[PYTHON] Ich habe versucht, die Wetterkarte einer Clusteranalyse zu unterziehen
Einführung
Haben Sie jemals von Wörtern wie West-Hoch-Ost-Tief und Winter-Druckverteilung gehört? In der Nähe von Japan gibt es verschiedene Muster der Druckverteilung, und die winterliche Druckverteilung namens West High East Low ist wahrscheinlich die bekannteste (siehe Abbildung unten). Es gibt verschiedene andere Arten, wie beispielsweise eine sommerliche Druckverteilung, die vom pazifischen Hochdruck abgedeckt wird. In diesem Artikel werde ich versuchen, dieses Muster durch unbeaufsichtigtes Lernen zu klassifizieren.
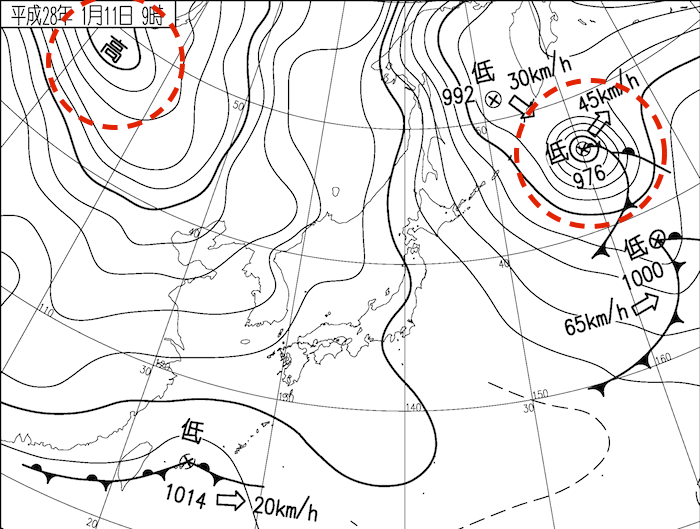 (Aus Wetternachrichten)
(Aus Wetternachrichten)
Diesmal habe ich die folgenden drei Dinge getan.
- Satellitenbilder kratzen
- Ellenbogenmethode
- Clusteranalyse (unbeaufsichtigtes Lernen)
Aufnahme von Satellitenbildern
Das Satellitenbild wurde von der Website des Enamiyama Meteorological Museum aufgenommen. Das liegt daran, dass diese Site zum Herunterladen von Zeilendaten schwer war und gut aussah, um mit gut verarbeiteten Daten zu kratzen. Ursprünglich erscheint es angemessen, bei HP des Meteorological Business Support Center zu kaufen, daher ist dieser Bereich ein Selbsturteil Vielen Dank. Der Quellcode wird hier nicht angezeigt, ist jedoch in github aufgeführt.
Das Bild, das ich verwendet habe, ist ein Bild von 12:00 (JST) in der Nähe von Japan und das folgende Bild (854 x 480 Pixel). 
Vorverarbeitung
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
import glob
from tqdm import tqdm
from os import makedirs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
x=np.empty((0,240*427))
paths=glob.glob("pictures/*.jpg ")
for path in tqdm(paths):
img=Image.open(path)
img = img.convert('L')
img=img.resize((int(img.width/2), int(img.height/2)))
x=np.append(x,np.array(img).reshape(1,-1),axis=0)
distortions = [] #
for k in tqdm(range(1, 20)):
kmeans = KMeans(n_clusters=k, n_init=10, max_iter=100)
kmeans.fit(x)
distortions.append(kmeans.inertia_)
fig = plt.figure(figsize=(12, 8))
plt.xticks(range(1, 20))
plt.plot(range(1, 20), distortions)
plt.savefig("elbow.jpg ")
plt.close()

k_means = KMeans(n_clusters=4).fit(x)
y_pred = k_means.predict(x)
print(k_means.labels_)
print(pd.Series(k_means.labels_, name='cluster_number').value_counts(sort=False))
out=pd.DataFrame()
out["picture"]=paths
out["classnumber"]=y_pred
out["date"]=pd.to_datetime(out["picture"].str.split("\\",expand=True).iloc[:,1].str.split(".",expand=True).iloc[:,0])
out.to_csv("out.csv")
Ellbogenmethode Ellbogenmethode (Ermittlung der optimalen Anzahl von Clustern) Die optimale Anzahl von Clustern wurde nach der Ellbogenmethode berechnet. Es hat ungefähr 10 Minuten gedauert, um es mit 20 zu machen, also denke ich, dass ungefähr 10 genug sind. Das Ergebnis ist in der folgenden Abbildung dargestellt. Ich wusste nicht genau, wie viele gut sein würden, aber diesmal entschied ich mich, es mit 4 zu machen. Clusteranalyse Die Anzahl der Elemente pro Cluster betrug 139,61,68,98. Es war in gute Gefühle unterteilt, also kann ich es erwarten.
#Nach Klasse speichern
for i in range(4):
makedirs(str(i)+"_pictures", exist_ok=True)
for i in out.itertuples():
img=Image.open(i.picture)
img.save(str(i.classnumber)+"_"+i.picture)
for i in range(4):
out["month"]=out["date"].dt.month
sns.countplot("month",data=out[out["classnumber"]==i])
plt.title(i)
plt.savefig("Monatliche Verteilung"+str(i))
plt.close()
Speichern wir jede Klasse separat und sehen uns die monatliche Verteilung und die konkreten Bilder jeder Klasse an.
