[PYTHON] Traitement et jugement de la collecte du plan d'analyse des données (partie 2)
Enfin [précédent](http: ///qiita.com/ynakayama/items/b3e3138231f910a0de77), cette fois est la deuxième partie.
Maintenant, revenons au point de départ. Pourquoi collecter et analyser des données? C'est parce que nous voulons maximiser les profits. Afin de réaliser un profit, vous collectez les matériaux (données) qui sont à la base de votre jugement, organisez les contenus, regardez-les et connectez-les à vos actions pour réaliser un profit.
En d'autres termes, il existe un motif clair (objectif) qui conduit au profit dans l'analyse des données, et la valeur n'est créée que lorsque le résultat de l'analyse est lié à l'action.
Jeux et investissement
Parlons d'investissement ici.
Il n'existe pas de méthode de placement adaptée à tout le monde, mais il existe certaines conditions préalables pour obtenir un avantage de marché sur les actions, par exemple.
- L'investissement est un jeu de probabilités
- Le marché est généralement efficace, mais il y a une légère distorsion
- Le capitalisme se propage de lui-même, de sorte que le marché se développera à long terme et les cours des actions convergeront vers la croissance économique.
Je pense que cela a quelque chose à voir avec les jeux sociaux classiques basés sur des objets. Autrement dit, 1. C'est un jeu de probabilité, 2. Il y a distorsion (biais), et 3. Il y a inflation. Que vous puissiez ou non obtenir l'article souhaité en facturant est une probabilité. En d'autres termes, même si le même montant de «facturation» est effectué, il y a un biais dans la force du lien résultant avec les «articles» obtenus. De plus, tôt ou tard, tous les joueurs deviendront plus forts, provoquant de l'inflation, et si de nouveaux objets forts sont introduits, la valeur des objets passés diminuera relativement. C'est vrai. Cependant, il existe des différences selon le système et la politique de gestion.
Dans tous les cas, il existe des stratégies pour augmenter la probabilité sans compter sur des jackpots accidentels. Par exemple, prenez une stratégie pour augmenter le nombre d'essais. Même s'il y a quelques hits ou quelques hits, si vous continuez pendant longtemps, cela convergera vers la valeur moyenne. Ceci est similaire à une stratégie de détention à long terme en termes de stock. En détenant une action dans le stock pendant une longue période, la valorisation augmentera en conséquence, même s'il y a une hausse ou une baisse temporaire. [Warren Buffett](http://d.hatena.ne.jp/keyword/%A5%A6%A5%A9%A1%BC%A5%EC%A5%F3%A1%A6%A5%D0%A5 Je pense que% D5% A5% A7% A5% C3% A5% C8) est célèbre. Cependant, c'est une histoire de "Tenons un bon stock pendant longtemps", et je pense que c'est une prémisse majeure que l'entreprise "se développera sur le long terme" en examinant attentivement la marque. Étant donné que le contrôle est important, par exemple, il n'est pas judicieux de détenir des actions à long terme dans un secteur en évolution rapide et en baisse. Même si ce n'est pas le cas, je pense que le nombre d'entreprises qui peuvent être assurées de se développer à long terme dans cette ère incertaine sera assez limité.
Économisez de l'argent pour maximiser le nombre d'essais
À propos, même si vous adoptez une stratégie pour augmenter le nombre d'essais, cela coûte de l'argent chaque fois que vous tournez le gacha, et il y a place pour l'ingéniosité dans la façon de charger efficacement. Il est facile de comprendre comment maintenir l'investissement au minimum nécessaire en supprimant l'apport de diverses ressources dans la mesure où la frontière est atteinte dans le classement. Au lieu d'investir aveuglément, il est important d'identifier les frontières.
Rappelons le graphique précédent. Il s'agit de l'augmentation des scores pour les événements de chaque mois jusqu'au mois dernier. Le but est de comprendre les tendances à partir de cela et de prédire le score pour l'événement de février.
Saisissez la tendance
En regardant les données visualisées, nous pouvons voir qu'il y a quelques points.
