[GO] Verwenden von Cloud-Speicher aus Python3 (Einführung)
Einführung
Was ist BytesIO?
BytesIO ist eine Funktion zur Verarbeitung von Binärdaten im Speicher und in Pythons Standardbibliothek io enthalten. Binärdaten beziehen sich hauptsächlich auf Daten wie Bilder und Töne. (Es ist wie MemoryStream in C #)
Erstellen eines Dienstkontos
Gehen Sie zu Google Cloud Platform und erstellen Sie ein Dienstkonto (API).
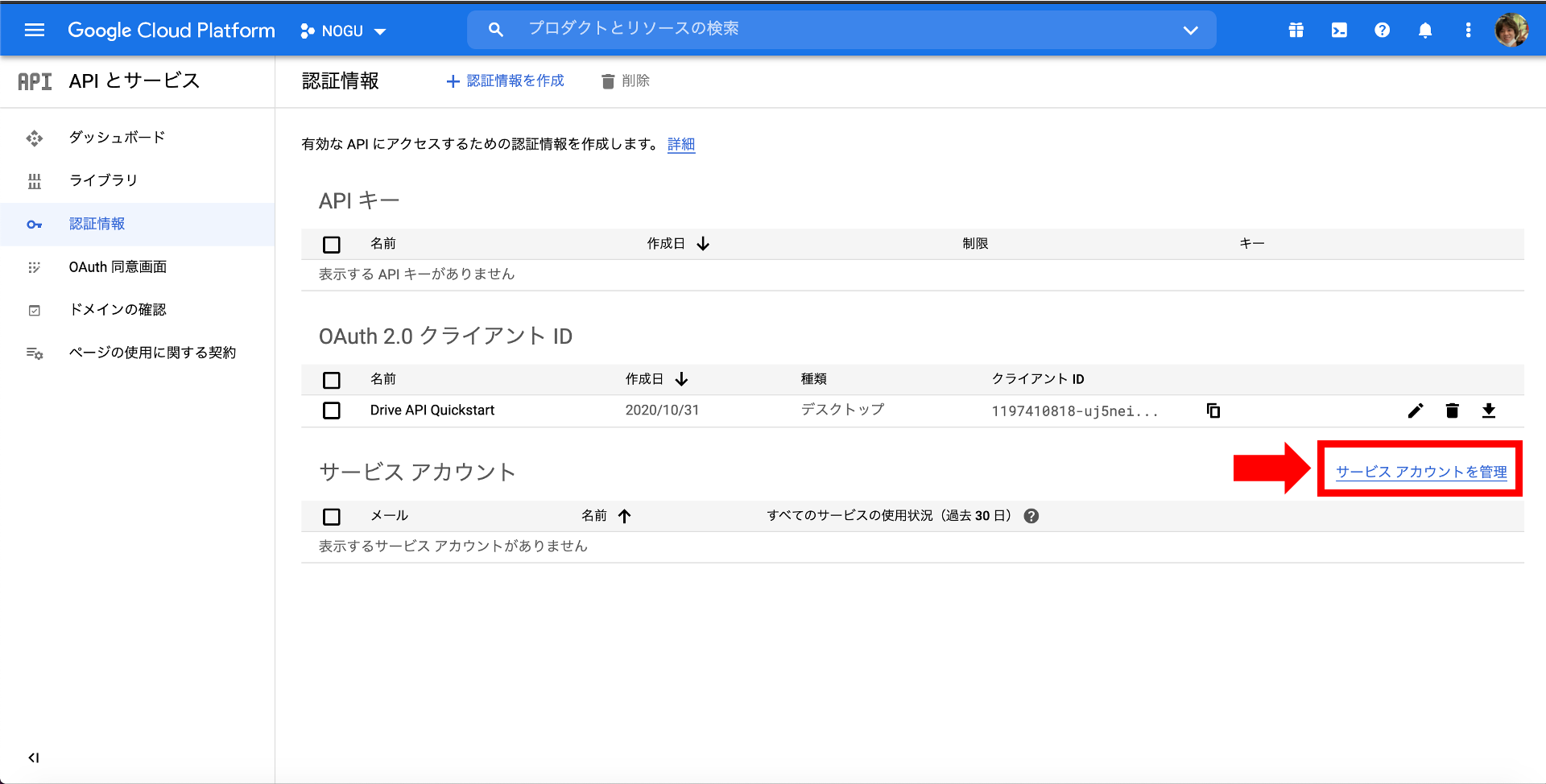
Klicken Sie auf Navigationsmenü> APIs und Dienste> Anmeldeinformationen, um zum Bildschirm zu gelangen.
