling(), GlobalMaxPooling(), GlobalAveragePooling(), MaxUnpooling()
- BatchNormalization(), LayerNormalization()
- Dropout(), Activation()
- Label()
- composition:
- Sequential(), For()
- ResNetBlock(), SequentialClique()
- sequences:
- Delay(), PastValueWindows()
- Recurrence(), RecurrencFrom(), Fold(), UnfoldFrom()
- models:
- AttentionModel()