[PYTHON] Implémentation de la méthode de gradient 1
introduction
Cela fait environ un mois que j'ai réservé ce jour sur le calendrier de l'Avent, et c'est presque Noël. D'une certaine manière, je sens que cette année s'est écoulée plus rapidement que d'habitude. Cette fois, pour ceux qui peuvent écrire Python dans une certaine mesure mais ne savent pas quel type d'implémentation sera concrètement fait par l'apprentissage automatique, je vais m'envoyer cela comme cadeau de Noël de ma part d'une manière facile à comprendre. Puisque la partie théorique et la partie pratique sont mélangées, veuillez ne prendre et ne manger que la partie que vous pouvez comprendre. Peut-être que vous pouvez toujours en avoir une idée. Veuillez également vous référer à ici pour une image intuitive de l'apprentissage automatique dans l'article précédent.
Quelle est la méthode du gradient?
La méthode du gradient est l'une des méthodes utilisées pour l'optimisation. Cette méthode de gradient est souvent utilisée pour trouver le poids $ W $ qui donne la sortie optimale.
Plus précisément, précédent erreur de somme carrée affichée
L'une des méthodes à minimiser est la méthode du gradient, qui utilise la différenciation pour trouver la valeur minimale.
Mise en œuvre de la différenciation
Commençons par implémenter une différenciation unidimensionnelle.
Fonction de $ x $ Différenciation de $ f (x) $ $ f ^ {\ prime} (x) $
numerical_differentiation.py
import numpy as np
import matplotlib.pylab as plt
def nu_dif(f, x):
h = 1e-4
return (f(x + h) - f(x))/(h)
def f(x):
return x ** 2
x = np.arange(0.0, 20.0, 0.1)
y = nu_dif(f, x)
plt.xlabel("x")
plt.ylabel("y")
plt.plot(x,y)
plt.show()
Le graphique ci-dessous $ y = f \ ^ {\ prime} (x) = 2x $ doit maintenant être tracé. [3382ED86-34E1-4011-BE99-ADE6A8E1E530.jpeg](https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/535913/d1b7deeb-6e5f-6070-6bb3-b234e3b27432 .jpeg)
$ h $ vaut environ 10 $ \ ^ {-4} $ pour éviter les erreurs d'arrondi.
prime
Dans le calcul numérique ci-dessus, $$ f ^ {\ prime} (x) = \ lim_ {h → 0} \ frac {f (x + h) --f (x --h)} {2h} \ tag {4} $ Un calcul comme $ améliorera la précision.
def nu_dif(f, x):
h = 1e-4
