[PYTHON] Sinuswellenvorhersage mit RNN in der Deep-Learning-Bibliothek Keras
Einführung
Keras ist eine Deep-Learning-Wrapper-Bibliothek, die auf Theano und TensorFlow basiert. Dank Theano und TensorFlow ist es viel einfacher geworden, tief zu lernen, aber es ist immer noch schwierig, den Algorithmus zu schreiben. Keras ist also eine Bibliothek, die es ermöglicht, eine Netzwerkstruktur ziemlich einfach zu schreiben. Für einen Überblick über Keras selbst war id: Artikel des Hilfsmittels sehr hilfreich.
Als Basisbeispiel für Keras sehe ich viele MNIST-Klassifizierungen, aber ich konnte mit RNN nicht viele einfache Beispiele finden (Keras offiziell [Beispiel für eine Emotionsklassifizierung von Filmen mit RNN]) http://rnn.classcat.com/2016/04/05/keras-snippet-cnn-lstm-for-imdb/), aber es war zunächst zu kompliziert, um damit umzugehen). Daher werden wir dieses Mal die RNN-Implementierung von Keras anhand eines einfachen Beispiels für das Training und die Vorhersage von Sinuswellen in LSTM ausprobieren. Für die RNN-Implementierung mit TensorFlow habe ich zuvor einen Artikel über hier geschrieben. Wenn Sie also interessiert sind, lesen Sie dies bitte.
2017.11.20 Nachtrag
Dieses Mal prognostizieren wir Sinuswellen mit Schwerpunkt auf Verständlichkeit. Da wir jedoch kompliziertere Zeitreihendaten verarbeiten wollten, haben wir [Python] QRNN verwendet, um Chaos-Zeitreihendaten [Keras]] vorherzusagen (https://qiita.com). Ich habe einen Artikel namens / yukiB / items / 681f68690ffabbf3e1e1) erstellt.
Installation
Keras kann sowohl Theano als auch Tensorflow als Backends verwenden, und in Keras geschriebene Programme können jederzeit ohne Änderungen zwischen Backends gewechselt werden (Es scheint einige Einschränkungen zu geben. / nzw0301 / items / 2823243090b997aa00e5)), aber dieses Mal werde ich die Methode mit TensorFlow als Backend ausprobieren.
Es wird davon ausgegangen, dass TensorFlow im Voraus installiert wurde.
Die Keras-Installation erfolgt normalerweise mit pip
pip install keras
Aber es ist okay,
Nachdem Git die Quelle geklont hat,
python setup.py install
Aber es ist okay.
Wenn Sie TensorFlow als Backend verwenden, schreiben Sie die Einstellungsdatei ~ / .keras / keras.json wie folgt neu (siehe Keras-Dokumentation. Keras.json. Wird durch erstes Starten (Importieren usw.) von Keras generiert.
# before
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
# after
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Das Standard-Backend ist für Theano, aber mit der obigen Umschreibung,
import keras
Wenn Sie das tun
Using TensorFlow backend.
Sollte angezeigt werden.
Lassen Sie uns die Sündenwelle mit Keras 'LSTM vorhersagen.
Datenerstellung
Erstellen Sie zunächst die Daten. Die Daten wurden von yuyakato's Ich habe versucht vorherzusagen, indem ich RNN Sündenwellen lernen ließ erstellt. Ich durfte mich beziehen.
import pandas as pd
import numpy as np
import math
import random
%matplotlib inline
random.seed(0)
#Zufälliger Koeffizient
random_factor = 0.05
#Anzahl der Schritte pro Zyklus
steps_per_cycle = 80
#Anzahl der zu generierenden Zyklen
number_of_cycles = 50
df = pd.DataFrame(np.arange(steps_per_cycle * number_of_cycles + 1), columns=["t"])
df["sin_t"] = df.t.apply(lambda x: math.sin(x * (2 * math.pi / steps_per_cycle)+ random.uniform(-1.0, +1.0) * random_factor))
df[["sin_t"]].head(steps_per_cycle * 2).plot()
Erstellen Sie eine Sinuswelle mit Rauschen, wie unten gezeigt.

Klassifizieren Sie dies als Nächstes in Trainingsdaten und Testdaten und erstellen Sie einen Datensatz, sodass die Ausgabe y bei Eingabe X für 100 Schritte der 101. Schritt ist.
def _load_data(data, n_prev = 100):
"""
data should be pd.DataFrame()
"""
docX, docY = [], []
for i in range(len(data)-n_prev):
docX.append(data.iloc[i:i+n_prev].as_matrix())
docY.append(data.iloc[i+n_prev].as_matrix())
alsX = np.array(docX)
alsY = np.array(docY)
return alsX, alsY
def train_test_split(df, test_size=0.1, n_prev = 100):
"""
This just splits data to training and testing parts
"""
ntrn = round(len(df) * (1 - test_size))
ntrn = int(ntrn)
X_train, y_train = _load_data(df.iloc[0:ntrn], n_prev)
X_test, y_test = _load_data(df.iloc[ntrn:], n_prev)
return (X_train, y_train), (X_test, y_test)
length_of_sequences = 100
(X_train, y_train), (X_test, y_test) = train_test_split(df[["sin_t"]], n_prev =length_of_sequences)
Modellieren
Nachdem das Dataset vollständig ist, ist es Zeit, die Netzwerkkonfiguration mit Keras zu schreiben.