Klicken Sie dann auf Dienstkonten verwalten.
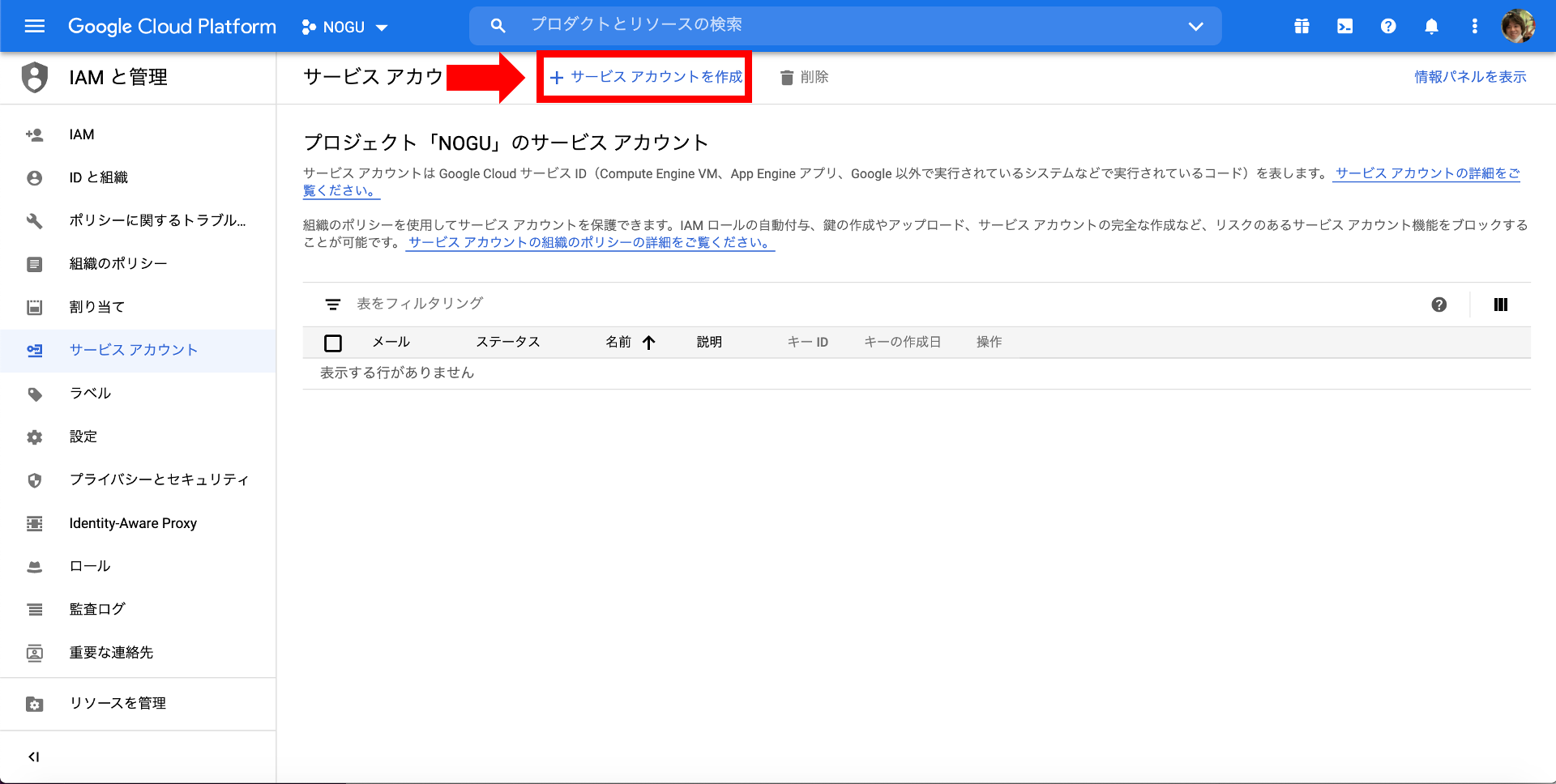
Klicken Sie im nächsten Bildschirm auf Dienstkonto erstellen.
