[PYTHON] Vorhersage der Zukunft mit maschinellem Lernen - Vorhersage zukünftiger Aktienkurse mit dem Entscheidungsbaum von Scikit-Learn
Dieser Artikel ist eine Fortsetzung von vorheriger, aber [maschinelles Lernen mit Scikit-Learn](http://qiita.com/ynakayama/items/ Ich möchte mit 9c5867b6947aa41e9229) eine Geschichte schreiben, die tatsächlich die Zukunft vorhersagt.
Schauen Sie sich zunächst die folgende Abbildung an.

Auch dieses Mal werden wir Aktienkursdaten als zu testende Daten verwenden. Die obige Abbildung zeigt den Aktienkurs unseres Unternehmens (DTS), bei dem es sich um echte Daten handelt.
Lassen Sie den Computer, wie in der Abbildung gezeigt, mithilfe von maschinellem Lernen die Informationen "Was ist als Ergebnis der Änderung des vergangenen Aktienkurses passiert?" Lernen und versuchen Sie, den zukünftigen Aktienkurs basierend darauf vorherzusagen.
Entscheidungsbaum-Algorithmus
Dieses Mal werden wir den Entscheidungsbaum (Digibaum) unter den vielen Klassifizierungsmethoden verwenden. Den Grund für die Auswahl der Methode finden Sie in Zuvor geschriebener Artikel.
Die Erklärung des Entscheidungsbaums selbst finden Sie in Wikipedia. Ich werde.
Eine Beschreibung des in scikit-learn implementierten Entscheidungsbaums finden Sie auch in der offiziellen Dokumentation (http://scikit-learn.org/stable/modules/tree.html).
Wenn Sie das Dokument lesen, scheint es, dass etwas Schwieriges auf Englisch geschrieben ist, aber kurz gesagt, wie man Scikit-Learn verwendet, besteht darin, das numerische Array (train_X) und das Ergebnis-Array (train_y) der Lehrerdaten zu trainieren. Bei einem Array von Zahlen für die Testdaten (test_X) wird das Vorhersageergebnis (test_y) zurückgegeben.
Dieses Mal konzentrieren wir uns auf die Verwendung. Lassen Sie also die detaillierte Theorie weg und probieren Sie es aus.
Die Aktienkursdaten zum Zeitpunkt des Schreibens sind wie folgt.
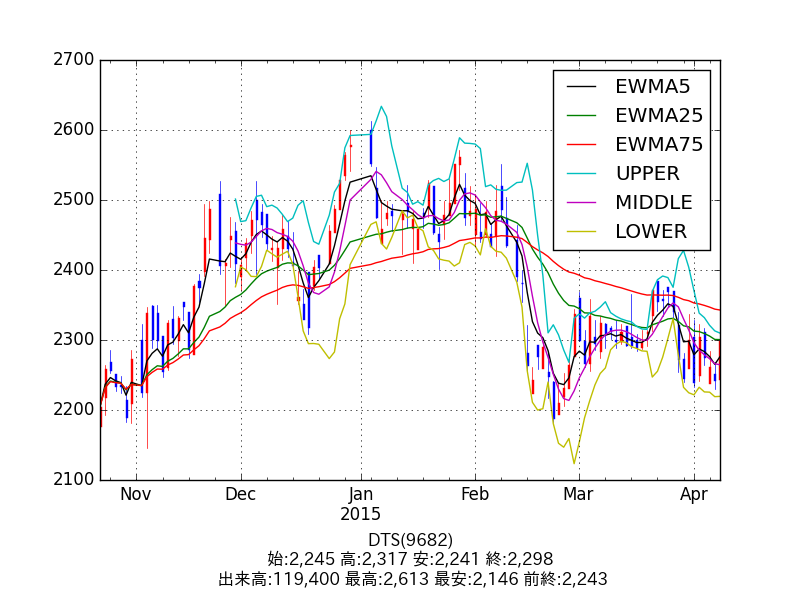
Dies sind die Daten der letzten 120 Werktage von 4/8 von DTS (9682) [matplotlib](http: Es ist unter //matplotlib.org/) eingezeichnet. Auf dem Tages-Chart ist Rot die positive Linie, Blau die negative Linie, EWMA der exponentielle gleitende Durchschnitt und die restlichen drei sind Bollinger-Bänder.
