[PYTHON] Echtzeit-Personalschätzung (Lernen mit lokaler GPU)
zunaechst
Das letzte Mal habe ich einen Artikel mit dem Titel "Neues Modell bauen" geschrieben und überprüft, aber es stellte sich als katastrophales Ergebnis heraus, dass ich Nogizakas Matsun mit Yoda-chan verwechselt habe. Ich wusste also, dass das Modell nicht funktioniert, aber ich kann hier nicht aufgeben. Ich bin entschlossen, das Modell neu zu erstellen, und ich werde diesen Artikel schreiben. Es war schwierig, eine Lernumgebung mit GPU vorzubereiten.
Über die Umwelt
OS:windows10 GPU:GTX960 Yolov5
Über Umweltbau
Ich habe zunächst die Umgebung neu erstellt, um Yolo auszuführen, während die GPU ausgeführt wird. (1) Einführung von cuda Vor der Installation von PyTorch, das in (2) beschrieben ist, muss cuda installiert werden. Informationen zur Einführung von cuda Es gibt verschiedene Seiten, aber ich denke, es kann getan werden, weil es nicht so schwierig ist. Ich habe wahrscheinlich cuda 10.1 eingeführt. Die URL wird unten angezeigt. https://developer.nvidia.com/cuda-10.1-download-archive-base?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal (2) Einführung von PyTorch Führen Sie PyTorch für cuda 10.1 ein.
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
(3) Einführung von Yolov5
Bitte überprüfen Sie dies wie oben beschrieben.
https://qiita.com/asmg07/items/e3be94a3e0f0195c383b
(4) Testlernen
Ich schreibe 50 Mal Epochen, während ich diesen Artikel schreibe, aber da die CPU nicht verwendet wird, ist der Artikel sehr schön.
Dieser Teil zeigt nur die derzeit verwendeten Befehle und wird nach dem Lernen überprüft. </ S>
python train.py --img 640 --epochs 50 --data data.yaml --cfg ./models/yolov5m.yaml --batch-size 2
Ich habe das Schreiben des Artikels beendet.
(5) Überprüfung
 Hier ist das resultierende Bild. Nun, ich bin mir immer noch nicht sicher.
