[PYTHON] Lassen Sie uns ein Überlebensvorhersagemodell für Titanic-Passagiere einrichten
Einführung
Dieser Artikel ist ein Artikel am ** 24. Tag ** von Gizumo Engineer Adventskalender 2015.
Ich bin @suzumi, ein Web-App-Ingenieur bei Gizumo Co., Ltd., einem jungen Unternehmen, das es seit einem halben Jahr gibt. Dies ist der zweite Artikel im Adventskalender. Der erste Artikel lautet "IoT-I hat versucht, die Klimaanlage über node.js aus dem Internet fernzusteuern". Bitte sehen Sie zusammen, wenn Sie möchten.
Thema
Lassen Sie uns zunächst Kaggle kennenlernen.
Was ist Kaggle?
Kaggle ist eine Plattform für prädiktive Modellierungs- und Analysemethoden und deren Betriebsgesellschaft, auf der Unternehmen und Forscher Daten veröffentlichen und Statistiker und Datenanalysten auf der ganzen Welt um das optimale Modell konkurrieren.
- Aus WikiPedia
Wie Sie im Zitat sehen können, handelt es sich um eine Website, auf der Unternehmen und andere Daten veröffentlichen, analysieren und modellieren und um eine optimale Modellierung konkurrieren. Für Unternehmen, die Daten veröffentlichen und Wettbewerbe veranstalten, kann es zur Rekrutierung exzellenter Datenwissenschaftler verwendet werden. Menschen, die am Wettbewerb teilnehmen, sind zu einer Plattform geworden, die auf beiden Seiten Vorteile hat, z. B. den Versuch, ihre Fähigkeiten zu verbessern und zu studieren. Darüber hinaus haben einige Wettbewerbe Preise, und einige Wettbewerbe haben einen Preis von 3 Millionen Dollar (350 Millionen Yen). User Ranking ist auch für die Öffentlichkeit zugänglich. Wenn es hier aufgeführt ist, wird es als exzellenter Datenwissenschaftler weltweit Aufmerksamkeit erregen. So wie die Anzahl der Sterne auf GitHub Status ist, denke ich, dass Rankings Status für Datenwissenschaftler sind.
Recruit beschließt, "RECRUIT Challenge --Coupon Purchase Prediction", den ersten von "Kaggle" und einem japanischen Unternehmen gemeinsam gesponserten Wettbewerb zur Datenvorhersage, abzuhalten Es wurde im Sommer ein heißes Thema in den Nachrichten, und ich denke, dass Kaggles Popularität auch in Japan dramatisch zugenommen hat. Ich habe auch von Kaggle aus diesen Nachrichten erfahren (Tehe)
Vor kurzem habe ich überall Wörter wie "Datenwissenschaft", "maschinelles Lernen" und "künstliche Intelligenz" gehört. Natürlich kann ich nicht schweigen, weil ich modische Dinge mag.
Dieses Mal möchte ich einen der Tutorial-ähnlichen Wettbewerbe in Kaggle herausfordern, "Überlebensvorhersage der Titanic".
Die Ausführungsumgebung ist übrigens wie folgt. Es war mühsam, verschiedene numerische Berechnungsbibliotheken einzutragen, deshalb habe ich Anaconda eingegeben.
- Python3.5
- iPython notebook
Vorbereitung der Daten
Zuerst bereiten wir die Daten vor. Wechseln Sie zunächst zur Wettbewerbsseite. Laden Sie die Daten von "Daten" im linken Dashboard herunter. Ich bin mir vorerst nicht sicher, daher werde ich die folgende CSV herunterladen, die so aussieht.
- train.csv (59.76 kb)
- test.csv (27.96 kb)
In Bezug auf den Inhalt hat "train.csv" eine Passagierliste für ungefähr 900 Personen (mit Überlebensergebnissen) und "test.csv" hat eine Passagierliste für ungefähr 400 Personen (Überlebensergebnisse unbekannt).
Wie Sie dem Namen entnehmen können, ist es ein Fluss, ein Vorhersagemodell aus train.csv zu erstellen und die Passagierliste von test.csv tatsächlich zu testen und eine Vorhersage zu erstellen. .. Ich erinnere mich, dass ich irgendwo gehört habe, dass aus etwa 70% der Daten ein Vorhersagemodell erstellt und mit den verbleibenden 30% der Daten getestet wurde. Genau das ist es also. Ich bin dankbar, dass die Daten von Anfang an getrennt sind.
Zufälliger Wald
Sollte ich einen zufälligen Wald verwenden, da der Wettbewerbstitel besagt, dass die Verwendung eines zufälligen Waldes vorhergesagt werden soll? Was ist überhaupt ein zufälliger Wald? Also habe ich es im Wiki nachgeschlagen.
Vorgeschlagen von Leo Breiman im Jahr 2001 [1] Ein Algorithmus für maschinelles Lernen, der zur Klassifizierung, Regression und Clusterbildung verwendet wird. Es handelt sich um einen Gruppenlernalgorithmus, der einen Entscheidungsbaum als schwachen Lernenden verwendet. Sein Name basiert auf der Verwendung einer großen Anzahl von Entscheidungsbäumen, die aus zufällig ausgewählten Trainingsdaten gelernt wurden. Je nach Fach ist es auch effektiver als das Boosten durch Gruppenlernen.
- [WikiPedia](https://ja.wikipedia.org/wiki/%E3%83%A9%E3%83%B3%E3%83%80%E3%83%A0%E3%83%95%E3 Von% 82% A9% E3% 83% AC% E3% 82% B9% E3% 83% 88)
Was ist überhaupt ein Entscheidungsbaum?
Der Entscheidungsbaum ist einer der Lernalgorithmen. Zum Abschluss wird eine Frage gestellt, mit Ja und Nein verzweigt und eine Baumstruktur erstellt. Der Algorithmus sagt: "Verzweigen, bis Sie eine vollständige Antwort erhalten, und wenn Sie nicht mehr verzweigen können, hören Sie dort auf."

