[PYTHON] Erstellen einer interaktiven Anwendung mithilfe eines Themenmodells
Ich möchte meine Augen mit Blue Ocean heilen, anstatt meine Augen mit Blue Light zu verbrennen.
2015 nähert sich dem Ende, aber wie geht es euch allen? Ich möchte gegen Ende des Jahres zur Natur zurückkehren, daher werde ich dieses Mal vorstellen, wie eine Anwendung erstellt wird, die mithilfe eines Themenmodells interaktive Reisevorschläge macht.
Dieser Artikel ist ein Schwesterartikel des zuvor veröffentlichten Artikels Erstellen einer Anwendung mit dem Themenmodell. Zu diesem Zeitpunkt holte die Erstellung der Anwendung nicht auf, und obwohl es sich um eine "Erstellung der Anwendung" handelte, wurde die Erstellung der Anwendung nicht abgeschlossen, sodass der Inhalt sie ergänzt. Ich werde dieses Mal nicht auf das Themenmodell selbst eingehen. Wenn Sie interessiert sind, lesen Sie bitte den obigen Artikel.
Was ist ein Themenmodell?
Ich werde die ausführliche Erklärung [hier] überlassen (http://tech-sketch.jp/2015/09/topic-model.html), aber das Themenmodell besteht darin, Dokumente nach Themen zu klassifizieren, wie der Name schon sagt. Es ist eine Methode von. Insbesondere hat das "Thema" hier das folgende Bild.
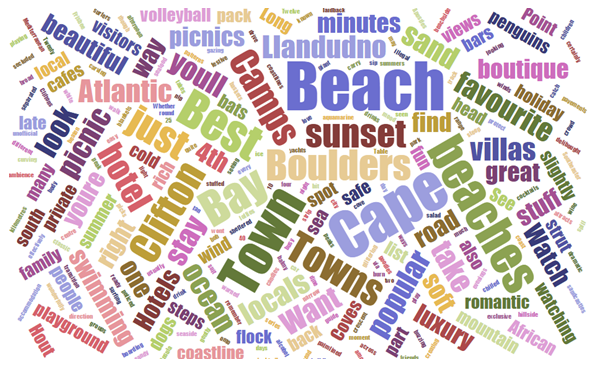
Dies ist eine Wortwolke, die aus einem Reiseblog erstellt wurde. Ein "Thema" besteht also aus Wörtern, und einige der Wörter sind häufig und andere nicht. Die Schätzung der Wahrscheinlichkeitsverteilung, die das "Erscheinungswort" und die "Erscheinungswahrscheinlichkeit" definiert, ist der Hauptfokus des Themenmodells. Sobald diese Wahrscheinlichkeitsverteilung bekannt ist, wird es möglich sein, Dokumente mit ähnlichen Verteilungen zu klassifizieren, und es wird auch möglich sein, den Grad der Relevanz zwischen Dokumenten aus dem Abstand zwischen Verteilungen abzuschätzen.
Anwendung auf interaktive Anwendungen
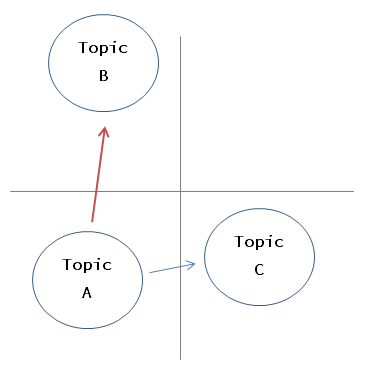
Themen können wie oben beschrieben durch Wahrscheinlichkeitsverteilungen dargestellt werden, so dass der Abstand zwischen Verteilungen berechnet werden kann (diesmal habe ich KL-Divergenz verwendet). Versuchen Sie anhand dieser Entfernung, einen Punkt für Thema A vorzuschlagen. Wenn die Antwort Nein lautet, schlagen Sie ein entferntes Thema vor (Thema B, das in der Abbildung am weitesten entfernt ist), und implementieren Sie es mit einer einfachen Richtlinie. Ich werde versuchen.
Implementierung einer interaktiven Anwendung
Die diesmal implementierte Anwendung ist hier.
