[PYTHON] Pfeffer-Tutorial (7): Bilderkennung
Inhalt dieses Tutorials
In diesem Tutorial werden die Spezifikationen und das Verhalten der Bilderkennung durch Pepper anhand von Beispielen erläutert.
- Bildbezogene Spezifikationen
- So überprüfen Sie das Bild mit Choregraphe
- Grundlegende Gesichtsbehandlung
- Lernen und Diskriminierung im Gesicht
- Bildlernen und Diskriminierung
** Für die Bilderkennung gibt es keine Betriebsbestätigungsmethode für virtuelle Roboter, und eine tatsächliche Pepper-Maschine ist erforderlich. ** Ich möchte, dass Sie mit der eigentlichen Pfeffermaschine im Aldebaran Atelier Akihabara experimentieren. (Reservierungs-URL: http://pepper.doorkeeper.jp/events)
Verschiedene Sensorspezifikationen
Die Spezifikationen für die Bildverarbeitung von Pepper lauten wie folgt.
- 2D-Kamera x 2 (Stirn ** [A] **, Mund ** [B] **) ... Ausgabe 1920 x 1080, 15 fps
- 3D-Kamera (Infrarotbestrahlung: ** [C] **, Infrarotdetektion: ** [D] **) ... ASUS Xtion 3D-Sensor, Ausgang 320 × 240, 20 fps

Pepper verwendet diese Kameras, um Personen und Objekte zu erkennen.
So überprüfen Sie das Bild mit Choregraphe
Sie können die Informationen des von Peppers Kamera aufgenommenen Bildes in Choregraphe überprüfen.
Bestätigung durch das Videomonitorfeld
Verwenden Sie das Videomonitorfeld für Vorgänge im Zusammenhang mit Pepper-Bildern. Das Videomonitorfenster befindet sich normalerweise im selben Bereich wie die Pose-Bibliothek und kann durch Auswahl der Registerkarte Videomonitor angezeigt werden. Wenn Sie es nicht finden können, wählen Sie [Videomonitor] aus dem Menü [Ansicht].

Das Videomonitorfenster bietet die Möglichkeit, Bilder von Peppers Kamera anzuzeigen sowie die unten beschriebene visuelle Erkennungsdatenbank zu verwalten.
- Kamerabild ... Sie können den Inhalt der Pepper-Kamera überprüfen
- Wiedergabe / Pause-Taste ... Wiedergabe, um das aktuelle Kamerabild in Echtzeit anzuzeigen. Sie können dies mit einer Pause beenden
- Schaltfläche für den Lernmodus ... Wechseln Sie in den Bildlernmodus. Die Verwendung wird im Tutorial zum Lernen von Bildern erläutert
- Schaltfläche "Importieren" ... Importiert die visuelle Erkennungsdatenbank aus einer lokalen Datei in Choregraphe
- Schaltfläche Exportieren ... Exportiert die visuelle Erkennungsdatenbank von Choregraphe in eine lokale Datei
- Schaltfläche Löschen ... Löscht die aktuelle visuelle Erkennungsdatenbank
- Senden-Schaltfläche ... Sendet die visuelle Erkennungsdatenbank, die in der aktuellen Choregraphe enthalten ist, an Pepper
Bestätigung durch Monitor
Sie können auch die mit Choregraphe installierte Monitor-Anwendung verwenden. Die Monitor-Anwendung wird wie folgt gestartet.
-
Starten Sie die ** Monitor ** -Anwendung, die mit Choregraphe installiert ist.
-
Klicken Sie im Startmenü der Monitor-Anwendung auf ** Kamera **
-
Ein Dialogfeld, in dem Sie aufgefordert werden, eine Verbindung zum Pepper herzustellen, wird geöffnet. Wählen Sie daher den verwendeten Pepper aus.

-
Das Monitorfenster wird geöffnet. Klicken Sie auf die Schaltfläche ** Wiedergabe **.