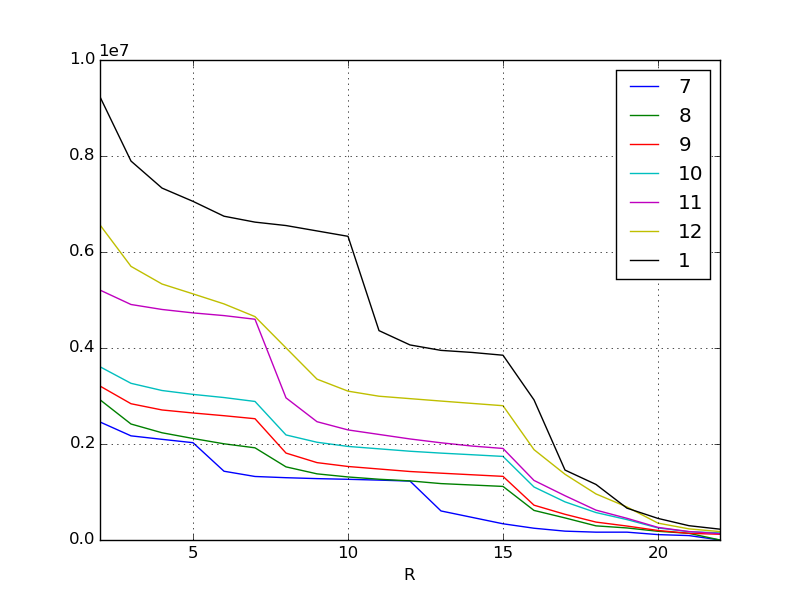
Par exemple, en novembre, il y a une falaise pliée verticalement au premier rang de récompense. De plus, en janvier, il y a une falaise à la récompense inférieure. Certaines hypothèses peuvent être faites en ajoutant ceci et le contenu de l'événement. Bien sûr, cette hypothèse doit être considérée par les humains. Cependant, s'il s'agit d'un événement mondial axé sur le consommateur, vous pouvez utiliser les informations sur les médias sociaux et les tableaux d'affichage pour recueillir les opinions des gens.
Par exemple, en novembre
- Ajout de nouveaux personnages attrayants (les meilleures récompenses sont populaires pour vous assurer de les obtenir)
Ou en janvier
- Immédiatement avant cela, un nouveau système a été introduit pour améliorer l'efficacité des scores.
- Depuis la diffusion du CM en hiver, de nombreux nouveaux groupes de facturation sont entrés sur le marché.
Etc.
Dans tous les cas, on peut lire qu'il y a une grande différence de score aux pauses où le contenu de la récompense change, mais si un changement aussi remarquable apparaît en raison de facteurs qualitatifs, l'équation de régression ne peut pas être bien dérivée.
Donc, cette fois, après le début de l'événement, nous agrégerons les scores quotidiens du mois en cours (février) et examinerons comment ils ont été comparés aux trois derniers mois.
L'analyse exploratoire des données
L'analyse exploratoire des données consiste à examiner les données sous différents angles dans le but «d'acquérir des objectifs et des hypothèses appropriés».
À l'origine, j'ai souligné à plusieurs reprises que l'analyse des données nécessite un objectif et une hypothèse clairs, mais en premier lieu, dans la situation où la cible d'analyse n'a pas les connaissances préalables ou l'état réel de la cible n'est pas bien compris, en premier lieu Il est nécessaire de jeter un œil aux données afin d'obtenir le but et l'hypothèse de. Il s'agit d'une approche appelée analyse exploratoire des données dans le monde de la statistique.
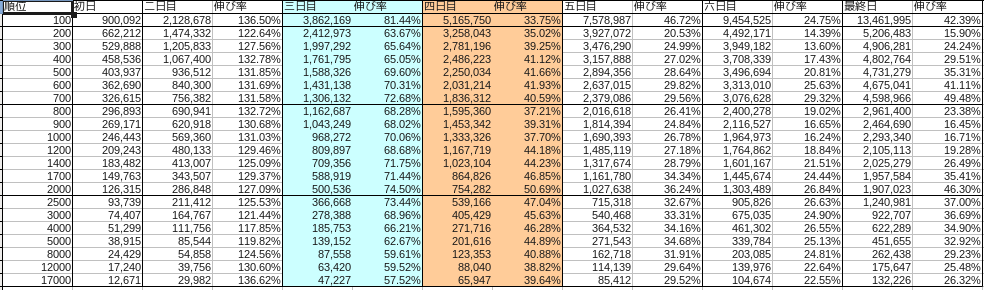
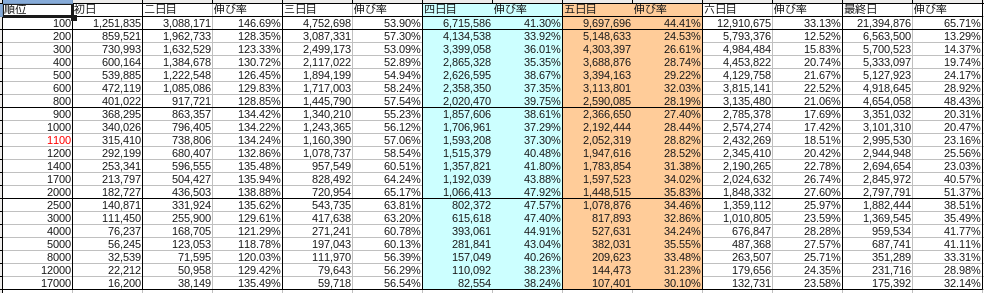
La répartition de chaque mois était la suivante.
