[PYTHON] Speichern Sie die Ausgabe von GAN nacheinander ~ Mit der Implementierung von GAN durch PyTorch ~
Während ich mich in meiner Abschlussforschung mit GAN beschäftigte, wurde es notwendig, die von GAN erzeugten Bilder einzeln zu speichern.
Selbst wenn Sie nachschlagen, haben alle Artikel, die GAN implementieren, eine Ausgabe wie diese ...

Anstatt mehrere Blätter gleichzeitig auszugeben, werden diese einzeln ausgegeben. Ich werde es auch als Memorandum schreiben.
Zweck
Implementieren Sie GAN und speichern Sie GAN-generierte Bilder nacheinander
GAN GAN (Generative Adversarial Network): Das feindliche Generationsnetzwerk ist ein Generationsmodell, das von Ian J. Goodfellow vorgeschlagen wurde. Generative Adversarial Nets
Die Grundstruktur von GAN sieht so aus
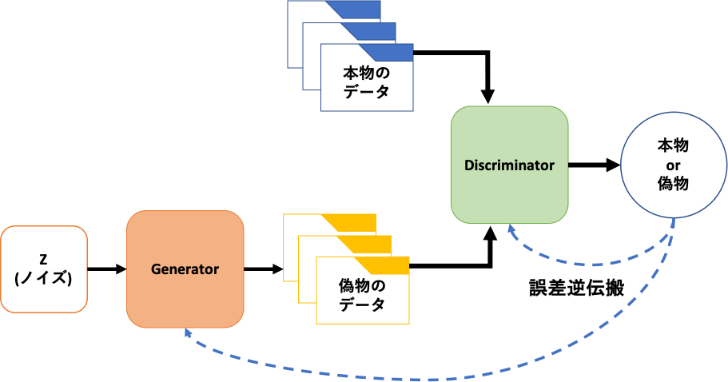
Wir haben zwei Netzwerke und werden mit dem Lernen fortfahren, während wir miteinander konkurrieren. __Generator: Generator __ Erzeugt ein Bild, das täuschen kann. Verschiedene Dinge wie DCGAN, die GAN berühmt gemacht haben, und StyleGAN, die erstaunlich realistische Bilder erzeugen. Die Architektur wird vorgeschlagen.
Implementierung von GAN
Fahren wir nun mit der Implementierung von GAN fort. Dieses Mal werden wir DCGAN implementieren. Der als Referenz für die Implementierung verwendete Code lautet hier.
Ausführungsumgebung
Google Colaboratory
Verzeichnis importieren und erstellen
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch
os.makedirs("./images", exist_ok=True)
Importieren Sie die erforderlichen Module. Dieses Mal werden wir es mit PyTorch implementieren. Erstellen Sie auch ein Verzeichnis, um das Ausgabe-Image von GAN zu speichern. Da es "exist_ok = True" ist, wird es durchlaufen, wenn das Verzeichnis bereits existiert.
Befehlszeilenargument & Standardwerteinstellung
Ermöglicht die Angabe von Werten wie Epochennummer und Stapelgröße in der Befehlszeile. Stellen Sie gleichzeitig den Standardwert ein. Für die Anzahl der Epochen und die Stapelgröße ist der Artikel hier leicht zu verstehen.
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
Wenn Sie die Befehlszeile verwenden können, können Sie sie unverändert lassen. Wenn Sie sie jedoch mit Google Colaboratory implementieren, tritt der folgende Fehler auf.
usage: ipykernel_launcher.py [-h] [--n_epochs N_EPOCHS]
[--batch_size BATCH_SIZE] [--lr LR] [--b1 B1]
[--b2 B2] [--n_cpu N_CPU]
[--latent_dim LATENT_DIM] [--img_size IMG_SIZE]
[--channels CHANNELS]
[--sample_interval SAMPLE_INTERVAL]
ipykernel_launcher.py: error: unrecognized arguments: -f /root/.local/share/jupyter/runtime/kernel-ecf689bc-740f-4dea-8913-e0d8ac0b1761.json
An exception has occurred, use %tb to see the full traceback.
SystemExit: 2
/usr/local/lib/python3.6/dist-packages/IPython/core/interactiveshell.py:2890: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Wenn Sie in Google Colab die Zeile "opt = parser.parse_args ()" als "opt = parser.parse_args (args = [])" eingeben, wird sie übergeben.
CUDA-Einstellungen und Gewichtsinitialisierung
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
Wenn Sie keine GPU verwenden, dauert das Erlernen erheblich. Ermöglichen Sie daher die Verwendung von CUDA (GPU). Vergessen Sie nicht, die Laufzeiteinstellung in Google Colab auf GPU zu ändern.
Generator Generator: Definiert das Generatornetzwerk.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
Discriminator Diskriminator: Definiert das Netzwerk der Diskriminatoren.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
Verlustfunktionseinstellungen und Netzwerkeinstellungen
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
Erstellen eines DataLoader
Wir werden einen DataLoader erstellen. Dieses Mal generieren wir ein Bild mit dem MNIST-Datensatz. MNIST: Bilddatensatz handgeschriebener Zahlen
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST("./data/mnist",train=True,download=True,
transform=transforms.Compose([
transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),batch_size=opt.batch_size,shuffle=True,
)
Training Wir werden GAN trainieren.
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Tensor(imgs.shape[0], 1).fill_(1.0)
fake = Tensor(imgs.shape[0], 1).fill_(0.0)
# Configure input
real_imgs = imgs.type(Tensor)
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png " % batches_done, nrow=5, normalize=True)
Ausführungsergebnis
Da das Ergebnis in regelmäßigen Abständen gespeichert wird, betrachten wir das Ausführungsergebnis als GIF-Bild.

Die Zahlen werden generiert, damit die Benutzer sie richtig sehen können.
Ich möchte Bilder einzeln speichern
Ich glaube nicht, dass es so viele Leute gibt, aber ich konnte sie auch nach dem Überprüfen nicht finden, also werde ich sie teilen. Es war im Trainingsteil oben
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png " % batches_done, nrow=5, normalize=True)
Wenn Sie diesen Teil wie folgt ändern, können Sie ihn einzeln speichern.
if batches_done % opt.sample_interval == 0:
save_gen_img = gen_img[0]
save_image(save_gen_imgs, "images/%d.png " % batches_done, normalize=True)
Wenn Sie mehrere Blätter einzeln speichern, ist es meiner Meinung nach in Ordnung, wenn Sie die Anzahl der Blätter "save_image" wiederholen, die Sie in der for-Anweisung verwenden möchten. ~~ Die Trainingszeit wird sich dramatisch erhöhen ~~ Damit haben wir den ursprünglichen Zweck erreicht, die Ausgabe von GAN einzeln zu speichern.
Zusammenfassung
Dieses Mal haben wir DCGAN mit PyTorch implementiert und es ermöglicht, die Ausgabe von GAN einzeln zu speichern, und bestätigt, dass tatsächlich handschriftliche Zahlen generiert wurden. Als nächstes werde ich über bedingtes GAN (cGAN) schreiben, das die Ausgabe von GAN steuern kann. Ebenso kann cGAN ein Bild für jede Klasse speichern.
Recommended Posts