[PYTHON] Jugement de la polarité émotionnelle des phrases à l'aide du classificateur de texte fastText
introduction
J'ai créé un script qui détermine automatiquement la polarité émotionnelle (positive, négative) de toute phrase, je voudrais donc le résumer.
Dans le domaine du jugement de la polarité émotionnelle à partir de phrases (documents), il est également appelé analyse des sentiments ou analyse de réputation. Dans le passé, la méthode orthodoxe consistait à enregistrer des valeurs de polarité (valeurs positives et négatives) pour chaque mot dans le dictionnaire de polarité des mots et à les utiliser pour déterminer la polarité. Cependant, avec cette méthode, il y a un problème en ce qu'il n'est pas possible de calculer quand un mot qui n'est pas dans le dictionnaire de polarité apparaît, et est-il possible de déterminer de manière unique la polarité du mot en premier lieu? Il ya un problème. (Par exemple, même un mot "bon marché" est bon marché et bon marché! Quand vous dites bon marché est positif, mais quand vous dites que vous êtes bon marché, vous avez une impression négative.)
Par conséquent, dans cet article, nous présenterons un script qui calcule automatiquement la polarité émotionnelle d'une phrase à l'aide d'un classificateur de texte et examinons les données d'un site EC. En apprenant des données d'examen, ** le fait que vous pouvez éviter de créer un dictionnaire de polarité et le fait que vous pouvez juger de la polarité émotionnelle en tenant compte des informations syntaxiques (la valeur de polarité du mot peut être modifiée de manière flexible) ** Peut-être que ça a bon goût! Je l'ai fait avec l'attente.
fastText fastText [^ 1] est un apprentissage automatique qui prend en charge la vectorisation de mots et la classification de texte développés par facebook.
La structure elle-même est la structure d'un réseau neuronal à trois couches, comme le montre la figure ci-dessous, et a une structure très similaire au modèle CBoW proposé par Mikolov et al.
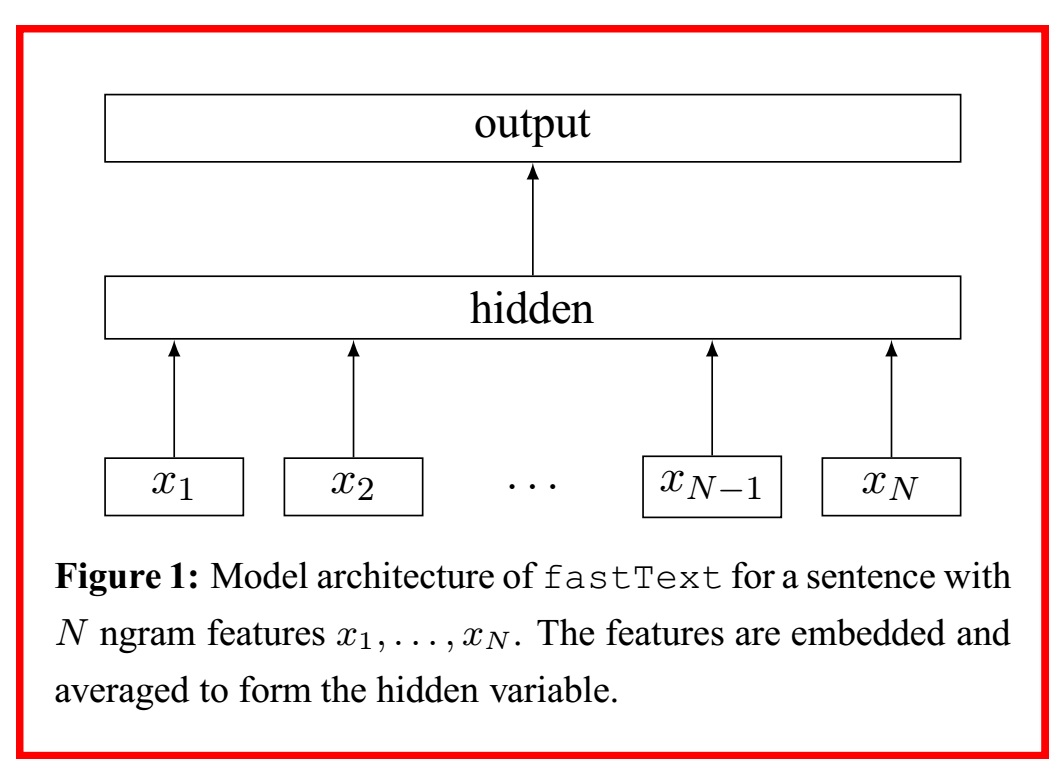
Dans la couche d'entrée, le vecteur one-hot des mots contenus dans le $ i $ th document est donné, et dans la couche de sortie, la distribution de probabilité que chaque document appartienne à chaque classe par softmax $ {\ bf p} = (p_1, p_2, .. ., p_n) Obtenez $. La méthode de classification exclusive (produisant une classe quelconque) génère la classe avec la valeur de probabilité la plus élevée de $ {\ bf p} $.
Données d'entraînement
Cette fois, nous avons créé un modèle de jugement de polarité des phrases en utilisant les données de revue des sites EC (Amazon et Rakuten). Parmi les avis sur les produits, préparez le nombre d'étoiles comme étiquette de réponse correcte et le texte d'avis comme données d'apprentissage. Si vous voulez que fastText s'entraîne, vous pouvez créer une liste comme celle ci-dessous. L'étiquette de réponse correcte est \ ___ étiquette \ ___ **, et le contexte d'apprentissage est une version divisée du document décrit sous l'étiquette.
train.lst
__label__1,Je n'étais pas intéressé par la lecture, alors jetez un œil C'est en noir et blanc et les illustrations ne sont pas mignonnes, alors je l'ai ouvert une fois ... Je ne peux pas le lire à haute voix.
fait .
