[PYTHON] Häufig verwendete Unterpakete von SciPy
SciPy ist eine Sammlung vieler mathematischer Algorithmen und nützlicher Funktionen, die auf NumPy basiert und eine Erweiterung davon darstellt. Heute werde ich einige der riesigen SciPy-Unterpakete untersuchen, die häufig verwendet werden und nützlich sind. Ich werde.
Die Unterpakete enthalten: Jedes dieser Elemente kann über den scipy-Import PACKAGE_NAME aufgerufen werden. (Es gibt andere Möglichkeiten, dies zu tun)
| Paket | Inhalt |
|---|---|
| cluster | Clustering-Algorithmus |
| constants | Physikalische Konstanten und mathematische Konstanten |
| fftpack | Schnelle Fourier-Transformationsroutine |
| integrate | Integration und normale Differentialgleichungen |
| interpolate | Interpolation und Glättung von Splines |
| io | Ein- und Ausgabe |
| linalg | Lineare Algebra |
| ndimage | N-dimensionale Verarbeitung |
| odr | Orthogonale Distanzregression |
| optimize | Routine zur Optimierung und Wurzelerkennung |
| signal | Signalverarbeitung |
| sparse | Routinen, die mit spärlichen Matrizen verbunden sind |
| spatial | Geodatenstruktur und Algorithmen |
| special | Besondere Merkmale |
| stats | Statistische Verteilung und Funktion |
| weave | C/C++Integration |
Nach meinem eigenen Ermessen und Vorurteil sind die am häufigsten verwendeten Unterpakete scipy.stats und scipy.linalg. .
Statistische Funktion (scipy.stats)
scipy.stats ist ein Unterpaket für Statistiken. Erstens gibt es zwei allgemeine Klassen, die kontinuierliche und diskrete Wahrscheinlichkeitsvariablen kapseln. Basierend darauf verfügt SciPy über Klassen für über 80 kontinuierliche stochastische Variablen und über 10 diskrete probabilistische Variablen. Diese überwiegend statistischen Klassen sind unter scipy.stats organisiert.
Übliche Methoden für kontinuierliche stochastische Variablen sind:
| Methode | Inhalt |
|---|---|
| rvs | Zufällige Variable |
| Wahrscheinlichkeitsdichtefunktion | |
| cdf | Verteilungsfunktion |
| sf | Überlebensfunktion (1-CDF) |
| ppf | Prozentfunktion (invers zu CDF) |
| isf | Reverse Survival-Funktion (invers zu SF) |
| stats | Mittelwert, Streuung, Fisher-Schärfe, Wahrscheinlichkeit |
| moment | Dezentrale Produktquote |
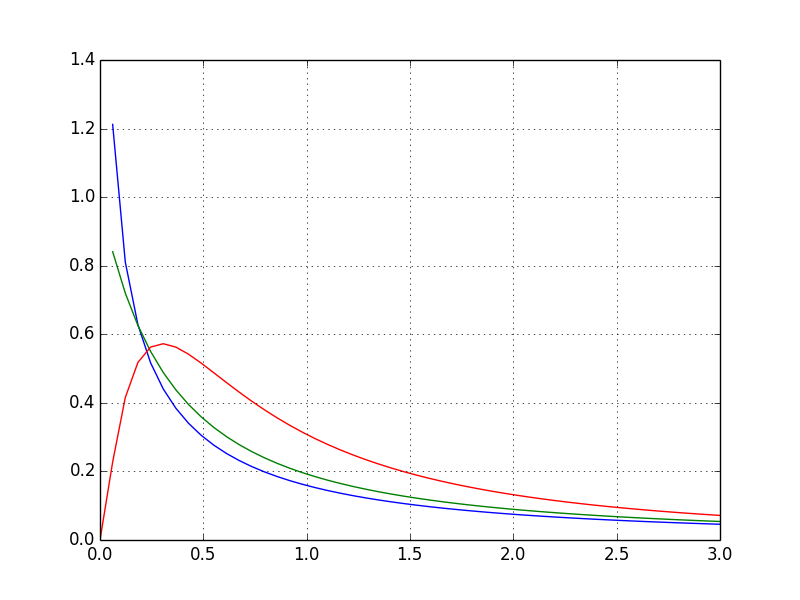
F Verteilung
Es ist eine bekannte F-Verteilung.
from scipy.stats import f #Rufen Sie die F-Verteilung aus den Statistiken auf
def draw_graph(dfn, dfd):
rv = f(dfn, dfd) #Zeichnen Sie eine F-Verteilung mit den beiden angegebenen Argumenten
x = np.linspace(0, np.minimum(rv.dist.b, 3))
plt.plot(x, rv.pdf(x))
draw_graph(1, 1)
draw_graph(2, 1)
draw_graph(5, 2)
z Punktzahl
Es kann wie folgt erhalten werden.
x = np.array([61, 74, 55, 85, 68, 72, 64, 80, 82, 59])
print(stats.zscore(x))
#=> [-0.92047832 0.40910147 -1.53413053 1.53413053 -0.20455074 0.20455074
# -0.61365221 1.02275369 1.22730442 -1.12502906]
Lineare Algebra (scipy.linalg)
Sehr schnelle lineare Algebra-Berechnungen mit BLAS und LAPACK ..
Alle linearen algebraischen Routinen setzen ein Objekt voraus, das in ein zweidimensionales Array konvertiert werden kann. Die Ausgabe dieser Routinen ist im Grunde auch ein zweidimensionales Array.
x = np.array([[1,2],[3,4]])
linalg.inv(x)
#=>
# array([[-2. , 1. ],
# [ 1.5, -0.5]])
Zusammenfassung
Die Unterpakete von SciPy haben eine Vielzahl von Funktionen und sind alles andere als erklärbar. Wenn Sie interessiert sind, lesen Sie bitte die Online-Dokumente.
Wenn Sie mit der Online-Dokumentation nicht zufrieden sind, können Sie auch auf Kostenlose Bücher, die früher eingeführt wurden verweisen.
Recommended Posts