Erstellen Sie Lehrerdaten
Bereiten Sie zunächst den Code vom problematischsten aktienkursbereinigten Schlusskurs bis zur Erstellung von Lehrerdaten vor. Dies wäre gut, wenn Sie eine Liste der Schlusskurse übergeben würden und train_X und train_y zurückgegeben würden.
def train_data(arr):
train_X = []
train_y = []
#Lernen Sie 30 Tage Daten und wechseln Sie einen Tag nach dem anderen zurück
for i in np.arange(-30, -15):
s = i + 14 #14 Tage Wechsel
feature = arr.ix[i:s]
if feature[-1] < arr[s]: #Ist der Aktienkurs am nächsten Tag gestiegen?
train_y.append(1) #Wenn JA, 1
else:
train_y.append(0) #0 für NO
train_X.append(feature.values)
#Gibt das Ergebnis des Anhebens und Absenkens sowie eine Reihe von Lehrerdaten zurück
return np.array(train_X), np.array(train_y)
Dies gibt train_X (ein Array von Lehrerdaten) und train_y (eine 1 oder 0 Bezeichnung dafür) zurück.
Berechnen Sie den Rückgabeindex
Übrigens, wenn die Rohdaten des Aktienkurses unverändert verwendet werden, ist die Preisspanne für jedes Unternehmen völlig unterschiedlich, so dass es etwas schwierig ist, sie als Lehrerdaten zu verwenden. Normalisierung ist in Ordnung, aber hier ist die Änderung des Vermögenswerts Achten wir auf den Renditeindex, der darstellt. Ich habe auch vorherige für die Berechnungsmethode geschrieben, aber es kann von pandas wie folgt berechnet werden.
returns = pd.Series(close).pct_change() #Finden Sie die Rate der Zunahme / Abnahme
ret_index = (1 + returns).cumprod() #Finden Sie das kumulative Produkt
ret_index[0] = 1 #Erster Wert 1.Auf 0 setzen
Lassen Sie den Entscheidungsbaum die Änderung des Rückgabeindex erfahren
Nun, hier ist der Kimo. Lehrerdaten werden aus dem auf diese Weise erhaltenen und vom Klassifikator trainierten Rückgabeindex extrahiert.
#Extrahieren Sie die Lehrerdaten aus dem Rückgabeindex
train_X, train_y = train_data(ret_index)
#Generieren Sie eine Instanz des Entscheidungsbaums
clf = tree.DecisionTreeClassifier()
#Lernen
clf.fit(train_X, train_y)
Danach wird das Vorhersageergebnis zurückgegeben, indem die Testdaten an die Funktion clf.predict () übergeben werden.
Wenn 1 zurückgegeben wird, "steigt" der Aktienkurs Wenn 0 zurückgegeben wird, "fällt" der Aktienkurs Es wird vorhergesagt.
Probieren Sie den Klassifikator aus, um festzustellen, ob Sie gut gelernt haben
Lass es uns gleich versuchen. Lassen Sie uns zunächst als Test genau dieselben Daten wie die Lehrerdaten als Testdaten ausführen.
test_y = []
#Test mit Daten der letzten 30 Tage
for i in np.arange(-30, -15):
s = i + 14
#Lassen Sie uns den exakt gleichen Zeitraum des Rückgabeindex als Test klassifizieren
test_X = ret_index.ix[i:s].values
#Ergebnisse speichern und zurückgeben
result = clf.predict(test_X)
test_y.append(result[0])
print(train_y) #Die Antwort, die Sie erwarten sollten
#=> [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
print(np.array(test_y)) #Vom Klassifikator ausgegebene Vorhersage
#=> [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
Oh, genau das gleiche. Mit anderen Worten, es scheint, dass alle Fragen richtig sind.