novembre
décembre
janvier
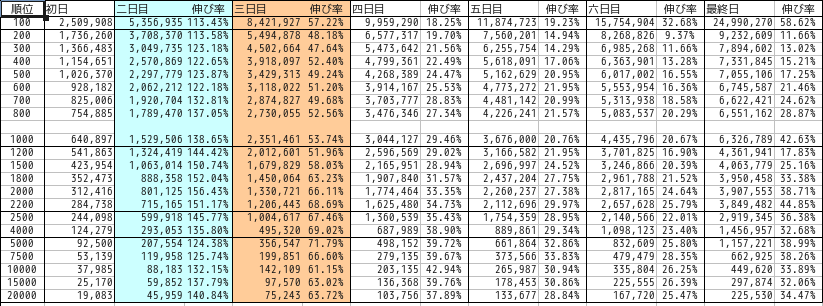
Le bleu représente samedi et le rouge représente dimanche.
Tout d'abord, limitons l'objectif à la récompense la plus élevée en tant qu'objectif. Nous utiliserons la transition du score à la frontière, qui est la principale récompense de chaque mois, comme un ensemble de données. IPython est toujours utile pour faire progresser l'analyse exploratoire des données.
Ici, on suppose que février s'est écoulé jusqu'au milieu de l'événement (jour 4).
#Découpez les données sur les meilleures récompenses pour chaque mois
df201411 = pd.read_csv("201411.csv", index_col=0)
df201412 = pd.read_csv("201412.csv", index_col=0)
df201501 = pd.read_csv("201501.csv", index_col=0)
df201502 = pd.read_csv("201502.csv", index_col=0)
#Extrayez les principales lignes de récompense dans une série
s201411 = df201411.ix[700, :]
s201412 = df201412.ix[800, :]
s201501 = df201501.ix[1000, :]
s201502 = df201502.ix[1000, :]
#Index au nombre pour plus de simplicité
s201411.index = np.arange(1, len(s201411) + 1)
s201412.index = np.arange(1, len(s201412) + 1)
s201501.index = np.arange(1, len(s201501) + 1)
s201502.index = np.arange(1, len(s201502) + 1)
#Concaténer les séries de chaque mois dans une trame de données
df = pd.concat([s201411, s201412, s201501, s201502], axis=1)
#Faire des numéros de colonnes
df.columns = [11, 12, 1, 2]
#Visualiser
df.plot()
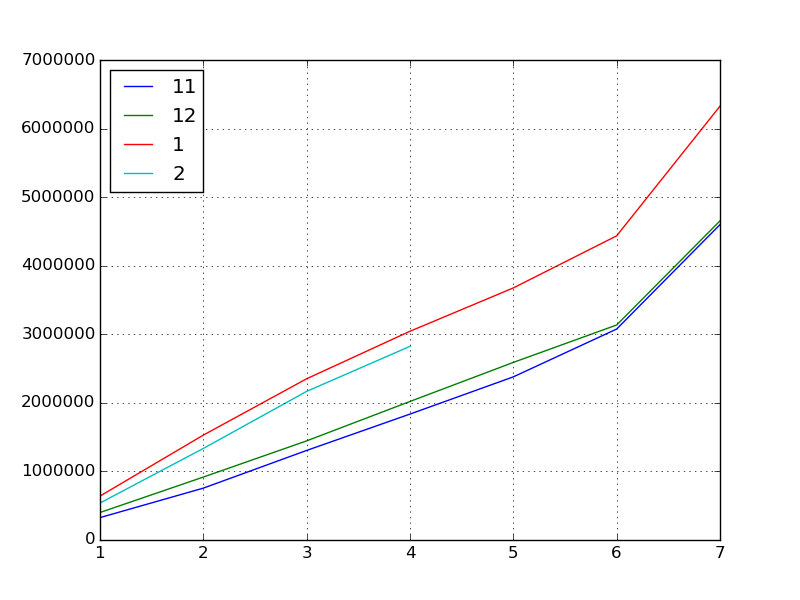
Ensuite, trouvons les statistiques de base.