Ich schlage ungefähr 3 Kandidaten aus dem gleichen Thema vor, die mit dem Pfeil unten gewechselt werden können. Wenn Ihnen etwas gefällt / das Bild anders ist, können Sie es mit der Schaltfläche Gut / Schlecht unten bewerten. Erhalten Sie Bewertungen und machen Sie Vorschläge für ähnliche / entfernte Themen.

Da es über eine Heroku-Schaltfläche verfügt, kann es in Ihrer Heroku-Umgebung bereitgestellt werden. Probieren Sie es mit dem Themenmodell aus, das ich erstellt habe! Das ist durchaus möglich. Als Daten wird die API von AB-ROAD verwendet, und diese Nutzungsregistrierung ist erforderlich.
Anwendungsimplementierung
Die Anwendungskonfiguration ist wie folgt.

application: Implementierung der Webanwendungdata: Speichert die trainierte Modelldatei. Da es schwierig war, die Datenbank zu verwenden, sind die Spot-Daten dieses Mal ebenfalls enthalten, aber ursprünglich werden sie mit Ignorieren abgelehnt.pola: Enthält das Themenmodell und die Implementierung des Dialogs, der es verwendet.polaist der Name des Motors, der diesen" Dialog unter Verwendung des Themenmodells "führt (ich habe einen fremdenähnlichen Namen gewählt, weil es sich um eine Auslandsreise handelt).scripts: Verschiedene Skripte zum Extrahieren, Formatieren und Trainieren von Datentests: Testcode
In der Komposition habe ich auf folgende Punkte geachtet.
- ** Separate Implementierung von Anwendungen und Implementierung von maschinellem Lernen ** (Trennung von "Anwendung" und "Pola") Bei der Entwicklung mit mehreren Teams ist es sehr wahrscheinlich, dass diese Verantwortlichkeiten getrennt werden, und ich denke, es ist besser, sie zu trennen, um die Portabilität des maschinellen Lernteils zu verbessern.
- ** Separate Datenextraktion / Formatierung und Implementierung des maschinellen Lernmodells ** (Trennung von
polaundscripts) Die Implementierung des Teils für maschinelles Lernen ist hauptsächlich in den Code "Datenextraktion und -formung" und den Teil "Modell für maschinelles Lernen" unterteilt. Ersteres hängt oft wirklich von den zu verarbeitenden Daten ab. Wenn dies in die "Implementierung eines maschinellen Lernmodells" einbezogen wird, wird das Modell selbst zu einer Datenquelle und vielen Menschen, sodass dies getrennt wird. Ich halte es für wünschenswert, den Teil des maschinellen Lernmodells in gewissem Umfang zu abstrahieren, z. B. "anwendbar, wenn Daten in diesem Format eingegeben werden". - ** Trennung von trainierten Modelldateien und Implementierung von maschinellem Lernen ** (
polaunddata) Da die Änderung des maschinellen Lernmodells selbst (Änderung des Algorithmus usw.) und die Aktualisierung des trainierten Modells, das das Lernergebnis darstellt, unterschiedlich sein sollten, trennen wir diesmal beide explizit. Natürlich denke ich, dass es auch die Idee gibt, mit einem trainierten Modell umzugehen.
Schreiben Sie danach wie in der Anwendung den Testcode genau für das Modell des maschinellen Lernens und hängen Sie das Dokument mit dem iPython-Notizbuch für das Modell des maschinellen Lernens an.
Die Konstruktionsannahmen und die Überprüfung des diesmal erstellten Themenmodells können dem folgenden iPython-Notizbuch entnommen werden.
enigma_abroad/pola/machine/topic_model_evaluation.ipynb
Erstellen eines Themenmodells
Wenn Sie einen Vorschlag machen, ist es natürlich wichtig, ein Themenmodell zu erstellen, das das Gehirn der Anwendung darstellt.
Diesmal wie im Schwesterartikel Erstellen einer Anwendung mit dem Auswahlmodell, [gensim]( Ich habe es mit https://radimrehurek.com/gensim/) erstellt (ich habe auch versucht, "pymc" zu verwenden, aber es wurde versiegelt, weil der Speicher durch Lernen verloren ging). Und leider war die Genauigkeit nicht so gut wie sie war ... aber ich werde hier weitermachen.