Mit anderen Worten, es scheint sich um ein Gruppenlernmodell zu handeln, das die Genauigkeit verbessert, indem Gruppenlernen (Ensemble-Lernen) mit einer großen Anzahl von Entscheidungsbäumen durchgeführt wird. Und wie man einen Entscheidungsbaum erstellt, scheint das Herzstück des Lernmodells zu sein.
Schauen Sie sich die Daten an
Öffnen Sie train.csv und werfen Sie einen Blick darauf.

Zuerst habe ich die Bedeutung von Variablen untersucht.
--PassengerID: Passagier-ID
- Überlebt: Überlebensergebnis (1: Überleben, 2: Tod) --Klasse: Passagierklasse 1 scheint die höchste zu sein --Name: Name des Passagiers
- Sex: Geschlecht
- Alter: Alter --SibSp Anzahl der Brüder und Ehepartner. --Parch: Anzahl der Eltern und Kinder. --Ticket Ticketnummer. --Preis Boarding Gebühr.
- Kabinen-Zimmernummer
- Eingeschifft Es gibt drei Arten von Häfen an Bord: Cherbourg, Queenstown und Southampton.
Laden wir vorerst csv. Wir verwenden Pandas, die sich gut für die Datenverarbeitung und -aggregation eignen. Das Geschlecht ist als Mann, Frau, schwer zu handhaben männlich: männlich wird als 0 behandelt, weiblich: weiblich wird als 1 behandelt.
import pandas as pd
import matplotlib.pyplot as plt
df= pd.read_csv("train.csv").replace("male",0).replace("female",1)
Umgang mit fehlenden Werten
In Age fehlen einige Datensätze. Es scheint notwendig zu sein, einen Wert in den fehlenden Teil einzugeben, aber wenn Sie ihn vorerst mit 0 füllen, wirkt sich dies später auf das Vorhersagemodell aus. In diesem Fall ist die Reichweite nicht so groß, sodass das Durchschnittsalter aller Passagiere in Ordnung ist. In diesem Fall ist es jedoch sicher, den Median zu verwenden. Daher werde ich den Median dort anwenden, wo er fehlt. ..
df["Age"].fillna(df.Age.median(), inplace=True)
Lassen Sie uns für jede Raumnote ein Histogramm ausgeben.
split_data = []
for survived in [0,1]:
split_data.append(df[df.Survived==survived])
temp = [i["Pclass"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=3)
Von links in den Räumen der ersten, zweiten und dritten Klasse ist das Grün die überlebende Person und das Blau die Toten. Es scheint, dass mehr als die Hälfte der Passagiere in den erstklassigen Zimmern überlebt. Auf der anderen Seite scheint nur 1/5 der Passagiere in den Gästezimmern der dritten Klasse überlebt zu haben. Vielleicht wurde den Passagieren in den erstklassigen Gästezimmern Vorrang eingeräumt und sie bestiegen das lebensrettende Boot.

Als nächstes erstellen wir ein Histogramm für jedes Alter.
temp = [i["Age"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=16)
 Nur das Zentrum ragt heraus. ..
Dies lag daran, dass ich stattdessen den Medianwert in den fehlenden Wert setzte.
Wenn Sie das Alter vermissen, lassen Sie es weg und versuchen Sie erneut, das Histogramm auszugeben.
Nur das Zentrum ragt heraus. ..
Dies lag daran, dass ich stattdessen den Medianwert in den fehlenden Wert setzte.
Wenn Sie das Alter vermissen, lassen Sie es weg und versuchen Sie erneut, das Histogramm auszugeben.
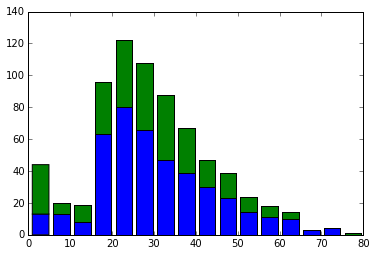
Es hat eine schöne Form. Wenn ich es mir ansehe, sind ältere Menschen unerwartet tot. Im Gegenteil, Säuglinge haben eine ziemlich hohe Überlebensrate. Von hier aus scheint es, dass Menschen mit Babys beim Einsteigen in das Rettungsboot Vorrang eingeräumt wurde.
Datenformung
Als ich mir die Daten ansah, dachte ich, dass große Familien mit 5 oder mehr Menschen eine niedrige Überlebensrate hatten. Wenn man sich die Ticketnummer ansieht, scheint es, dass einige Leute nicht eindeutig sind und die Nummer erhalten. Ich weiß nicht, ob sie im selben Raum waren oder ob sie zusammen gekauft wurden, sie hätten dieselbe Nummer. Sind beispielsweise alle Personen mit der Ticketnummer "347082" Familiennamen? Ist das gleiche wie "Andersson". Wenn man das Alter betrachtet, sieht es aus wie eine siebenköpfige Familie. Da die Note 3 ist, frage ich mich, ob es ein Raum im Untergeschoss war, alle sind tot. Fügen Sie eine Variable für "Anzahl der Familienmitglieder" hinzu. Löschen Sie dann unnötige Variablen.
df["FamilySize"] = df["SibSp"] + df["Parch"] + 1
df2 = df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)