-
Sie können das von Peppers Kamera aufgenommene Bild überprüfen
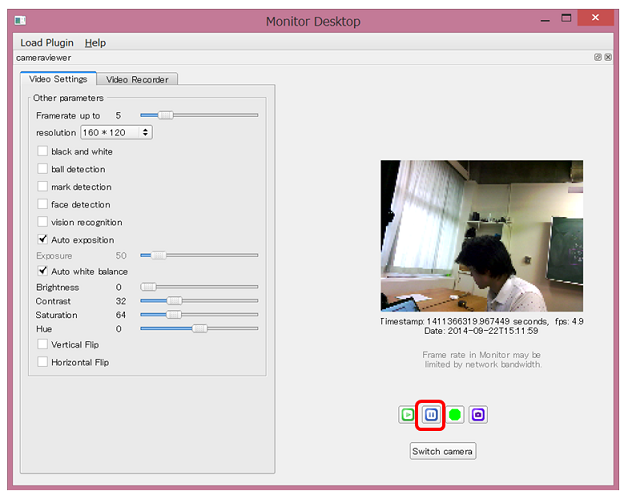 Sie können die Wiedergabe mit der Taste ** Pause ** stoppen
Sie können die Wiedergabe mit der Taste ** Pause ** stoppen -
Zusätzlich zu Bildern können Sie Informationen zur Bilderkennung überprüfen. Durch Aktivieren von ** Gesichtserkennung [A] ** können Sie den Status von Peppers ** Gesichtserkennung [B] ** überprüfen.

-
Wenn Sie den Inhalt der 3D-Kamera überprüfen möchten, ** Wählen Sie [3D-Sensormonitor] aus dem Menü [Plugin laden] **

-
Sie können die Tiefenkarte überprüfen, indem Sie wie bei einer 2D-Kamera auf die Schaltfläche ** Wiedergabe ** klicken.
 Sie können die Wiedergabe mit der Taste ** Pause ** stoppen
Sie können die Wiedergabe mit der Taste ** Pause ** stoppen
Mit dieser Monitor-Anwendung können Sie den Inhalt des von Pepper erkannten Bilds detailliert überprüfen.
Grundlegende Gesichtserkennung
Gesichtserkennung
Wenn Sie das standardmäßig bereitgestellte Feld Gesichtserkennung verwenden, können Sie die Anzahl der Gesichter ermitteln, die derzeit von Pepper erkannt werden. Hier werde ich versuchen, die Say Text-Felder, die ich mehrmals verwendet habe, so zu kombinieren, dass ** Pepper die Anzahl der erkannten Gesichter spricht **.
Versuchen Sie zu machen
- Vorbereitung der zu verwendenden Box
- Standard-Box-Bibliothek
- Vision> Gesichtserkennung ... Führt eine Gesichtserkennung durch und gibt die Anzahl der erkannten Gesichter aus.
- Erweiterte Box-Bibliothek ... Wählen Sie die Registerkarte Erweitert der Box-Bibliothek
- Audio> Voice> Say Text ... Sprechen Sie die eingegebene Zeichenfolge
- Schließen Sie die Boxen an

Durch Verbinden von numberOfFaces (orange, Typ: Nummer) im Feld Gesichtserkennung mit onStart (blau, Typ: Zeichenfolge) im Feld Sagen von Text können Sie Pepper dazu bringen, den Wert von numberOfFaces zu sprechen, der vom Feld Gesichtserkennung ausgegeben wird. Ich werde.

Der Antrag ist jetzt vollständig. Wenn ein Gesicht erkannt wird, gibt das Feld Gesichtserkennung numberOfFaces aus, und Pepper spricht als Antwort auf diese Ausgabe.
Funktionsprüfung
Stellen Sie eine Verbindung zu Pepper her und versuchen Sie zu spielen. Wenn Sie Pepper Ihr Gesicht zeigen, spricht Pepper über die Anzahl der sichtbaren Gesichter wie "Ichi" und "Ni".
In der Roboteransicht können Sie auch die Position des von Pepper erkannten Gesichts ermitteln.

