[PYTHON] 4. Erstellen eines strukturierten Programms
4.1 Back to the Basics Assignment
Zuweisung ist eines der wichtigsten Konzepte in einem Programm. Aber es gibt einige erstaunliche Dinge! !!
>>> foo = 'Monty'
>>> bar = foo # (1)
>>> foo = 'Python' # (2)
>>> bar
'Monty'
Wenn Sie im obigen Code bar = foo schreiben, wird der Wert von foo (Zeichenfolge 'Monty') in (1) bar zugewiesen. Mit anderen Worten, bar ist eine Kopie von foo, sodass das Überschreiben von foo mit der neuen Zeichenfolge 'Python'on line (2) den Wert von bar nicht beeinflusst.
Die Zuweisung kopiert den Wert eines Ausdrucks, aber der Wert entspricht nicht immer Ihren Erwartungen! !! !! Insbesondere die Werte strukturierter Objekte wie Listen sind eigentlich nur Verweise auf die Objekte! Im folgenden Beispiel weist (1) der Variablenleiste einen Verweis auf foo zu. Wenn Sie das Innere von foo in der nächsten Zeile ändern, wird auch der Wert von bar geändert
>>> foo = ['Monty', 'Python']
>>> bar = foo # (1)
>>> foo[1] = 'Bodkin' # (2)
>>> bar
['Monty', 'Bodkin']
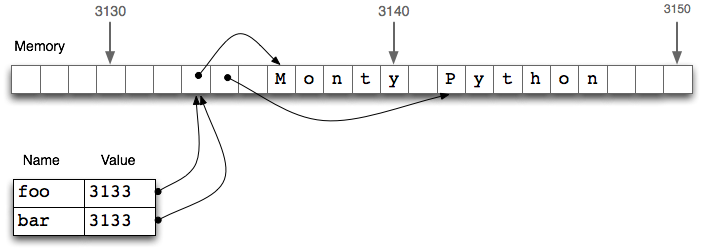
bar = foo kopiert nicht den Inhalt der Variablen, sondern nur deren ** Objektreferenz **! !! Dies ist eine Referenz auf das Objekt, das an Position 3133 in foo gespeichert ist. Wenn Sie bar = foo zuweisen, wird nur die Objektreferenz 3133 kopiert, sodass durch das Aktualisieren von foo auch der Balken geändert wird!
Erstellen wir eine leere Variable, die eine leere Liste enthält, und verwenden Sie sie dreimal in der nächsten Zeile für weitere Experimente.
>>> empty = []
>>> nested = [empty, empty, empty]
>>> nested
[[], [], []]
>>> nested[1].append('Python')
>>> nested
[['Python'], ['Python'], ['Python']]
Als ich eines der Elemente in der Liste geändert habe, haben sich alle geändert! !! ?? ?? Sie können sehen, dass jedes der drei Elemente tatsächlich nur ein Verweis auf ein und dieselbe Liste im Speicher ist! !!
Beachten Sie, dass wenn Sie einem der Elemente in der Liste einen neuen Wert zuweisen, dieser nicht in den anderen Elementen wiedergegeben wird!
>>> nested = [[]] * 3
>>> nested[1].append('Python')
>>> nested[1] = ['Monty']
>>> nested
[['Python'], ['Monty'], ['Python']]
In der dritten Zeile wurde eine der drei Objektreferenzen in der Liste geändert. Das 'Python'-Objekt hat sich jedoch nicht geändert. Dies liegt daran, dass Sie das Objekt über die Objektreferenz ändern und die Objektreferenz nicht überschreiben!
Equality Python bietet zwei Möglichkeiten, um sicherzustellen, dass das Elementpaar identisch ist. ist Testen Sie den Bediener auf Objektidentifikation. Dies kann verwendet werden, um frühere Beobachtungen über das Objekt zu validieren.
>>> size = 5
>>> python = ['Python']
>>> snake_nest = [python] * size
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
True
Erstellen Sie eine Liste mit mehreren Kopien desselben Objekts und zeigen Sie, dass diese nicht nur gemäß == identisch sind, sondern auch ein und dasselbe Objekt.
>>> import random
>>> position = random.choice(range(size))
>>> snake_nest[position] = ['Python']
>>> snake_nest
[['Python'], ['Python'], ['Python'], ['Python'], ['Python']]
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
False
Die Funktion id () erleichtert das Erkennen!
>>> [id(snake) for snake in snake_nest]
[513528, 533168, 513528, 513528, 513528]
Dies sagt uns, dass das zweite Element in der Liste eine separate Kennung enthält!
Conditionals Im bedingten Teil der if-Anweisung wird eine nicht leere Zeichenfolge oder Liste als wahr und eine leere Zeichenfolge oder Liste als falsch ausgewertet.