__label__1,Il semble qu'il ait été épuisé 3 minutes après le départ. Je n'ai pas pu l'acheter.
Apprendre FastText
L'apprentissage de fastText est très simple. Lorsque les données d'entraînement (train.lst) sont input_file et que la destination d'enregistrement du modèle entraîné est sortie, vous pouvez vous entraîner avec uniquement le code suivant.
learning.py
argvs = sys.argv
input_file = argvs[1]
output = argvs[2]
classifier = ft.supervised(input_file, output)
Jugement de la polarité émotionnelle des phrases
Trouvez la polarité émotionnelle de la phrase donnée en entrée selon la formule suivante.
- $ e_i $: valeur d'évaluation pour $ i $ ($ e = \ {e_1 = 1, e_2 = 2, ..., e_5 = 5 \} $)
- $ p_i $: Probabilité que l'instruction d'entrée soit jugée comme évaluation $ e_i $
Dans la formule ci-dessus, $ p_i $ indique la valeur de la couche de sortie de fastText, et $ e_i $ indique le nombre d'étoiles. La valeur de polarité émotionnelle $ score $ d'une phrase est jugée positive à l'approche de 5 et négative à l'approche de 1. ** Si le texte que vous entrez est proche de la nature d'une critique étoilée, $ score $ sera plus élevé. ** **
estimation.py
# -*- coding: utf-8 -*-
import sys
import commands as cmd
import fasttext as ft
def text2bow(obj, mod):
# input:Mod pour les fichiers="file", input:Mod pour cordes="str"
if mod == "file":
morp = cmd.getstatusoutput("cat " + obj + " | mecab -Owakati")
elif mod == "str":
morp = cmd.getstatusoutput("echo " + obj.encode('utf-8') + " | mecab -Owakati")
else:
print "error!!"
sys.exit(0)
words = morp[1].decode('utf-8')
words = words.replace('\n','')
return words
def Scoring(prob):
score = 0.0
for e in prob.keys():
score += e*prob[e]
return score
def SentimentEstimation(input, clf):
prob = {}
bow = text2bow(input, mod="str")
estimate = clf.predict_proba(texts=[bow], k=5)[0]
for e in estimate:
index = int(e[0][9:-1])
prob[index] = e[1]
score = Scoring(prob)
return score
def output(score):
print "Evaluation Score = " + str(score)
if score < 1.8:
print "Result: negative--"
elif score >= 1.8 and score < 2.6:
print "Result: negative-"
elif score >= 2.6 and score < 3.4:
print "Result: neutral"
elif score >= 3.4 and score < 4.2:
print "Result: positive+"
elif score >= 4.2:
print "Result: positive++"
else:
print "error"
sys.exit(0)
def main(model):
print "This program is able to estimate to sentiment in sentence."
print "Estimation Level:"
print " negative-- < negative- < neutral < positive+ < positive++"
print " bad <----------------------------------------> good"
print "Input:"
while True:
input = raw_input().decode('utf-8')
if input == "exit":
print "bye!!"
sys.exit(0)
score = SentimentEstimation(input, model)
output(score)
if __name__ == "__main__":
argvs = sys.argv
_usage = """--
Usage:
python estimation.py [model]
Args:
[model]: The argument is a model for sentiment estimation that is trained by fastText.
""".rstrip()
if len(argvs) < 2:
print _usage
sys.exit(0)
model = ft.load_model(argvs[1])
main(model)
Méthode d'exécution
Exécutez comme suit à partir de la ligne de commande.
estimatin.py
$ python estimation.py [model]
- [model]: modèle fastText appris (fichier **. Bin)
Résultat d'exécution
Voici le résultat de l'exécution et du jugement de la polarité émotionnelle de la phrase. Au fait, une fois exécuté, il devient interactif, alors entrez "exit" lorsque vous voulez quitter.
This program is able to estimate to sentiment in sentence. Estimation Level: negative-- < negative- < neutral < positive+ < positive++ bad <----------------------------------------> good Input: Le magasin de ramen où je suis allé hier était vraiment bon! Evaluation Score = 4.41015725 Result: positive++ Le magasin de ramen où je suis allé hier était un peu sale mais c'était très délicieux! Evaluation Score = 4.27148227 Result: positive++ Le magasin de ramen où je suis allé hier était un magasin à la mode, mais le goût n'était pas bon Evaluation Score = 2.0507823 Result: negative- Le magasin de ramen où je suis allé hier était sale et désagréable Evaluation Score = 1.12695298578 Result: negative-- exit bye!!
D'une certaine manière, le résultat est comme ça! Cela donne le sentiment que la polarité peut être jugée en considérant la fin de la phrase, plutôt que les informations syntaxiques.
Résumé
Cette fois, j'ai créé un script qui juge automatiquement la polarité émotionnelle d'une phrase en utilisant le classificateur de texte fastText et les données de révision du site EC. Il n'y a pas de problème s'il y a un texte de révision et une valeur d'évaluation du site EC, donc je pense que la même chose peut être faite avec les données d'Amazon ou de Pompare Mall.
Recommended Posts