[PYTHON] Versuch und Irrtum, um die Erzeugung von Wärmekarten zu beschleunigen
Ich habe ein Programm erstellt, um die Heatmap (RGB) aus einem Wert von 0 bis 255 zu berechnen. Die Quelle, die ich am Anfang geschrieben habe (GPU + Cupy), war zu langsam, daher werde ich das Ergebnis von Versuch und Irrtum hinterlassen.
** * cv2.applyColorMap (grayscale_image, cv2.COLORMAP_JET) hat alles gelöst, aber ich habe es selbst gemacht (schade). ** ** **
Das Folgende ist die Verarbeitung für die Bildgröße 320x180.
Der Code ist nur der Hauptteil.
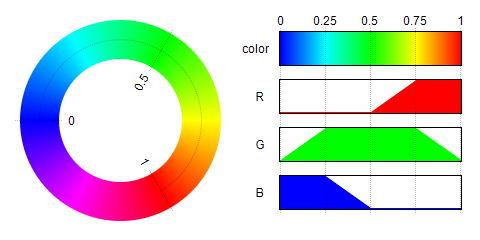
Darüber hinaus ist die Wärmekarte eine vereinfachte Version (Dreiecksfunktion nicht verwendet) zum Ermitteln von ungefähren Werten.
(Lineares Diagramm von Wertgröße in thermografieartige Farbe umwandeln).
GPU+Cupy(for) Dies ist der Code, den ich ursprünglich geschrieben habe. Es ist ein Gruppencode zu verlieren, der verarbeitet wird, indem man ihn ehrlich umdreht.
def conv_v_to_heat(v):
image = cuda.cupy.zeros((v.shape[0], array.v[1], 4))
for i, w in enumerate(image):
for j, h in enumerate(w):
image[i,j,0] = get_heat_r(array[i][j])
image[i,j,1] = get_heat_g(array[i][j])
image[i,j,2] = get_heat_b(array[i][j])
image[i,j,3] = array[i][j] #Alpha ist geeignet
def get_heat_r(v):
if v <= 127:
return 0
elif v <= 190:
return (v-127)*4
else:
return 255
sec: 20.43495798110962
CPU+Numpy(for) Ist es nicht besser, die GPU nicht mehr zu verwenden als für? Ich habe es in CPU geändert (Quelle weggelassen).
sec: 0.6369609832763672
Die CPU war viel schneller.
CPU+Numba+Numpy(for) Ich habe Numba reingelegt.
@jit
def conv_v_to_heat(v):
@jit
def get_heat_r(v):
sec: 0.20061397552490234
Es ist noch schneller.
CPU+Numba+Numpy(filter) Erstens ist es ein Verlierer, wenn es für Numpy verwendet wird Ich habe versucht, durch Filtern damit umzugehen.
def conv_v_to_heat(v):
image = np.zeros((v.shape[0], v.shape[1], 4))
image[:, :, 0] = get_r(array)
image[:, :, 1] = get_g(array)
image[:, :, 2] = get_b(array)
image[:, :, 3] = v
def get_heat_r(v):
out = np.zeros((v.shape))
out[...] = 255
out[(v<=190)] = (v[(v<=190)]-127)*4
out[(v<=127)] = 0
return out
sec: 0.0013210773468017578
Es ist überwältigend schneller.
CPU+Numpy(filter) Als Test werde ich Numba entfernen.
sec: 0.001230478286743164
Das geht schneller. Es handelt sich vielmehr um eine Fehlerstufe.
GPU+Cupy(filter) Was ist dann mit der GPU?
sec: 0.008527278900146484
Ich bin spät.
Zusammenfassung
| Implementierung | time(sec) |
|---|---|
| GPU+Cupy(for) | 20.43495798110962 |
| CPU+Numpy(for) | 0.63696098327637 |
| CPU+Numba+Numpy(for) | 0.20061397552490 |
| CPU+Numba+Numpy(filter) | 0.00132107734680 |
| CPU+Numpy(filter) | 0.00123047828674 |
| GPU+Cupy(filter) | 0.00852727890015 |
CPU + Numpy (Filter) war das Beste. Ich denke, es gibt eine schnellere Implementierung, aber persönlich ist es eine zufriedenstellende Geschwindigkeit. Wenn Sie für verwenden, verlieren Sie schließlich.
Recommended Posts