Wenn es darum geht, maschinelles Lernen in einer Anwendung tatsächlich zu verwenden, ist es außerdem unwahrscheinlich, dass "Genauigkeit 99% oder!" Dies ist häufig der Fall.
Um dies zu überwinden, sind eine stetige Datenerfassung und eine stetige Datenvorverarbeitung erforderlich. Ah ... als ich darüber sprach, was passiert ist, habe ich versucht, mit maschinellem Lernen etwas Cooles zu machen, aber bevor ich es wusste, habe ich akribisch Worte gesetzt, um sie aus dem Korpus auszuschließen ... ・. Inhaltsbasierte Empfehlungen wie das Themenmodell haben den Vorteil, dass sie Empfehlungen abgeben können, auch wenn die Bewertungsdaten der Benutzer unwiderstehlich sind, im Vergleich zur Co-Filterung, die häufig für Empfehlungen verwendet wird. Es funktioniert nicht gut (es gibt eine Reihe von Dokumenten, aber ich habe den Eindruck, dass das Volumen eines einzelnen Dokuments in Ordnung sein muss).
Erwägung
Obwohl es zu einer Anwendung gemacht wurde, wurde das wesentliche Themenmodell nicht gut erstellt. Das letzte Mal habe ich mich mit verschiedenen Daten aus dem Friseursalon und diesmal aus dem Reiseplan befasst, aber alle haben traurige Ergebnisse erzielt, dass die Themen nicht gut klassifiziert werden konnten.
Ich denke, die Ursache dafür ist das Datenproblem.
- Anzahl der Wörter pro Dokument: Wenn es nicht lang genug ist, werden nur wenige Schlüsselwörter angezeigt, die sich nicht so stark von anderen Wörtern unterscheiden. Infolgedessen wird es schwierig zu bestimmen, um welches Thema es sich handelt, und es wirkt sich auch auf die Gesamtzahl der Wörter aus.
- Klarer Themenunterschied: Bei allen handelt es sich um Dokumente in den vorhandenen Kategorien wie "Friseursalon" und "Reiseplan", sodass die angezeigten Wörter keinen großen Unterschied aufweisen.
Kurz gesagt, ich halte es für wünschenswert, es in einer Situation anzuwenden, in der es verschiedene Variationen von Dokumenten gibt und jedes ziemlich lang ist. Wenn Sie detailliertere Klassifizierungen innerhalb derselben Kategorie vornehmen möchten, müssen Sie meiner Meinung nach einige Vorkenntnisse aufbauen.
- Erstellen Sie ein Themenmodell mit Vorkenntnissen: Erstellen Sie im Voraus eine Wortgruppe aus Wikipedia usw. („Meer“ und „Strand“ sind dieselbe Gruppe usw.) und erstellen Sie ein Themenmodell, das auf der Wortgruppe anstelle der Wörter selbst basiert. Machen. Auf diese Weise ist es möglich, Notationsschwankungen und Konsenswörter zusammenzustellen, und es wird einfacher, Themen zu finden, selbst wenn die Anzahl der Dokumente gering ist.
- Lernen der Bedeutung von Wörtern: Menschen können die Wörter "Meer" und "Strand" als über das Meer sprechend erkennen, selbst wenn die Frequenz einmal ist. Es kann gesagt werden, dass das Thema durch seine Bedeutung und verwandte Wörter betrachtet wird, nicht durch die Häufigkeit des Auftretens des Wortes. Da diese Merkmalsgrößen nur mit word2vec usw. vektorisiert werden können, wird die Vektorgröße jedes Dokuments basierend auf dem im Voraus trainierten Modell berechnet und die Klassifizierung basierend darauf durchgeführt.
Ich denke, es gibt noch viele andere Ideen. Bitte versuchen Sie, Ihr eigenes Modell zu erstellen und eine Anwendung zu erstellen, die Sie zu Blue Ocean führt.

Recommended Posts