 Geben Sie die Details des Dienstkontos für jeden Artikel ein.
Geben Sie die Details des Dienstkontos für jeden Artikel ein.
| Elemente einstellen | die Einstellungen |
|---|---|
| Name des Dienstkontos | (Auf einen beliebigen Namen setzen) |
| Beschreibung des Dienstkontos | (Optionale Einstellungen für jedes Projekt, um das Verständnis zu erleichtern) |
Klicken Sie auf Erstellen, wenn Sie fertig sind.
 Mit dem nächsten Element wird eine Rolle für den Cloud-Speicher erstellt. Da dies ein Test ist, habe ich "Speicheradministrator" (volle Berechtigung) gewählt.
Lassen Sie uns die Rolle entsprechend der verwendeten Anwendung ändern.
Mit dem nächsten Element wird eine Rolle für den Cloud-Speicher erstellt. Da dies ein Test ist, habe ich "Speicheradministrator" (volle Berechtigung) gewählt.
Lassen Sie uns die Rolle entsprechend der verwendeten Anwendung ändern.

Sie können den letzten Eintrag weglassen.
Klicken Sie auf das von Ihnen erstellte Dienstkonto, klicken Sie im Feld Schlüssel auf Schlüssel hinzufügen und wählen Sie Neuen Schlüssel erstellen.


Wählen Sie JSON als Schlüsseltyp und "erstellen" Sie es. Da die JSON-Datei in den lokalen Speicher heruntergeladen wird, verwenden Sie die JSON-Datei im nächsten Element und betreiben Sie Cloud Storage von Python aus.
Betreiben Sie den Cloud-Speicher von Python aus
Installieren der Python-Bibliothek
Wir werden die für dieses Projekt erforderlichen Bibliotheken der Reihe nach installieren. Um auf Cloud Storage zuzugreifen, installieren Sie zunächst die Google Cloud Storage-Bibliothek mit pip install.
pip install google-cloud-storage
Pillow wird auch installiert, um lokal mit Pillow via BytesIO in einer Datei zu speichern.
pip install requests pillow
Installieren Sie openpyxl für diejenigen, die Excel-Dateien usw. ausprobieren möchten.
pip install openpyxl
Vorbereiten von Buckets im Cloud-Speicher
Greifen Sie über die GUI auf Google Cloud Storage zu, erstellen Sie einen Bucket und bereiten Sie eine entsprechende Bilddatei vor.
Gehen Sie auf dem Konsolenbildschirm zu Navigationsmenü> Cloud-Speicher.
Dieses Mal habe ich die Python-Logo-Datei heruntergeladen und als image.png gespeichert.
Python-Logo-Datei

{kind=link}
Greifen Sie über Python auf Cloud Storage zu und erhalten Sie Bilder
Wir werden mit dem zu Beginn erstellten Zugriffsschlüssel auf den Cloud-Speicher zugreifen. Zunächst müssen Sie den Schlüssel des Zugriffsbenutzers laden. Ich werde beschreiben, wie auf die beiden Zugriffsarten Bezug genommen wird.
#Beim Zugriff über Umgebungsvariablen
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '{Geben Sie den Pfad ein, in dem sich die JSON-Datei befindet}'
client= storage.Client()
#Beim direkten Zugriff auf die JSON-Datei.
client = storage.Client.from_service_account_json('{Geben Sie den Pfad ein, in dem sich die JSON-Datei befindet}')
Dies ist der Python-Code, der die in Google Cloud Storage (GCS) gespeicherte Bilddatei abruft und die Datei lokal speichert.