Es endete unerwartet früh, deshalb möchte ich Epochen 100 Mal ausprobieren.
Ergebnisse von 100 mal
Hier ist das resultierende Bild. Nun, ich bin mir immer noch nicht sicher.
Es endete unerwartet früh, deshalb möchte ich Epochen 100 Mal ausprobieren.
Ergebnisse von 100 mal
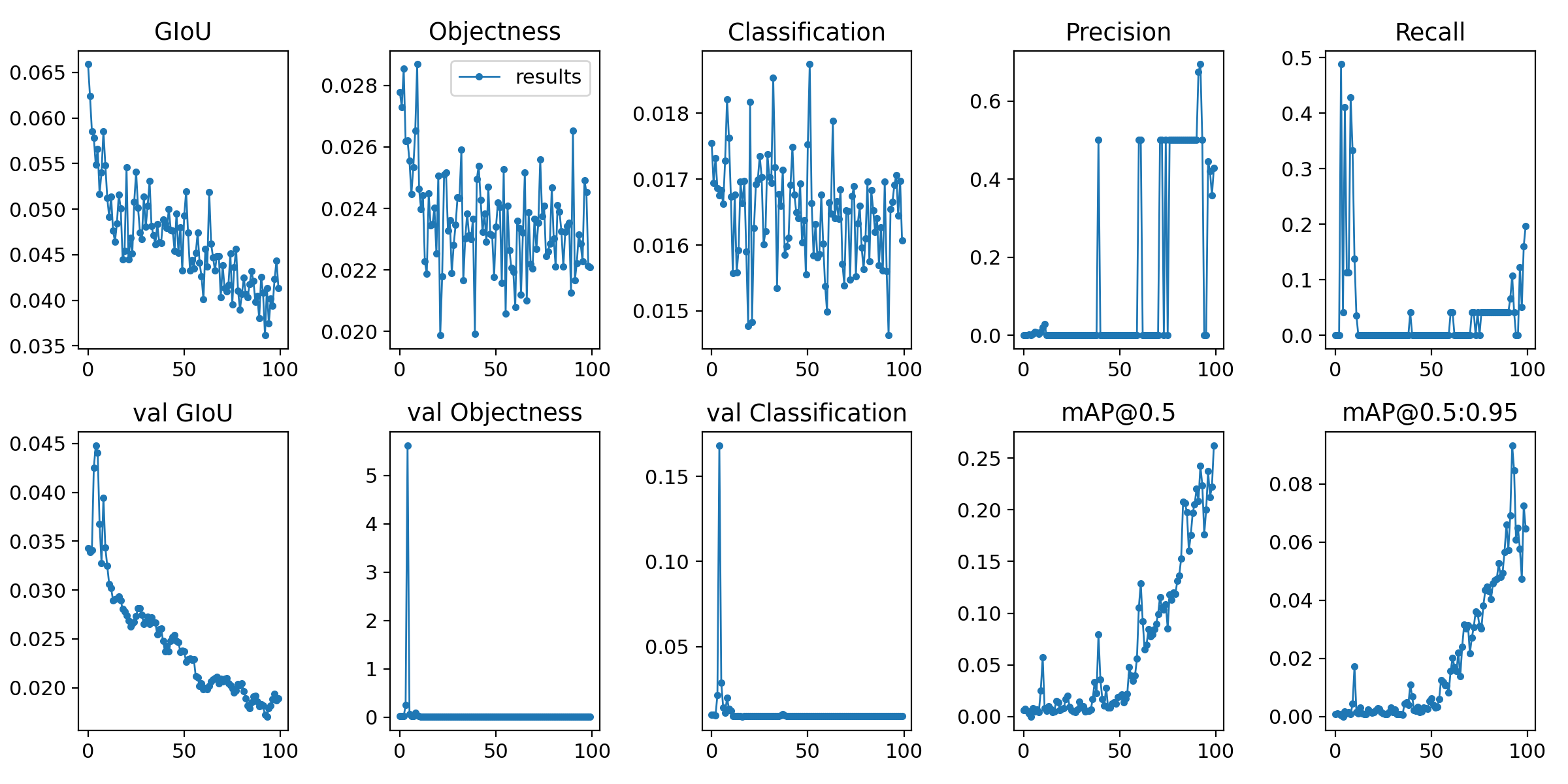
(6) Erläuterung der Lernbefehle
Ich bin mir noch nicht sicher, aber ich werde es erklären.
--epochs 50 ➡ mal
--batch-size 2
Dies ist wichtig - warum Chargengröße 2 dies tut
Ich benutze GTX960 und habe 2 GB Speicher.
Wenn Sie eine größere Zahl verwenden, ist der Speicher größer und Sie erhalten eine Fehlermeldung.
Also mache ich es damit. Ich frage mich, ob es dedizierten Speicher und gemeinsam genutzten Speicher im Speicher gibt und nur der dedizierte Speicher verwendet werden kann.
Bitte lassen Sie mich wissen, ob es auch eine Möglichkeit gibt, Shared Memory zu verwenden.
Schließlich
Ich habe die Umgebung vorerst verändert und wieder einen neuen Artikel geschrieben.
Wenn es eine Entwicklung gibt, werde ich sie erneut schreiben.
PS.
Ich möchte einen Kommentar.
・ Gemeinsamer Speicher und dedizierter Speicher.
・ So vermeiden Sie, dass Sie auf zwei Kategorien schließen, wenn Sie ein drittes Bild treffen, das in zwei Kategorien überhaupt nicht trainiert wurde.
Ich frage mich, ob es schwierig ist, ein individuelles Gesicht mit einem Bild zu haben, das nicht trainiert wurde
Als ich in der Vergangenheit etwas Ähnliches gemacht habe, habe ich eine dritte Variante von Gesichtsdaten eingegeben, die nichts damit zu tun hatten, und sie in drei Kategorien trainiert, aber das möchte ich nicht.
Ich würde mich freuen, wenn Sie mir etwas über diesen Bereich erzählen könnten.
Nachtrag
⓵ Es scheint, dass Shared Memory nicht verwendet werden kann. ⓶ Ich habe mit Epochen 1000 trainiert.