Cluster Nr. 0
 Es fühlt sich an, als gäbe es im Winter viele und im Sommer nur wenige. Ist es eine winterliche Druckverteilung? Es scheint seltsam, dass dies auch im Sommer zu sehen ist, obwohl die Anzahl gering ist.
Es fühlt sich an, als gäbe es im Winter viele und im Sommer nur wenige. Ist es eine winterliche Druckverteilung? Es scheint seltsam, dass dies auch im Sommer zu sehen ist, obwohl die Anzahl gering ist.
Die Bilder, die zu diesem Cluster gehören, sind beispielsweise wie folgt.
| 2020/1/13 | 2020/1/19 |
|---|---|
 |
 |
Dies war eine Wetterkarte mit einer typischen West-Hoch-Ost-Niederdruckverteilung und einem kalten Wind aus Nordwesten, der Wolken über dem japanischen Archipel verursachte.
Darüber hinaus sind die Zahlen zu diesem Cluster, die nicht im Winter sind, wie in der folgenden Abbildung dargestellt.
| 2020/6/26 | 2019/10/26 |
|---|---|
 |
 |
Die Atmosphäre ist, dass es Wolken über dem Kontinent und über Japan gibt und es keine Wolken über dem Pazifik gibt. Obwohl die Wolkentypen unterschiedlich sind, habe ich das Gefühl, dass die Atmosphäre des Wolkenstandorts sicherlich ähnlich ist.
Cluster Nr.1
 Sie nimmt im April und November zu. Ich konnte nicht herausfinden, was sie allein mit dieser Grafik gemeinsam hatten.
Sie nimmt im April und November zu. Ich konnte nicht herausfinden, was sie allein mit dieser Grafik gemeinsam hatten.
Die Bilder, die zu diesem Cluster gehören, sind beispielsweise wie folgt.
| 2019/11/2 | 2020/4/29 |
|---|---|
 |
 |
Es schien keine klare Druckverteilungsfunktion zu haben. Als Merkmal des Bildes war das Gebiet um Japan sonnig, und es gab viele Bilder mit diagonalen Wolken in südöstlicher Richtung Japans. Einige dieser Wolken haben sich je nach Jahreszeit am Rande des pazifischen Hochdrucks gebildet, aber ich habe das Gefühl, dass ähnliche Wolken zufällig gebildet werden. Wenn überhaupt, hatte dieser Cluster einen starken Eindruck wie der Rest anderer Cluster.
Cluster Nr.2
 Dies ist häufig während der Regenzeit der Fall. Ist es die Druckverteilung, wenn es eine Regenzeitfront gibt? Außerdem scheint im Februar, August und September niemand gesehen worden zu sein.
Dies ist häufig während der Regenzeit der Fall. Ist es die Druckverteilung, wenn es eine Regenzeitfront gibt? Außerdem scheint im Februar, August und September niemand gesehen worden zu sein.
| 2020/6/28 | 2020/7/4 |
|---|---|
 |
 |
Wie erwartet zeigten viele dieser Cluster die Regenzeitfront. Es ist eine Regenzeit, die nicht in den vier Kategorien Frühling, Sommer, Herbst und Winter vorkommt, aber ich denke, es hat sich gezeigt, dass ihre meteorologischen Eigenschaften klar sind.
Die Bilder anderer Jahreszeiten, die zu diesem Cluster gehören, waren wie folgt.
| 2019/10/20 | 2020/3/19 |
|---|---|
 |
 |
Wolken mit einer ähnlichen Form wie die Frontlinie breiteten sich über den japanischen Archipel aus, und es ist verständlich, dass sie in diesen Cluster eingeteilt wurden.
Cluster Nr.3
 Es zeigt einen überwältigenden Sommer. Es scheint die sommerliche Druckverteilung darzustellen, die über den pazifischen Hochdruck hinausragt.
Es zeigt einen überwältigenden Sommer. Es scheint die sommerliche Druckverteilung darzustellen, die über den pazifischen Hochdruck hinausragt.
Wenn man sich die Bilder ansieht, die tatsächlich in diesen Cluster eingeteilt wurden, war es ein Bild voller sommerlicher Gefühle wie folgt.
| 2019/7/29 | 2019/8/21 |
|---|---|
 |
 |
Darüber hinaus hatten viele Bilder anderer Jahreszeiten breitere Sonnentage.
| 2019/10/14 | 2019/11/1 |
|---|---|
 |
 |
Zusammenfassung
Aus den obigen Analyseergebnissen war es möglich, die allgemeine Tendenz der Druckverteilung durch Clusteranalyse zu klassifizieren und diejenigen zu interpretieren, die davon abweichen. Da das Satellitenbild den Druck jedoch nicht direkt darstellt, ist es nicht möglich, die Druckverteilung direkt zu klassifizieren, und die Cluster werden entsprechend der Wolkenverteilung unterteilt. Wenn also die Formen der Wolken ähnlich sind, ist dies falsch. Es wird klassifiziert. Um die Druckverteilung zu klassifizieren, gibt es Raum zu überlegen, wie nicht nur Wolken, sondern auch Druck erfasst werden können. Diesmal ausgeführter Code (Github)
Verweise
- [Wetternachrichten "Was ist die" Druckverteilung von Hochwesten und Tiefost ", die Sie häufig in Wettervorhersagen hören? ]](Https://weathernews.jp/s/topics/201610/140215/)
Recommended Posts