[PYTHON] Japanische Übersetzung des Apache Spark-Dokuments - Übersicht über den Cluster-Modus
Eine japanische Übersetzung der folgenden Bereitstellungsübersicht des Apache Spark-Projekts. http://spark.apache.org/docs/latest/cluster-overview.html
Wenn Sie etwas falsch mit der Übersetzung finden, lassen Sie es uns bitte in den Kommentaren wissen.
Die japanischen Übersetzungen von Quick Start und EC2-Einführung sind ebenfalls unten aufgeführt. Schauen Sie also bitte vorbei.
- Quick Start
http://qiita.com/mychaelstyle/items/46440cd27ef641892a58 - Spark on AWS EC2
http://qiita.com/mychaelstyle/items/b752087a0bee6e41c182
Übersicht über den Cluster-Modus
This document gives a short overview of how Spark runs on clusters, to make it easier to understand the components involved. Read through the application submission guide to submit applications to a cluster.
Dieses Dokument bietet einen schnellen Überblick über die Funktionsweise von Spark in einem Cluster, um die komplexen Komponenten leicht zu verstehen. Lesen Sie das Handbuch zur Anwendungsübermittlung, um zu erfahren, wie Sie Ihre Anwendung in einem Cluster bereitstellen.
http://spark.apache.org/docs/latest/submitting-applications.html
Komponenten
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Spark-Anwendungen arbeiten als eine Reihe unabhängiger Prozesse in einem Cluster mit dem SparkContext-Objekt Ihres Anwendungshauptprogramms (als Treiberprogramm bezeichnet) zusammen.
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager or Mesos/YARN), which allocate resources across applications.
Insbesondere stellt SparkContext eine Verbindung zu verschiedenen Arten von Cluster-Managern her (Spark's eigener Standalone-Cluster-Manager oder Mesos / YARN) und weist Ressourcen anwendungsübergreifend zu, um in einem einzelnen Cluster zu arbeiten.
Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks for the executors to run.
Sobald die Verbindung hergestellt ist, erhält Spark Executeros auf den Knoten des Clusters, führt Berechnungen für Ihre Anwendung durch und speichert die Daten. Anschließend wird Ihr Anwendungscode (an SparkContext übergebene JAR- oder Python-Dateien) an die ausführbaren Dateien gesendet. Schließlich sendet SparkContext die Ausführungsaufgaben der ausführbaren Dateien.
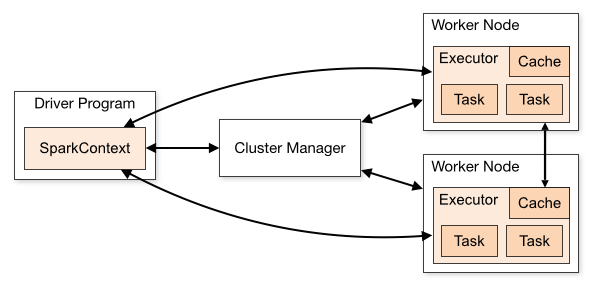
There are several useful things to note about this architecture:
Es gibt einige nützliche Dinge über die Architektur.
- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
Jede Anwendung erhält ihre eigenen ausführbaren Prozesse, während jeder Thread, der eine Aufgabe ausführt, ausgeführt wird. Dies ist sehr nützlich in Bezug auf die Planung (jeder Treiber plant Aufgaben unabhängig) und den Ausführenden (Aufgaben aus verschiedenen Anwendungen, die auf verschiedenen JVMs ausgeführt werden), um jede Anwendung einzeln zu trennen. Dies bedeutet jedoch, dass Daten ohne die Verwendung eines externen Speichersystems nicht von verschiedenen Spark-Anwendungen (SparkContext-Instanzen) gemeinsam genutzt werden können.
- Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
Spark hat nichts mit dem Cluster-Manager zu tun. Während Spark Executor-Prozesse anfordert und miteinander kommuniziert, läuft es auf einem Cluster-Manager, der relativ einfach echte andere Anwendungen unterstützt.
- Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network. If you’d like to send requests to the cluster remotely, it’s better to open an RPC to the driver and have it submit operations from nearby than to run a driver far away from the worker nodes.
Der Treiber plant Aufgaben im Cluster und sollte in der Nähe einer Reihe von Arbeitsknoten ausgeführt werden, anstatt innerhalb desselben lokalen Netzwerks. Wenn Sie Anforderungen remote senden möchten, ist es besser, Ihre Anwendung mit RPC zu senden und in der Nähe auszuführen, als sie aus der Ferne in den Arbeitsknoten auszuführen.
Recommended Posts