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
in_out_neurons = 1
hidden_neurons = 300
model = Sequential()
model.add(LSTM(hidden_neurons, batch_input_shape=(None, length_of_sequences, in_out_neurons), return_sequences=False))
model.add(Dense(in_out_neurons))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05)
Nur das. Wie oben erwähnt, kann die Struktur des neuronalen Netzes durch "Hinzufügen ()" verschiedener Schichten zu "Modell" konstruiert werden. Im obigen Beispiel wird eine Eingabe mit einem (, 100, 1) -Tensor in 300 LSTM-Zwischenschichten geworfen, zu einer Ausgabeschicht aggregiert und mit einer linearen Aktivierungsfunktion multipliziert.
Übrigens ist LSTM eine dreidimensionale Form mit einem Eingabetensor (batch_size, input_length, in_data_length). Die Ausgabe ist
- return_sequences=True -> (batch_size, input_length, out_data_length)
- return_sequences=False -> (batch_size, out_data_length)
Das ist die Form.
Geben Sie beim Kompilieren des Modells die Fehlerfunktion (mittlerer quadratischer Fehler im Beispiel) und den Optimierungsalgorithmus (RMSprop im Beispiel) an. Natürlich kann Kreuzentropie für die Fehlerfunktion verwendet werden, und die Optimierungsalgorithmen sind von der grundlegenden SGD bis zu Adam und RMSprop vollständig.
Das Training wird mit "fit ()" durchgeführt, und Sie können angeben, wie viel Prozent der Trainingsdaten als Trainingsdaten und Lehrerdaten, Stapelgröße, Epochengröße und Validierungsdaten verwendet werden sollen.
Ebenfalls,
# early stopping
early_stopping = EarlyStopping(monitor='val_loss', patience=2)
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05, callbacks=[early_stopping])
Durch Angabe des Rückrufs für die Konvergenzbeurteilung wie in kann die Schleife automatisch gestoppt werden, wenn sie konvergiert.
Train on 3325 samples, validate on 176 samples
Epoch 1/15
3325/3325 [==============================] - 17s - loss: 0.0051 - val_loss: 0.0048
Epoch 2/15
1200/3325 [=========>....................] - ETA: 10s - loss: 0.0041
Wenn Sie mit dem Lernen beginnen, zeigt Ihnen der Balken den Lernfortschritt an, z. B. Vorhersage der Lernzeit, Zeitaufwand für das Lernen in jeder Epoche, Verlust / Genauigkeit der Trainingsdaten, Verlust / Genauigkeit der Validierungsdaten (wie oben beschrieben). Praktisch!).
Prognose
Vorhersage anhand von Trainingsdaten
predicted = model.predict(X_test)
Dies geschieht mit pred () wie in.
In diesem Beispiel
dataf = pd.DataFrame(predicted[:200])
dataf.columns = ["predict"]
dataf["input"] = y_test[:200]
dataf.plot(figsize=(15, 5))

Das Vorhersageergebnis ist wie folgt.
Keras unterstützt auch die Modellvisualisierung, und Sie können das Modell einfach mit Pygraphvis usw. visualisieren. Da ich dieses Mal jupyter verwendet habe, habe ich IPython.display.SVG und
from IPython.display import SVG
from keras.utils.visualize_util import model_to_dot, plot
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
Beim Schreiben wird das folgende Modelldiagramm erstellt (Sie müssen pydot mit pip, graphviz mit homebrew usw. installieren).
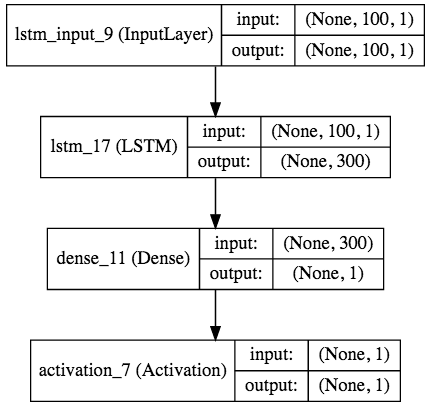
abschließend
Wie Sie sehen können, können Sie mit Keras Modellierungscode sehr präzise schreiben. Ich werde weiterhin kompliziertere Modelle mit Keras ausprobieren.
Verweise
- Keras Official (http://keras.io/)
- Eine Aufzeichnung der künstlichen Intelligenz (http://aidiary.hatenablog.com/entry/20160328/1459174455)
- Ich habe RNN die Sündenwelle lernen lassen und eine Vorhersage gemacht (http://qiita.com/yuyakato/items/ab38064ca215e8750865)
- Lassen Sie Keras das Modell visualisieren! !! (http://ket-30.hatenablog.com/entry/keras/graph)
Recommended Posts