Wenn Pepper beispielsweise wie oben gezeigt ein Gesicht erkennt, wird in der Roboteransicht eine Gesichtsmarkierung angezeigt. Dies zeigt die Position des Gesichts, die Pepper kennt.
(Ergänzung) Anpassung des Say-Textfelds
Dieses Beispiel ist so einfach wie das Aussprechen von Zahlen wie "ichi" und "ni". Es reicht aus, die Bewegung der Gesichtserkennungsbox zu sehen, aber es ist eine Anwendung, die schwer zu sagen ist, was Sie tun.
Wenn hier beispielsweise die Anzahl der erkannten Gesichter 1 beträgt, ändern wir sie so, dass "Es ist eine Person vor mir" ** angezeigt wird.
Das Feld "Text sagen" ist ein Python-Feld, das die sprechende API ** ALTextToSpeech API ** verwendet. Wenn Sie die Zeichenfolge bearbeiten können, die aus dem Feld "Text sagen" an ALTextToSpeech übergeben wurde, können Sie Ihre Aussagen ändern.
Dieses Mal werde ich versuchen, die Zeichenfolge im Feld "Text sagen" zu bedienen. Durch Doppelklicken auf das Feld "Text sagen" wird der Python-Code geöffnet. Suchen Sie daher in diesem Code nach der Funktion "onInput_onStart (self, p)". Sie können sehen, dass es eine Linie wie diese gibt:
sentence = "\RSPD="+ str( self.getParameter("Speed (%)") ) + "\ "
sentence += "\VCT="+ str( self.getParameter("Voice shaping (%)") ) + "\ "
sentence += str(p)
sentence += "\RST\ "
id = self.tts.post.say(str(sentence))
self.ids.append(id)
self.tts.wait(id, 0)
p enthält den in das Feld Say Text eingegebenen Wert und erstellt die Zeichenfolge, die der ALTextToSpeech-API unter satz + = str (p) gegeben werden soll.
Wenn Sie diesen Teil in "Satz + =" da ist eine Person vor mir "+ str (p) +" da ist eine Person "" usw. ändern, ist anstelle von "eins" "eine Person vor mir". "(" Eine Person "spricht" eine Person ").
Gesichtserkennung
Ähnlich wie bei der Stimme ermöglicht es Pepper, die Richtung des Gesichts zu verfolgen. Im Audiobeispiel haben wir nur den Winkel des Halses verschoben, aber hier verwenden wir das Feld Face Tracker, um ** in Richtung des Gesichts ** zu bewegen.
Versuchen Sie zu machen
- Vorbereitung der zu verwendenden Boxen (Standard-Box-Bibliothek)
- Tracker> Face Tracker ... Verfolgen Sie Ihr Gesicht
- Schließen Sie die Boxen an

Sie können Ihr Gesicht verfolgen, indem Sie das Feld Face Tracker starten.
- Stellen Sie die Parameter ein
Setzen Sie die Mode-Variable des Face Tracker-Parameters auf ** Move **.

Der Antrag ist jetzt vollständig. Die Face Tracker-Box verfügt über eine große Funktion, die "das Gesicht identifiziert und sich in diese Richtung bewegt", sodass der Ablauf so einfach sein kann.
Funktionsprüfung
Stellen Sie eine Verbindung zu Pepper her und versuchen Sie zu spielen. Wenn sich ein Mensch in der Nähe befindet, versucht er, das erkannte Gesicht zu verfolgen, indem er seinen Hals beugt. Während er sich jedoch allmählich mit dem Gesicht nach vorne wegbewegt, bewegt sich Pepper zum Gesicht. Wenn Sie per Kabel mit Pepper verbunden sind, achten Sie darauf, dass Sie es nicht in eine unerwartete Richtung bewegen.
Bevor ich mich daran gewöhne, habe ich ein wenig Angst, verfolgt zu werden, während ich Pepper anstarrte, aber irgendwann denke ich vielleicht, dass meine oberen Augen süß sind ...!
Gesichtslernen und Diskriminierung
Im vorherigen Beispiel habe ich einfach "Gesichter" gezählt und verfolgt. Schauen wir uns hier an, wie man lernt, sich daran zu erinnern, wer das Gesicht ist.
Das Gesicht lernen
Sie können Pepper mit einem Gesicht lernen lassen, indem Sie das Feld Gesicht lernen verwenden. Hier werden wir versuchen **, uns das Gesicht zu merken, das Pepper 5 Sekunden nach der Wiedergabe mit dem Namen "Taro" ** gesehen hat.
Versuchen Sie zu machen
- Vorbereitung der zu verwendenden Boxen (Standard-Box-Bibliothek)
- Daten bearbeiten> Text bearbeiten ... Gibt eine beliebige Zeichenfolge aus
- Vision> Gesicht lernen ... Merken Sie sich die Entsprechung zwischen Gesichtern und Namen
-
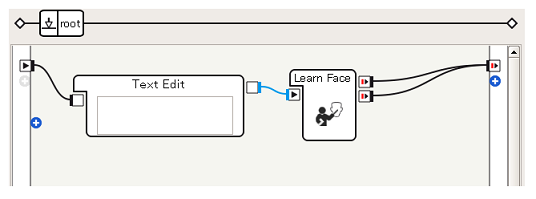
Schließen Sie die Boxen an
-
Legen Sie die Zeichenfolge fest

