[PYTHON] Puisque l'extraction des synonymes à l'aide de Word2Vec s'est bien déroulée, j'ai essayé de résumer l'analyse
introduction
Bonjour, je m'appelle @To_Murakami et je suis data scientist chez Speee. Je ne suis pas ingénieur, mais j'ai participé au Calendrier de l'Avent de l'entreprise avec l'intention de diffuser des exemples d'analyse, y compris le codage. C'est presque la fin de décembre, n'est-ce pas? Aujourd'hui, je voudrais vous présenter un exemple d'analyse utilisant le traitement du langage naturel appelé Word2Vec. Le but de la mise en œuvre de cette logique est que je voulais faire quelque chose comme ** détecteur de fluctuation de notation de mot (mot synonyme) **. Pourquoi pouvez-vous distinguer la fluctuation de la notation des mots de Word2Vec? Une fois que vous avez un aperçu de son fonctionnement (ci-dessous), vous pouvez comprendre pourquoi.
Comment fonctionne Word2Vec (facilement)
Word2Vec est littéralement ** un vecteur de mots . Naturellement, les nombres sont inclus dans le contenu vectorisé. En d'autres termes, il est possible de quantifier les données linguistiques des mots!
Le mécanisme de quantification est l'apprentissage et la compression de dimension par un réseau neuronal.
 La figure ci-dessus est un exemple d'un modèle typique appelé CBOW (Continuous Bug-of-words). Chaque mot à l'étape d'entrée est appelé un vecteur One-hot, et le "drapeau de" oui "ou" non "est exprimé par" 0/1 ". Ici, la vectorisation du mot "froid" est calculée par apprentissage. CBOW capture également les informations en plusieurs mots avant et après et les envoie à la couche de projection. L'apprentissage pondéré est effectué à partir de la couche de projection avec un réseau neuronal, et le vecteur de mot est calculé comme sortie. Le nombre de dimensions du vecteur de sortie et le nombre de dimensions de l'entrée peuvent être différents. Il peut être spécifié lors de la modélisation. (Vous pouvez également contrôler le nombre de mots placés dans le calque de projection avant et après.)
De cette manière, chaque vecteur de mot est calculé. Chaque nombre qui compose le vecteur indique la signification et les caractéristiques du mot. L'idée sous-jacente est basée sur la prémisse que " les mots qui ont des significations et des usages similaires apparaissent dans une séquence similaire de mots **". Si nous acceptons cette hypothèse, nous pouvons émettre l'hypothèse que les mots avec des vecteurs similaires ont des significations similaires. Les mots avec une notation similaire ou des synonymes avec la même signification auront des vecteurs similaires, on peut donc s'attendre à ce qu'ils puissent être extraits sur une échelle telle que la similitude cosinus.
La figure ci-dessus est un exemple d'un modèle typique appelé CBOW (Continuous Bug-of-words). Chaque mot à l'étape d'entrée est appelé un vecteur One-hot, et le "drapeau de" oui "ou" non "est exprimé par" 0/1 ". Ici, la vectorisation du mot "froid" est calculée par apprentissage. CBOW capture également les informations en plusieurs mots avant et après et les envoie à la couche de projection. L'apprentissage pondéré est effectué à partir de la couche de projection avec un réseau neuronal, et le vecteur de mot est calculé comme sortie. Le nombre de dimensions du vecteur de sortie et le nombre de dimensions de l'entrée peuvent être différents. Il peut être spécifié lors de la modélisation. (Vous pouvez également contrôler le nombre de mots placés dans le calque de projection avant et après.)
De cette manière, chaque vecteur de mot est calculé. Chaque nombre qui compose le vecteur indique la signification et les caractéristiques du mot. L'idée sous-jacente est basée sur la prémisse que " les mots qui ont des significations et des usages similaires apparaissent dans une séquence similaire de mots **". Si nous acceptons cette hypothèse, nous pouvons émettre l'hypothèse que les mots avec des vecteurs similaires ont des significations similaires. Les mots avec une notation similaire ou des synonymes avec la même signification auront des vecteurs similaires, on peut donc s'attendre à ce qu'ils puissent être extraits sur une échelle telle que la similitude cosinus.
- J'ai publié un article connexe il y a environ six mois. Se il vous plaît se référer. http://qiita.com/To_Murakami/items/6bd5638689166ec4821c
Avez-vous eu un mot proche?
La lecture dans la section mécanique est-elle vraiment correcte? J'ai parcouru 11 000 articles de beauté, créé un corpus et essayé de le vérifier. En conclusion, ** j'ai pu extraire des mots plus similaires que ce à quoi je m'attendais **! Ci-dessous, je vais donner plusieurs exemples.
<< Exemple 1: "Régime alimentaire" >>
 La «méthode du régime» et la «méthode du régime» ne sont que le résultat à cet effet.
La "proximité" est évaluée par la ** similarité cosinus ** du vecteur à deux mots ("score" ci-dessus). Plus la séquence de mots est similaire, plus la similitude est élevée.
«Méthode de régime» a la même signification que «régime» en raison de la fluctuation de la notation. Des mots tels que «amincissement» et «perte de poids» ont le même but et le même sens que suivre un régime et présentent un degré élevé de similitude.
La «méthode du régime» et la «méthode du régime» ne sont que le résultat à cet effet.
La "proximité" est évaluée par la ** similarité cosinus ** du vecteur à deux mots ("score" ci-dessus). Plus la séquence de mots est similaire, plus la similitude est élevée.