#Statistiques de base
df.describe()
#=>
# 11 12 1 2
# count 7.000000 7.000000 7.000000 4.000000
# mean 2040017.285714 2166375.142857 3143510.857143 1716607.750000
# std 1466361.613186 1444726.064645 1897020.173703 993678.007807
# min 326615.000000 401022.000000 640897.000000 539337.000000
# 25% 1031257.000000 1181755.500000 1940483.500000 1136160.000000
# 50% 1836312.000000 2020470.000000 3044127.000000 1751315.500000
# 75% 2727857.000000 2862782.500000 4055898.000000 2331763.250000
# max 4598966.000000 4654058.000000 6326789.000000 2824463.000000
#Coefficient de corrélation
df.corr()
#=>
# 11 12 1 2
# 11 1.000000 0.999157 0.996224 0.996431
# 12 0.999157 1.000000 0.998266 0.997345
# 1 0.996224 0.998266 1.000000 0.999704
# 2 0.996431 0.997345 0.999704 1.000000
#Co-distribué
df.cov()
#=>
# 11 12 1 2
# 11 2.150216e+12 2.116705e+12 2.771215e+12 6.500842e+11
# 12 2.116705e+12 2.087233e+12 2.735923e+12 6.893663e+11
# 1 2.771215e+12 2.735923e+12 3.598686e+12 1.031584e+12
# 2 6.500842e+11 6.893663e+11 1.031584e+12 9.873960e+11
Que pouvons-nous apprendre d'ici?
- Le score «inflation» s'accélère régulièrement en novembre, décembre et janvier.
- Surtout en janvier (qui peut être lu à partir du coefficient de corrélation)
- Il gonfle depuis un mois, alors peut-être sera-t-il également gonflé en février.
Cependant, quatre jours après le début de l'événement en février, lorsque j'ai ouvert le couvercle ... le score a chuté.
C'est quelque chose qui n'a jamais été fait, y compris les données qui ont été publiées la dernière fois. Bien qu'elle augmente (inflation) depuis longtemps, elle a baissé, et comme il s'agit du premier phénomène, elle est finalement devenue difficile à prévoir.
Encore une fois, nous poserons quelques hypothèses.
- Il y a eu de nombreux événements dits de collecte tels que des gachas spéciaux ce mois-ci
- Winter CM Les nouveaux participants ont participé à l'événement en janvier sans avoir assez de force et ont mené une bataille déraisonnable et se sont épuisés
- Ventes de l'industrie en baisse chaque février
- Dix mois se sont écoulés depuis le lancement du service, et de nombreuses personnes ont 10 objets de récompense, et la concurrence a ralenti car ils ont rempli 10 decks.
- Tout le monde a commencé à épargner car le mois dernier était trop gonflé
Il existe de nombreuses possibilités.
Cependant, comme le coefficient de corrélation est élevé pour chaque croissance de chaque mois, on peut juger qu'il semble bon de prédire le score à la fin de l'événement en se référant à la croissance quotidienne des 3 derniers mois.
Capturez l'augmentation et la diminution du score
Par conséquent, nous pouvons capturer la croissance de ce score en tant que ** variation en pourcentage **.
Taux de hausse et de baisse est un terme d'investissement et est un indicateur des fluctuations de prix. Comparez les deux points dans le temps pour voir quel pourcentage la valeur du fonds est à la hausse ou à la baisse. Ici, calculons le taux d'augmentation / diminution en considérant l'augmentation du score comme un schéma de changement du prix du fonds.
#Taux de croissance de la veille
df.pct_change()
#=>
# 11 12 1 2
# 1 NaN NaN NaN NaN
# 2 1.315821 1.288455 1.386508 1.475449
# 3 0.726815 0.575413 0.537399 0.623495
# 4 0.405916 0.397485 0.294568 0.303079
# 5 0.295578 0.281922 0.207571 NaN
# 6 0.293197 0.210570 0.206691 NaN
# 7 0.494807 0.484321 0.426303 NaN
#Une fois transposé, il devient le taux de croissance du mois précédent
df.T.pct_change()
#=>
# 1 2 3 4 5 6 7
# 11 NaN NaN NaN NaN NaN NaN NaN
# 12 0.227813 0.213304 0.106925 0.100287 0.088689 0.019129 0.011979
# 1 0.598159 0.666635 0.626419 0.506643 0.419258 0.414710 0.359413
# 2 -0.158465 -0.127103 -0.078220 -0.072160 NaN NaN NaN
Le taux de croissance de la veille a tendance à être le même chaque mois. On voit que le taux de croissance varie légèrement selon que ce soit un jour férié ou un jour de semaine, mais le taux de croissance est le plus élevé le deuxième jour, puis ralentit, et augmente de 40 à 50% lors de la poussée du dernier jour.