Mit Learn Face können Sie jetzt eine Anwendung implementieren, in der Peppers Gesicht als "Taro" gelernt wird.
Funktionsprüfung
Stellen Sie nach dem Herstellen einer Verbindung zu Pepper und dem Spielen sicher, dass sich Ihr Gesicht in Reichweite der Kamera von Pepper befindet. Fünf Sekunden nach der Wiedergabe werden Peppers Augen grün **, wenn das Gesicht normal gelernt werden kann, und ** rot **, wenn es fehlschlägt.
Sie können die gelernten Gesichtsdaten löschen, indem Sie ** Alle Gesichter verlernen ** ausführen.
####
[Referenz] Learn Face Inhalt Sie können sehen, wie "5 Sekunden warten" und "Augen grün werden" im Feld "Gesicht lernen" durch Doppelklicken auf das Feld "Gesicht lernen" realisiert werden.
Sie können sehen, dass das Feld "Gesicht lernen" ein Flussdiagrammfeld ist und als Sammlung einfacherer Felder wie "Warten" dargestellt wird. Wenn Sie auf diese Weise in die Box schauen, können Sie sie als Referenz verwenden, wenn Sie über die Verwendung der Box nachdenken.
Gesichtsdiskriminierung
Nachdem Sie das Gesicht anhand der Trainingsdaten gelernt haben, ** bestimmen Sie, wer das Gesicht ist, das Pepper gerade erkennt, und lassen Sie ihn den Namen sprechen **.
Versuchen Sie zu machen
- Vorbereitung der zu verwendenden Box
- Standard-Box-Bibliothek
- Vision> Face Reco. ... Gesichter identifizieren
- Erweiterte Box-Bibliothek
- Audio> Voice> Say Text ... Sprechen Sie die aus dem vorherigen Feld eingegebene Zeichenkette
- Schließen Sie die Boxen an
 Es ist sehr einfach, es gibt nur die Ausgabe (blau, Zeichenfolge) der Face Reco. Box an das Say Text-Feld.
Es ist sehr einfach, es gibt nur die Ausgabe (blau, Zeichenfolge) der Face Reco. Box an das Say Text-Feld.
Funktionsprüfung
Verbinde dich mit Pepper und spiele. Wenn Sie Pepper Ihr Gesicht zeigen und den Namen sagen, den Sie gelernt haben, wie z. B. "Taro", sind Sie erfolgreich. Lernen Sie Gesicht mehrere Gesichter, um zu sehen, ob Pfeffer richtig identifiziert werden kann.
Bildlernen und Diskriminierung
Choregraphe hat eine Funktion zum Bedienen der visuellen Erkennungsdatenbank, mit der Pepper etwas anderes als das menschliche Gesicht lernen kann.
Bilder lernen
Verwenden Sie das Videomonitorfeld von Choregraphe, um Bilder zu lernen. Hier lernen wir ** NAO ** im Atelier.
-
Stellen Sie mit dem Objekt auf dem Videomonitor eine Verbindung zu Pepper her und klicken Sie auf die Schaltfläche ** Lernen **
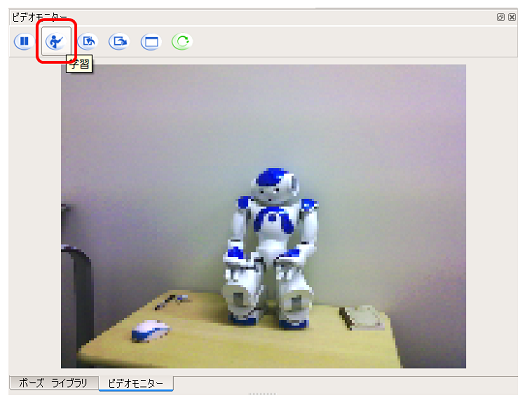
-
Klicken Sie mit der linken Maustaste auf ** Objektgrenze **

-
Erstellen Sie, indem Sie mit der linken Maustaste auf den Scheitelpunkt klicken, als ob Sie eine gerade Linie zeichnen würden

-
Stellen Sie die Scheitelpunkte so ein, dass sie das Objekt umgeben, und klicken Sie schließlich mit der linken Maustaste auf den Startpunkt.