«Méthode de régime» a la même signification que «régime» en raison de la fluctuation de la notation. Des mots tels que «amincissement» et «perte de poids» ont le même but et le même sens que suivre un régime et présentent un degré élevé de similitude.
<< Exemple 2: "À la mode" >>
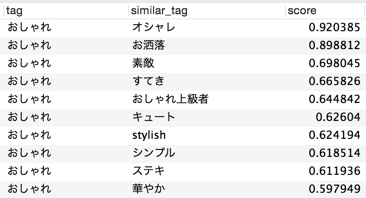 Après tout, «à la mode» et «à la mode», qui sont synonymes de fluctuation de notation, présentent un degré élevé de similitude. Ceci est suivi de mots qui donnent une impression ou une évaluation de «à la mode».
Après tout, «à la mode» et «à la mode», qui sont synonymes de fluctuation de notation, présentent un degré élevé de similitude. Ceci est suivi de mots qui donnent une impression ou une évaluation de «à la mode».
<< Exemple 3: "Faire" >>
 Pour un large éventail de mots tels que make, les mots qui indiquent des spécificités sont prioritaires (car ils sont utilisés dans un contexte similaire).
Pour un large éventail de mots tels que make, les mots qui indiquent des spécificités sont prioritaires (car ils sont utilisés dans un contexte similaire).
<< Exemple 4: "Aoi Miyazaki" >>
 Vous pouvez voir comment Aoi Miyazaki est vu par les gens dans le monde (^ _ ^;)
Vous pouvez voir comment Aoi Miyazaki est vu par les gens dans le monde (^ _ ^;)
<< Exemple 5: "Denim" >>
 Les vêtements qui correspondent aux mêmes bas sont également affichés, mais cela vous indique également la coordination du haut du corps qui va bien avec le denim.
Les vêtements qui correspondent aux mêmes bas sont également affichés, mais cela vous indique également la coordination du haut du corps qui va bien avec le denim.
<< Exemple 6: "Gras" >>
 C'est impitoyable (^ _ ^;)
C'est impitoyable (^ _ ^;)
<< Exemple 7: "Noël" >>
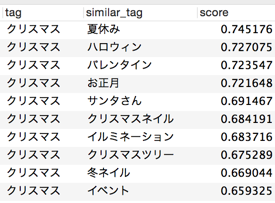 Peut-être parce qu'il s'agit d'un article sur la beauté, des mots liés à des événements et des événements sont répertoriés. Si le corpus est un blog personnel spécifique, la sortie peut changer.
Peut-être parce qu'il s'agit d'un article sur la beauté, des mots liés à des événements et des événements sont répertoriés. Si le corpus est un blog personnel spécifique, la sortie peut changer.
Ingéniosité
En se concentrant sur le ** prétraitement des données **, le contenu de la sortie sera bien meilleur. Le prétraitement est une analyse morphologique. Vous pourrez supprimer les mots inutiles et séparer les chaînes pour obtenir les mots que vous souhaitez.
① Extension du dictionnaire
J'ai appris en mettant à jour "mecab-ipadic-NEologd" (je pense que beaucoup de gens le savent). En plus de NEologd, nous avons ajouté ** un dictionnaire utilisateur de mots inconnus obtenu par notre propre logique **. Ajout de la nomenclature appropriée et des derniers mots tels que les noms de produits dans le dictionnaire utilisateur.
② Mot d'arrêt
Ajout d'une liste de mots qui ne sont pas évalués pour la vectorisation en tant que mots vides. Il se présentera sous la forme excluant les chaînes à un seul caractère et les mots à usage général.
la mise en oeuvre
J'ai utilisé une bibliothèque appelée ** gensim **. Avec gensim, vous pouvez l'implémenter en ** pratiquement quelques lignes **. Un peu pratique ♪
- Les E / S par DB sont omises.
Python
#!/usr/bin/python
# -*- coding: utf-8 -*-
from gensim.models import word2vec
import cython
from sqlalchemy import *
import pandas as pd
# fetch taglist from DB
engine_my = create_engine('mysql+mysqldb://pass:user@IP:port/db?charset=utf8&use_unicode=0',echo=False)
connection = engine_my.connect()
cur = connection.execute("select distinct(name) from tag;")
tags = []
for row in cur:
# need to decode into python unicode because db preserves strings as utf-8
# need to treat character sets altogether in one format
tags.append(row["name"].decode('utf-8'))
connection.close()
# Import text file and make a corpus
data = word2vec.Text8Corpus('text_morpho.txt')
# Train input data by Word2Vec(in option below, take CBOW method)
# Take about 5 min when training ~11000 documents
model = word2vec.Word2Vec(data, size=100, window=5, min_count=5, workers=2)
# Save temporary files
model.save("W2V.model")
# make similar word list (dict type)
similar_words = []
for tag in tags:
try:
similar_word = model.most_similar(positive=tag)
for i in range(10):
similar = {}
similar['tag'] = tag
similar['similar_tag'] = similar_word[i][0]
similar['score'] = similar_word[i][1]
similar_words.append(similar)
except:
pass
# Conver dict into DataFrame to filter data easily
df_similar = pd.DataFrame.from_dict(similar_words)
df_similar_filtered = df_similar[df_similar['similar_tag'].isin(tags)]
df_similar = df_similar.ix[:,['tag', 'similar_tag', 'score']]
Recommended Posts