[PYTHON] Big-Data-Analyse mit dem Datenflusskontroll-Framework Luigi
Was ist Luigi?
Luigi ist ein in Python geschriebenes Framework zur Steuerung des Datenflusses. Entwickelt von Spotify, einem großen Vertriebsunternehmen für Streaming-Musik. Die Partnerschaft mit Sony wurde ebenfalls ein heißes Thema.
- Offizielles Luigi-Repository
- Präsentationsmaterial der Hauptfamilie ist leicht zu verstehen.
Im Allgemeinen ist es bei der Big-Data-Analyse erforderlich, eine Reihe von Bereinigungs- und Filterprozessen durchzuführen, bevor statistische und maschinelle Lernvorgänge durchgeführt werden. Die Abhängigkeiten sind kompliziert, und wenn Sie anfangen, Daten zu ersetzen oder im Falle eines Fehlers oder einer Unterbrechung zu wiederholen, ist dies nichts weiter als eine Buße. In einem solchen Fall kann Luigi verwendet werden.
Der Ursprung des Namens Luigi liegt darin, dass der Datenfluss mit einem Wasserverteilungsrohr verglichen wird, "dem zweitberühmtesten Rohrarbeiter der Welt, der grüne Kleidung trägt". Vielleicht ist es grün statt rot, weil es der Unternehmensfarbe von Spotify entspricht (lacht).
Obwohl es Python ist, ist es einfach, es mit Hadoop- und Treasure-Daten zu kombinieren sowie von Python zu verarbeiten. Es ist ein super leistungsfähiges Tool, das alle Funktionen bietet, die Sie für die Datenanalyse benötigen. Es scheint jedoch, dass die Anerkennung in Japan noch nicht so hoch ist. Deshalb möchte ich es für Missionszwecke vorstellen.
Hauptmerkmale
- Kann Datenverarbeitungsaufgaben objektorientiert schreiben
- Lösen Sie die Abhängigkeit zwischen Aufgaben von Downstream zu Upstream
- Wenn ein Fehler auftritt, wird er dort gestoppt
- Einfach fortzusetzen, wo es fehlgeschlagen ist
- Stellen Sie die Gleichheit sicher, indem Sie das Ende einer Aufgabe anhand des Vorhandenseins oder Nichtvorhandenseins eines Ausgabeobjekts bestimmen
- Verhält sich wie ein Cache, wenn eine Aufgabe ausgeführt wird, die sich auf dieselben Daten bezieht
- Einfache Externalisierung von Parametern in der Datenverarbeitung
- Perfekte Zusammenarbeit mit der Datenbank-Engine Hadoop (HDFS, MapReduce Streaming, Hive, Spark!)
- Datenflussabhängigkeiten und -fortschritte können mit einem Webbrowser visualisiert werden
- Hat eine Kommandozeilenschnittstelle (ziemlich reichhaltig)
- Wenn Sie es so wie es ist in Git werfen, können Sie die Version gut verwalten
- Einfach zu schreibende Tests, da es sich um eine Python-Klasse handelt
Wie auch immer, es ist alles gut. Das einzig bedauerliche ist, dass Sie den Prozess nicht über den Browser aktivieren können. Außerdem ist das Handbuch zu Hadoop nicht entwickelt, und ich muss die Quelle lesen, um die Spezifikationen zu verstehen.
Einführungsmethode
sudo pip install luigi
Dies ist alles, was Sie eingeben müssen.
Wie schreibt man
Die minimale Verarbeitungseinheit ist Aufgabe
Die kleinste Einheit der Luigi-Verarbeitung heißt Task und wird verwaltet. Schreiben Sie eine Klasse, die die Klasse luigi.Task () für 1Task erbt.
So beschreiben Sie die Abhängigkeit zwischen Aufgaben
Luigi beschreibt eine Kette von Datenflüssen durch Verknüpfung von Downstream zu Upstream.
Die Klasse luigi.Task () hat die folgende Methode als Methode.
require (): Abhängige Upstream-Taskoutput (): Ausgabeobjekt (Dateiname inluigi.Target ()Familienklasse eingeschlossen)run (): Verarbeitung in Task

Auf diese Weise müssen Sie Ihre Abhängigkeiten nicht überladen. Außerdem müssen Sie die Datei nicht zweimal auf der abhängigen Seite und auf der abhängigen Seite schreiben.