Prognostizieren Sie den Schlusskurs von 4/9
Lassen Sie uns nun den Aktienkurs am 4. April zum Zeitpunkt des Schreibens vorhersagen.
Basierend auf den 90-Tage-Daten bis zu 4/8 haben wir dies erwartet.
[ 1.00834065 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863
1.02765584 0.99780509 0.98595259 1.00965759 0.9833187 1.01141352
0.99912204 0.99297629] # 4/14-Tage-Renditeindex bis 8
[0] #Daraus abgeleitete Vorhersagen
Die Antwort ist 0, was bedeutet, dass der Aktienkurs fallen wird.
Übrigens, wenn Sie sich die Yahoo! Finance-Seite ansehen, nachdem der Markt erwartungsgemäß am 4. April geschlossen hat.
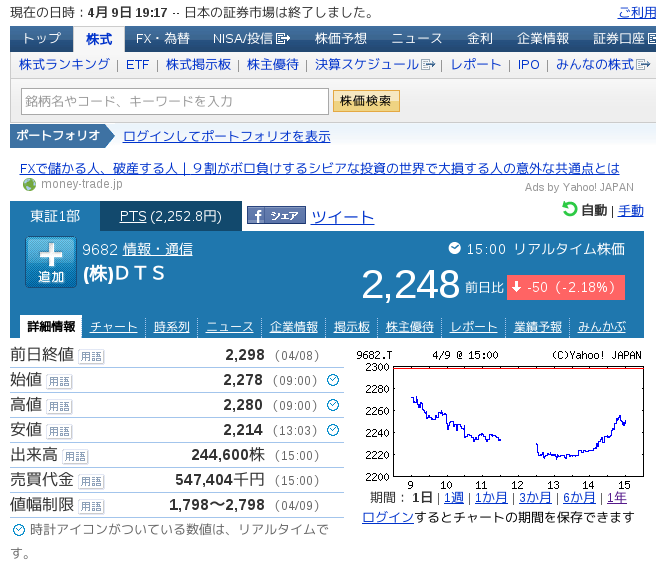
Der Aktienkurs ist um 50 Yen gefallen, was vom Entscheidungsbaum erwartet wird. Ist die richtige Antwort.
Prognostizieren Sie den Schlusskurs von 4/10
Lassen Sie uns abschließend die Vorhersage der Zukunft in Frage stellen. Prognostizieren Sie den Schlusskurs von 4/10.
Es scheint hartnäckig zu sein, aber dieser Artikel wurde am 4/9 geschrieben. bitte bestätigen.
[ 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863 1.02765584
0.99780509 0.98595259 1.00965759 0.9833187 1.01141352 0.99912204
0.99297629 0.98463565] # 4/14-Tage-Renditeindex bis 9
[1] #Der Entscheidungsbaum wird mit 1 vorhergesagt
Die Antwort lautet 1, was bedeutet, dass die Aktienkurse voraussichtlich morgen steigen werden.
Zusammenfassung
Was haben Sie gedacht. Ich glaube, ich konnte einige interessante Vorhersagen treffen.
Wenn dies eine Trefferquote von 100 ist, können Sie einen Gewinn erzielen, indem Sie heute kaufen und morgen verkaufen. Vielleicht war die Vorhersage falsch, und ich frage mich vielleicht, ob ich morgen um diese Zeit einen enttäuschenden Artikel geschrieben habe.
Ich denke, die Anleger schauen verzweifelt auf den Aktienchart und sagen voraus, ob er morgen steigen oder fallen wird. Was ich dieses Mal geschrieben habe, ist, einen Entscheidungsbaum zu verwenden, der eine Methode des maschinellen Lernens ist, und zu versuchen, einen Computer dies tun zu lassen. Sogenannte künstliche Intelligenz.
In Bezug auf das, was hier geschrieben steht, übernehmen wir natürlich keine Garantie, selbst wenn Sie tatsächlich eine echte Transaktion durchführen, und der Autor übernimmt keine Verantwortung, selbst wenn ein Schaden auftritt. Bitte beachten Sie diesen Punkt.
Recommended Posts