>>> mixed = ['cat', '', ['dog'], []]
>>> for element in mixed:
... if element:
... print element
...
cat
['dog']
Mit anderen Worten, es ist nicht erforderlich, wenn len (Element)> 0: unter der Bedingung ist.
>>> animals = ['cat', 'dog']
>>> if 'cat' in animals:
... print 1
... elif 'dog' in animals:
... print 2
...
1
Wenn elif durch if ersetzt wird, werden sowohl 1 als auch 2 ausgegeben. Daher enthält die elif-Klausel möglicherweise mehr Informationen als die if-Klausel.
4.2 Sequences Diese als Tupel bezeichnete Sequenz wird vom Kommaoperator gebildet und in Klammern eingeschlossen. Sie können den angegebenen Teil auch anzeigen, indem Sie einen Index wie eine Zeichenfolge hinzufügen.
>>> t = 'walk', 'fem', 3
>>> t
('walk', 'fem', 3)
>>> t[0]
'walk'
>>> t[1:]
('fem', 3)
>>> len(t)
3
Ich habe Strings, Listen und Taples direkt verglichen und versucht, Indizierungs-, Slicing- und Längenoperationen für jeden Typ durchzuführen!
>>> raw = 'I turned off the spectroroute'
>>> text = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> pair = (6, 'turned')
>>> raw[2], text[3], pair[1]
('t', 'the', 'turned')
>>> raw[-3:], text[-3:], pair[-3:]
('ute', ['off', 'the', 'spectroroute'], (6, 'turned'))
>>> len(raw), len(text), len(pair)
(29, 5, 2)
Operating on Sequence Types
Verschiedene Möglichkeiten, eine Sequenz zu iterieren

Verwenden Sie reverse (sortiert (set (s))), um die eindeutigen Elemente von s in umgekehrter Reihenfolge zu sortieren. Sie können random.shuffle (s) verwenden, um den Inhalt der Liste s vor dem Iterieren zufällig zu sortieren.
FreqDist kann in Sequenzen umgewandelt werden!
>>> raw = 'Red lorry, yellow lorry, red lorry, yellow lorry.'
>>> text = word_tokenize(raw)
>>> fdist = nltk.FreqDist(text)
>>> sorted(fdist)
[',', '.', 'Red', 'lorry', 'red', 'yellow']
>>> for key in fdist:
... print(key + ':', fdist[key], end='; ')
...
lorry: 4; red: 1; .: 1; ,: 3; Red: 1; yellow: 2
Ordne den Inhalt der Liste mit Hilfe von Tapples neu an !!
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> words[2], words[3], words[4] = words[3], words[4], words[2]
>>> words
['I', 'turned', 'the', 'spectroroute', 'off']
zip () nimmt zwei oder mehr Sequenzen von Elementen und "komprimiert" sie zu einer einzigen Liste von Tupeln! In Anbetracht der Sequenz s gibt enumerate (s) ein Paar zurück, das aus dem Index und den Elementen an diesem Index besteht.
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> tags = ['noun', 'verb', 'prep', 'det', 'noun']
>>> zip(words, tags)
<zip object at ...>
>>> list(zip(words, tags))
[('I', 'noun'), ('turned', 'verb'), ('off', 'prep'),
('the', 'det'), ('spectroroute', 'noun')]
>>> list(enumerate(words))
[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]
Combining Different Sequence Types
>>> words = 'I turned off the spectroroute'.split() # (1)
>>> wordlens = [(len(word), word) for word in words] # (2)
>>> wordlens.sort() # (3)
>>> ' '.join(w for (_, w) in wordlens) # (4)
'I off the turned spectroroute'
Ein String ist eigentlich ein Objekt, in dem Methoden wie split () definiert sind. Erstellen Sie eine Liste von Taples mit der Listeneinschlussnotation in (2). Jeder Taple besteht aus einer Zahl (Wortlänge) und einem Wort (z. B. (3, 'the')). Verwenden Sie die sort () -Methode, um die (3) -Liste im laufenden Betrieb zu sortieren! Schließlich werden in (4) die Längeninformationen verworfen und die Wörter wieder zu einer Zeichenkette zusammengefasst.
** In Python sind Listen variabel und Taples unveränderlich. Das heißt, Sie können die Liste ändern, aber nicht den Tapple !!! **
Generator Expressions
>>> text = '''"When I use a word," Humpty Dumpty said in rather a scornful tone,
... "it means just what I choose it to mean - neither more nor less."'''
>>> [w.lower() for w in word_tokenize(text)]
['``', 'when', 'i', 'use', 'a', 'word', ',', "''", 'humpty', 'dumpty', 'said', ...]
Ich möchte diese Worte weiter verarbeiten.
>>> max([w.lower() for w in word_tokenize(text)]) # (1)
'word'
>>> max(w.lower() for w in word_tokenize(text)) # (2)
'word'
Recommended Posts