Es scheint, dass der Pandas-Datenrahmen aufgrund des unterschiedlichen Typs nicht an scicit-learn übergeben werden kann. Überprüfen wir also den Typ.
df2.dtypes
#Ausgabeergebnis
PassengerId int64
Survived int64
Pclass int64
Sex int64
Age float64
FamilySize int64
dtype: object
Es sieht so aus, als könnten Sie es ohne Probleme bestehen.
Lass uns tatsächlich lernen
scikit-learn ist eine maschinelle Lernbibliothek für Python. Verwenden Sie RandomForestClassifier, um einen Entscheidungsbaum zu erstellen und vorherzusagen.
Da die für Trainingsdaten erforderlichen Variablen Pclass und höher sind, werden sie getrennt. PassengerId ist nicht erforderlich, da es sich um eine von kaggle zugewiesene ID handelt. Überlebt, was das Überlebensergebnis ist, sind die richtigen Antwortdaten.
train_data = df2.values
xs = train_data[:, 2:] #Variablen nach Pclass
y = train_data[:, 1] #Richtige Antwortdaten
Lassen Sie uns tatsächlich trainieren und ein Vorhersagemodell erstellen. Die Anzahl der ermittelten Bäume wird basierend auf der Referenzseite auf 100 festgelegt. Und der Inhalt von test.csv formatiert die Daten genauso wie train.csv.
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators = 100)
#Lernen
forest = forest.fit(xs, y)
test_df= pd.read_csv("test.csv").replace("male",0).replace("female",1)
#Fehlende Wertvervollständigung
test_df["Age"].fillna(df.Age.median(), inplace=True)
test_df["FamilySize"] = test_df["SibSp"] + test_df["Parch"] + 1
test_df2 = test_df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)
Bitten Sie sie, tatsächlich eine Vorhersage auf der Grundlage des Vorhersagemodells zu treffen.
test_data = test_df2.values
xs_test = test_data[:, 1:]
output = forest.predict(xs_test)
print(len(test_data[:,0]), len(output))
zip_data = zip(test_data[:,0].astype(int), output.astype(int))
predict_data = list(zip_data)
Wenn Sie sich den Inhalt von Predict_Data ansehen, werden die vorhergesagten Ergebnisse aufgelistet.

Und zum Schluss schreiben wir die Liste an csv. Sie sollten Predict_Result_Data.csv in Ihrem aktuellen Verzeichnis haben.
import csv
with open("predict_result_data.csv", "w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["PassengerId", "Survived"])
for pid, survived in zip(test_data[:,0].astype(int), output.astype(int)):
writer.writerow([pid, survived])
Bei Kaggle einreichen
Wir haben eine CSV erstellt, die das Überleben tatsächlich vorhersagt, indem wir ein Vorhersagemodell erstellen. Senden wir das an Kaggle. Gehen Sie zur Titanic-Wettbewerbsseite und laden Sie sie hoch und senden Sie sie von "Meine Einreichungen" → "Einreichen" in der linken Spalte. Dann wird die Punktzahl angezeigt und Sie werden eingestuft.

Die Punktzahl betrug 0,69856. Der Basiswert beträgt 0,76555, was nicht ausreicht. .. Lol
Dieses Mal bestand die Mission darin, ein Vorhersagemodell einzurichten und an Kaggle zu senden. ..
Zusammenfassung
Zuerst kaufte und las ich ein Buch über Algorithmen für maschinelles Lernen, aber ich hielt es für das Beste, es mit einer Bibliothek auszuprobieren. Es gibt eine nette Seite namens Kaggle, daher ist es möglicherweise eine gute Idee, Ihre Fähigkeiten hier zu testen oder anhand von Skripten anderer zu lernen. Warum beginnst du nicht dein maschinelles Lernen?
Referenzseite
kaggle 2nd Titanic Survivor Prediction erste Herausforderung: Ich habe versucht, die Überlebensrate mit einem zufälligen Wald aus dem Profil der Titanic-Passagiere vorherzusagen Titanic Survivor Prediction durch maschinelles Lernen mit Python
Recommended Posts