Ensuite, en regardant la croissance du mois précédent le même jour, février est devenu négatif.
pct_change = df.T.pct_change() #Taux de croissance du mois précédent
def estimated_from_reference(day):
return df.ix[7, 1] * (1 + df.T.pct_change().ix[2, day])
estimated = [estimated_from_reference(x) for x in range(1, 7)]
print(estimated)
#=>
[5324211.8451061565, 5522634.3150592418, 5831908.3162212763, 5870248.3304103278, nan, nan]
#Score limite final attendu basé sur le jour 1, le jour 2, le jour 3 et le jour 4
Je l'ai comme ça.
Ou vous pouvez demander les scores pour les 5e, 6e et derniers jours à venir.
def estimated_from_perchange(criteria, day):
return df.ix[criteria, 2] * (1 + df.pct_change().ix[day, 1])
#Calculez le score du 5 février à partir du taux d'augmentation / diminution du 4 au 5 janvier
df.ix[5, 2] = estimated_from_perchange(4, 5)
#=> 3410740.086731
#Aussi le 6ème jour
df.ix[6, 2] = estimated_from_perchange(5, 6)
#=> 4115709.258368
#Dernier jour
df.ix[7, 2] = estimated_from_perchange(6, 7)
#=> 5870248.330410
Cela remplit les valeurs manquantes dans le bloc de données. À partir de là, il était possible de prédire que 5,87 millions de points seraient la limite des meilleures récompenses à partir du 4ème jour.
Utiliser comme base de jugement
À propos, les données de réponse correcte étaient de 3487426 points le 5ème jour (102,2% de la valeur prédite le 4ème jour), 4094411 points (99,5%) le 6ème jour et 5728959 points (97,5%) le dernier jour, donc 5,87 millions de points devraient être abordables. Le résultat est que vous avez remporté la meilleure récompense.
| Journées | Prévoir | résultat | différence |
|---|---|---|---|
| Jour 5 | 3410740 | 3487426 | 102.2% |
| Jour 6 | 4115709 | 4094411 | 99.5% |
| Dernier jour | 5870248 | 5728959 | 97.5% |
Les résultats de l'analyse exploratoire des données peuvent être programmés et enregistrés dans Fonctionnalités puissantes d'IPython, ils sont donc calculés quotidiennement tout en suivant la progression de l'événement. Il a été démontré que les frontières peuvent être prédites avec une précision extrêmement élevée.
à la fin
Dans le monde de l'investissement [Rise and fall ratio](http://ja.wikipedia.org/wiki/%E9%A8%B0%E8%90%BD%E3%83%AC%E3%82%B7%E3%82 Il existe un indice appelé% AA). Il s'agit d'un indicateur à court terme du ratio du taux d'augmentation / diminution par rapport à l'ensemble des stocks. Vous pouvez lire à partir de cet indicateur technique si le stock est suracheté.
Jetons un coup d'œil à la moyenne Nikkei du 4 mars 2015.
Tableau de comparaison des taux de montée et de descente Nikkei http://nikkei225jp.com/data/touraku.html
Ce jour-là, les ventes ont précédé et la moyenne du Nikkei a chuté de 200 yens le matin. En fait, si vous regardez le ratio des hauts et des bas juste avant cela, vous pouvez voir un nombre très élevé de 130 à 140. Ceci, en substance, indique que le marché haussier est suracheté et est un signe que la moyenne du Nikkei chutera après cela. Après la baisse réelle de 200 yens, la valeur du ratio est revenue à la plage normale, et des rachats ont eu lieu et ont rebondi.
De cette manière, on peut dire que des méthodes communes peuvent être appliquées aux parties de base de l'analyse numérique d'un petit monde comme un jeu et de l'analyse d'un grand monde de l'économie financière. Bien sûr, il peut y avoir des circonstances imprévues dues à des cataclysmes soudains, mais l'attitude d'essayer d'analyser les choses scientifiquement au quotidien est très importante.
Recommended Posts