Holen Sie sich als Erklärung für das Programm den Bucket, in dem Sie die Datei speichern möchten, und die Blob-Instanz des Dateinamens.
Da die Binärdaten des Bildes enthalten sind, werden sie von Pillow über BytesIO gelesen und jede Bilddatei wird geschrieben.
Sie können Dateien auch direkt von GCS herunterladen, indem Sie blob.download_to_filename verwenden, diesmal jedoch GCS Die Daten werden an die PIL-Bibliothek usw. übergeben, unter der Annahme, dass die von oben abgelegten Dateien bearbeitet werden. </ font> </ strong>
from google.cloud import storage
from PIL import Image
import io
#Erstellen Sie eine Client-Instanz von Google Cloud Storage
#client = storage.Client()
client = storage.Client.from_service_account_json('●●●●●●●●●●.json')
#Holen Sie sich eine Instanz eines Buckets
bucket = client.bucket('{Bucket-Name mit einem beliebigen Namen erstellt}')
#Holen Sie sich eine Blob-Instanz einer Datei
blob = bucket.blob('image.png')
img = Image.open(io.BytesIO(blob.download_as_string()))
img.save('sample.png')
Greifen Sie über Python auf Cloud Storage zu und rufen Sie die Excel-Datei ab
Holen Sie sich die Excel-Datei auf GCS, lesen Sie die Blob-Daten mit openpyxl über BytesIO und speichern Sie sie.
Sie können Dateien auch direkt von GCS herunterladen, indem Sie blob.download_to_filename verwenden, diesmal jedoch GCS Die Daten werden an die PIL-Bibliothek usw. übergeben, unter der Annahme, dass die von oben abgelegten Dateien bearbeitet werden. </ font> </ strong>
from google.cloud import storage
import openpyxl
import io
#Erstellen Sie eine Client-Instanz von Google Cloud Storage
client = storage.Client.from_service_account_json('●●●●●●●●●●.json')
#Holen Sie sich eine Instanz eines Buckets
bucket = client.bucket('{Bucket-Name mit einem beliebigen Namen erstellt}')
##Holen Sie sich eine Blob-Instanz einer Datei
blob = bucket.blob('test.xlsx')
buffer = io.BytesIO()
blob.download_to_file(buffer)
wb = openpyxl.load_workbook(buffer)
wb.save('./retest.xlsx')
Artikel, die ich als Referenz verwendet habe
- Größe ändern und Cloud Storage-Bilder-Qiita erneut hochladen ・ [Python] Umgang mit Bildern von Binärdaten | Verschiedene Notizen des Kazusa-Programmierers · [Fehler bei der Verwendung von Google Cloud Storage und BigQuery mit Python | Monotalk](https://www.monotalk.xyz/blog/python-%E3%81%A6-google-cloud-storage-%E3% 81% A8bigquery-% E3% 82% 92% E4% BD% BF% E3% 81% 86% E9% 81% 8E% E7% A8% 8B% E3% 81% A6% E3% 81% AE% E3% 82 % A8% E3% 83% A9% E3% 83% BC /) ・ Python - Ich möchte eine Excel-Datei im Cloud-Speicher mit GCP-Cloud-Funktionen (Python) | teratail bearbeiten
- So erstellen und speichern Sie eine neue Excel-Datei mit OpenPyXL in Python ・ Verwendung von BytesIO (und StringIO, cStringIO) [Für Anfänger] | TechAcademy Magazine
- Behandeln von Dateien ohne Speichern von Zwischendaten mithilfe von On-Memory-Streams im Python | hgrs-Blog ・ So greifen Sie mit Python auf Google Cloud Storage zu und laden Dateien hoch / herunterladen | Dodotechno ・ [Python] Umgang mit Bildern von Binärdaten | Verschiedene Notizen des Kazusa-Programmierers
Recommended Posts