Rufen Sie bei der Ausführung die nachgelagerte Aufgabe auf. Auf diese Weise löst Luigi die Abhängigkeit automatisch stromaufwärts auf und führt sie der Reihe nach aus. Wenn Sie zu diesem Zeitpunkt mehrere "--workers" -Optionen festlegen, werden die Teile, die parallelisiert werden können, automatisch parallel ausgeführt.
Illustration
Von hier, Luigis offizielles Beispiel [top_artists.py](https://github.com/spotify/luigi/blob/master/examples/top_artists.py Mal sehen, wie man am Beispiel schreibt.
Dies ist ein Skript, das die tägliche Aggregation von Künstleransichten nachahmt. Die Wiedergabeprotokolle der Songs werden täglich aggregiert und die 10 besten Künstler werden extrahiert.
In top_artists.py, Top10Artists () [Sortieren und Ausgeben der ersten 10] -> AggrigateArtists () [Aggregieren Sie die Anzahl der Ansichten für jeden Künstler]
-> Der Datenfluss wird als "Streams ()" [tägliches Protokoll] beschrieben.
top_artists.py
class Top10Artists(luigi.Task):
"""
This task runs over the target data returned by :py:meth:`~/.AggregateArtists.output` or
:py:meth:`~/.AggregateArtistsHadoop.output` in case :py:attr:`~/.Top10Artists.use_hadoop` is set and
writes the result into its :py:meth:`~.Top10Artists.output` target (a file in local filesystem).
"""
date_interval = luigi.DateIntervalParameter()
use_hadoop = luigi.BoolParameter()
def requires(self):
"""
This task's dependencies:
* :py:class:`~.AggregateArtists` or
* :py:class:`~.AggregateArtistsHadoop` if :py:attr:`~/.Top10Artists.use_hadoop` is set.
:return: object (:py:class:`luigi.task.Task`)
"""
if self.use_hadoop:
return AggregateArtistsHadoop(self.date_interval)
else:
return AggregateArtists(self.date_interval)
def output(self):
"""
Returns the target output for this task.
In this case, a successful execution of this task will create a file on the local filesystem.
:return: the target output for this task.
:rtype: object (:py:class:`luigi.target.Target`)
"""
return luigi.LocalTarget("data/top_artists_%s.tsv" % self.date_interval)
def run(self):
top_10 = nlargest(10, self._input_iterator())
with self.output().open('w') as out_file:
for streams, artist in top_10:
out_line = '\t'.join([
str(self.date_interval.date_a),
str(self.date_interval.date_b),
artist,
str(streams)
])
out_file.write((out_line + '\n'))
def _input_iterator(self):
with self.input().open('r') as in_file:
for line in in_file:
artist, streams = line.strip().split()
yield int(streams), artist
Das Innere jeder Methode kann in gewöhnlichem Python geschrieben werden. Daher ist es möglich, die Abhängigkeit gemäß dem von außen angegebenen Parameter zu wechseln und die Abhängigkeit zu mehreren Aufgaben mithilfe einer Liste oder eines Wörterbuchs zu beschreiben.
Im Beispiel von top_artitsts.py gibt die Aufgabe von "AggrigateArtists ()" das tägliche Protokoll zurück. Durch Verweisen auf mehrere Aufgaben von "Streams ()" in der Liste werden die täglichen Daten für einen Monat aggregiert.
Geben Sie den folgenden Befehl ein, um ihn auszuführen.
python top_artists.py Top10Artists --date-interval 2015-03 --local-scheduler
Luigi Scheduler
Der Befehl luigid startet den Scheduler. Selbst wenn eine große Anzahl von Aufgaben von mehreren Clients empfangen wird, werden sie der Reihe nach ausgeführt.
Wenn Sie über Ihren Browser auf "localhost: 8082" zugreifen, können Sie den Fortschritt der Verarbeitung und der Abhängigkeiten visualisieren.
Um eine Aufgabe an den Scheduler zu senden, führen Sie sie ohne die Option "--local-scheduler" aus.
python top_artists.py Top10Artists --date-interval 2015-03
Ein Beispiel für die Visualisierung der Abhängigkeiten ist unten dargestellt.