-
Der Bereich des Objekts wird identifiziert und ein Dialogfeld zur Eingabe von Informationen wird geöffnet. Geben Sie die entsprechenden Informationen ein.

Geben Sie hier NAO ein.

- Klicken Sie auf die Schaltfläche ** Aktuelle visuelle Erkennungsdatenbank an Roboter senden **, um die in der visuellen Erkennungsdatenbank von Choregraphe registrierten Informationen an Pepper zu senden.

Sie haben Pepper jetzt mit der Zeichenfolge "NAO" den Bildfunktionen von NAO zugeordnet.
Bildunterscheidung
Wie bei der Gesichtsdiskriminierung werden wir versuchen, Sie anhand des Inhalts der geschulten Datenbank zur visuellen Erkennung über das, was Sie sehen, sprechen zu lassen.
Versuchen Sie zu machen
Mit der Vision Reco. Box können Sie das, was Pepper gerade betrachtet, mit der visuellen Erkennungsdatenbank abgleichen, um den Namen des Objekts zu erhalten.
- Vorbereitung der zu verwendenden Box
- Standard-Box-Bibliothek
- Vision> Vision Reco. ... Entspricht der visuellen Erkennungsdatenbank
- Erweiterte Box-Bibliothek
- Audio> Voice> Say Text ... Sprechen Sie die aus dem vorherigen Feld eingegebene Zeichenkette
-
Verbinden Sie die Boxen (1)
 Geben Sie dem Feld "Text sagen" zunächst die Ausgabe "onPictureLabel" (blau, Zeichenfolge) des Felds "Vision Reco."
Geben Sie dem Feld "Text sagen" zunächst die Ausgabe "onPictureLabel" (blau, Zeichenfolge) des Felds "Vision Reco." -
Verbinde die Kästen (2) In diesem Beispiel sind die Ausgänge ** onPictureLabel ** und ** onStop ** der Vision Reco. Box verbunden, um den Betrieb der Vision Reco. Box während des Gesprächs nach der Erkennung zu stoppen (der Grund wird später beschrieben).
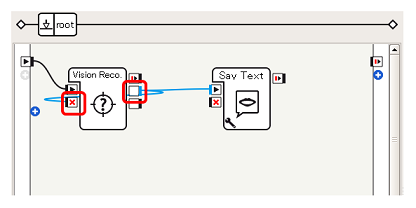 Verbinden Sie nach dem Sprechen den ** onStopped-Ausgang ** des Say Text-Felds mit dem ** onStart-Eingang ** des Vision Reco. Box, um den Betrieb des Vision Reco. Box fortzusetzen.
Verbinden Sie nach dem Sprechen den ** onStopped-Ausgang ** des Say Text-Felds mit dem ** onStart-Eingang ** des Vision Reco. Box, um den Betrieb des Vision Reco. Box fortzusetzen.

####
Wenn daher nur die Verbindung in 2. verwendet wird, werden Sie nicht nur weiterhin "NAO", "NAO" und "NAO" sprechen, während Sie NAO anzeigen, sondern dies wird auch für eine Weile fortgesetzt, selbst wenn Sie NAO aus Peppers Ansicht entfernen. Es wird sein. Um solche Probleme zu vermeiden, wird die Vision Reco. Box vorübergehend gestoppt, nachdem die Vision Reco. Box das Erkennungsergebnis ausgegeben hat, und nach Abschluss der Say Text Box wird die Vision Reco. Operation neu gestartet. ..
Funktionsprüfung
Versuchen Sie, eine Verbindung zu Pepper herzustellen und die von Ihnen erstellte Anwendung abzuspielen. Von "NAO" zu sprechen, wenn NAO gezeigt wird, ist ein Erfolg.
Wie Sie sehen können, verfügt Pepper über verschiedene Funktionen zur Bilderkennung. Durch Steuern von Pepper mit den von den Augen erhaltenen Informationen kann der Kontrollbereich erweitert werden. Bitte probieren Sie es aus.
Recommended Posts