python train.py --epochs 1000 --data data.yaml --cfg ./models/yolov5s.yaml --batch-size 1
Über 80 Bilddaten in 2 Kategorien
Daten nach dem Training ausgeben
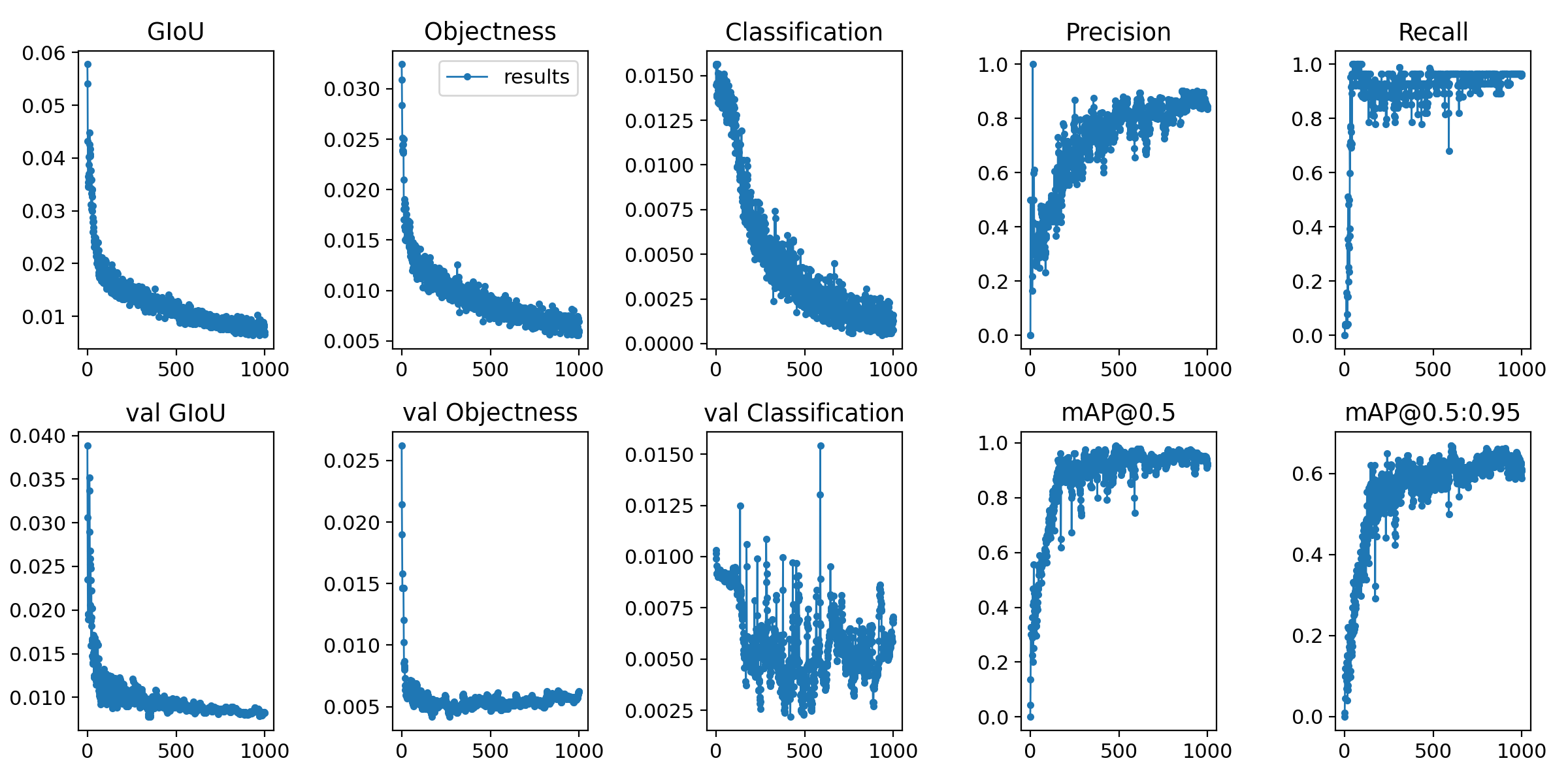 Ich fragte mich, ob das ein ziemlich gutes Gefühl war.
・ Ergebnisse der tatsächlichen Tests mit ca. 100 Datenblättern
Außerhalb der Kategorie (nicht in der Kategorie enthalten)
Ich fragte mich, ob das ein ziemlich gutes Gefühl war.
・ Ergebnisse der tatsächlichen Tests mit ca. 100 Datenblättern
Außerhalb der Kategorie (nicht in der Kategorie enthalten)


 In der Kategorie
In der Kategorie

 Die in der Kategorie enthaltene Schätzung von Nogisaka-chan funktioniert gut, aber Nogisaka-chan außerhalb der Kategorie (nicht in der Kategorie enthalten)
Schätzung funktioniert nicht.
Problem
-Was tun gegen das Problem der Erkennung von Bildern außerhalb der Kategorie (nicht in der Kategorie enthalten).
Erstens ist es eine Theorie, aber schließlich kann es eines der Probleme sein, dass zu wenig Trainingsdaten vorhanden sind.
Die in der Kategorie enthaltene Schätzung von Nogisaka-chan funktioniert gut, aber Nogisaka-chan außerhalb der Kategorie (nicht in der Kategorie enthalten)
Schätzung funktioniert nicht.
Problem
-Was tun gegen das Problem der Erkennung von Bildern außerhalb der Kategorie (nicht in der Kategorie enthalten).
Erstens ist es eine Theorie, aber schließlich kann es eines der Probleme sein, dass zu wenig Trainingsdaten vorhanden sind.
- Bitte lassen Sie mich wissen, ob es eine Lösung gibt.
Probleme bei der Vorbereitung der Umgebung (Frage zu Github)
https://github.com/ultralytics/yolov5/issues/1094 https://github.com/ultralytics/yolov5/issues/1093
Recommended Posts