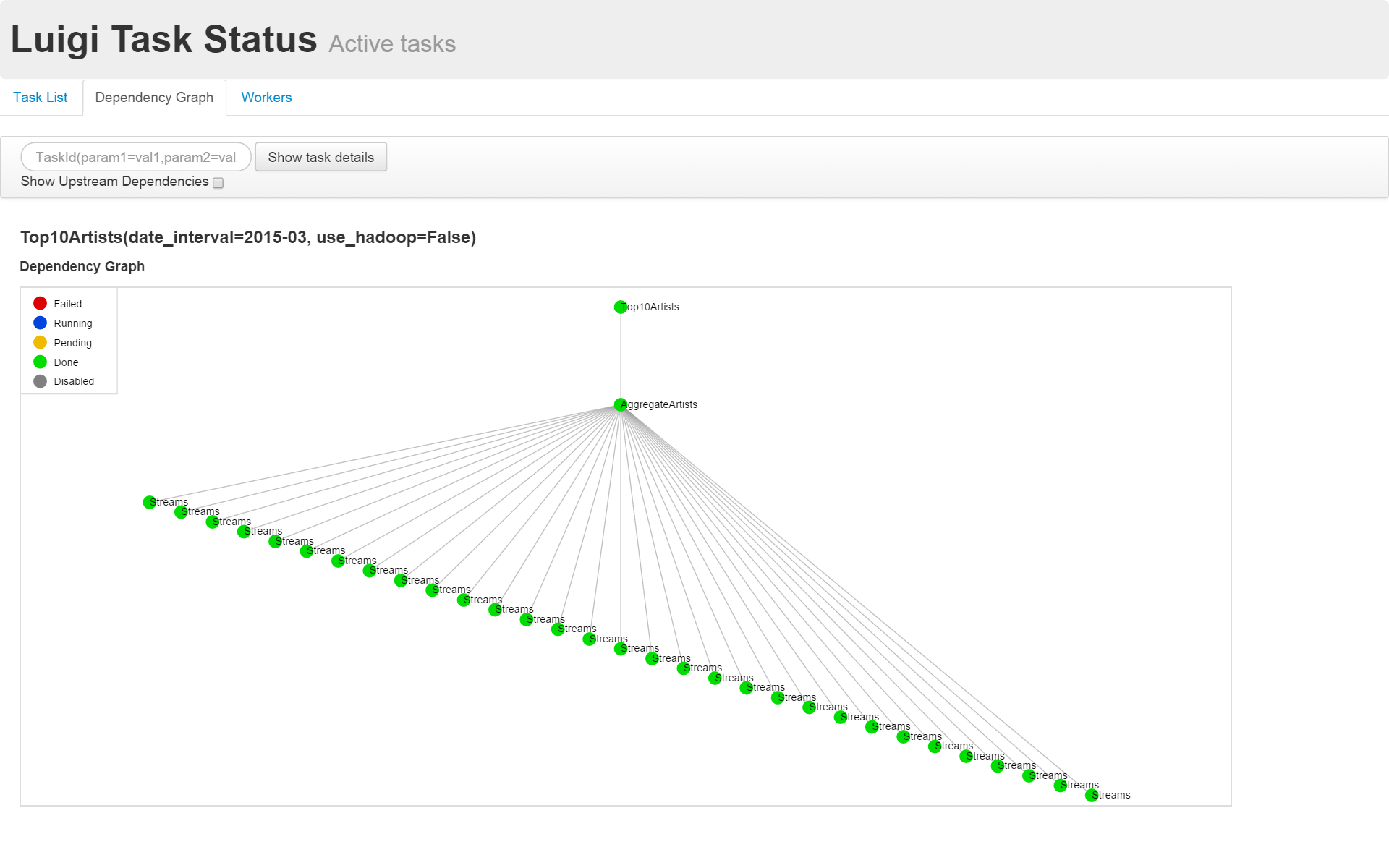
Anwendungsbeispiel
Ich habe versucht, Luigi für mein Common Kanji Analysis Script zu verwenden. Ich wage es, die in Ruby geschriebenen Filterbefehle mit Luigi zu verbinden, anstatt sie mit der UNIX-Pipeline zu verbinden. Es ist etwas überimplementiert, aber es ist einfacher, den Vorgang zu überprüfen, da die Zwischendateien sicher übrig bleiben. Außerdem ist es ordentlich, weil Sie es nicht zweimal auf die Seite schreiben müssen, die vom Dateinamen abhängt.
... Es tut mir leid, keines der oben genannten war Big Data.
Recommended Posts