return (f(x + h) - f(x-h))/(2 * h)
Différenciation partielle
Maintenant que nous avons implémenté la différenciation unidimensionnelle, implémentons la différenciation multidimensionnelle. Ici, par souci de simplicité, nous allons différencier en deux dimensions. Pour une fonction à deux variables $ f (x, y) $, la différenciation entre $ x et y $, c'est-à-dire la différenciation partielle $ f_x, f_y 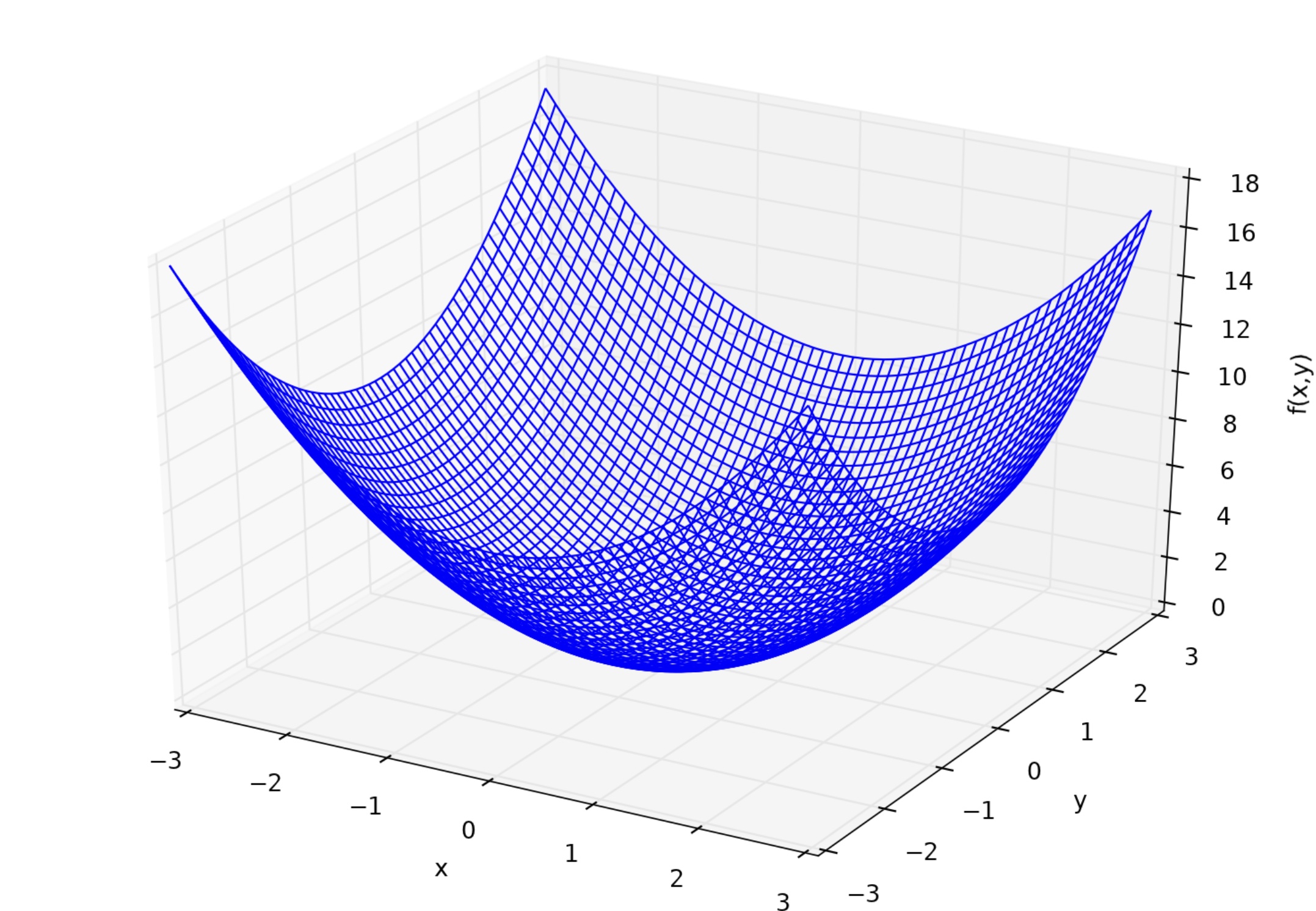
Maintenant, implémentons également une différenciation partielle. $ f_x = 2x, f_y = 2y $.
numerical_differentiation_2d.py
def f(x, y):
return x ** 2 + y ** 2
def nu_dif_x(f, x, y):
h = 1e-4
return (f(x + h, y) - f(x - h, y))/(2 * h)
def nu_dif_y(f, x, y):
h = 1e-4
return (f(x, y + h) - f(x, y - h))/(2 * h)
Pente
L'opérateur de gradient (nabla) pour la fonction à trois variables $ f (x, y, z) $ en coordonnées cartésiennes tridimensionnelles est
Implémentation de la méthode du gradient
Je vous remercie pour votre travail acharné. Cela couvre toutes les bases mathématiques nécessaires pour implémenter une méthode de gradient simple. Maintenant, implémentons un programme qui trouve automatiquement la valeur minimale de la fonction. Point arbitraire À partir de $ \ boldsymbol {x} ^ {(0)} $ $$ \ boldsymbol {x} ^ {(k + 1)} = \ boldsymbol {x} ^ {(k)} - \ eta \ nabla Faites glisser vers le bas jusqu'au point $ \ boldsymbol {x} ^ * $ qui donne la valeur minimale selon f \ tag {8} $$. Ici $ \ eta $ est un hyperparamètre que les humains doivent spécifier dans une quantité appelée coefficient d'apprentissage. $ \ eta $ doit être ajusté de manière appropriée pour ne pas être trop grand ou trop petit. Cette fois, je vais omettre l'explication sur le coefficient d'apprentissage.
Maintenant, implémentez la méthode du gradient pour trouver le point $ \ boldsymbol {x} ^ * = (x ^ *, y ^ *) $ qui donne la valeur minimale de $ f (x, y) = x ^ 2 + y ^ 2 $ Faisons le. Comme vous le savez déjà, si vous obtenez $ \ boldsymbol {x} ^ * = (0,0) $, vous réussissez.
numerical_gradient.py
#Renvoie le gradient de f
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for i in range(x.size):
tmp = x[i]
x[i] = tmp + h
f1 = f(x)
x[i] = tmp - h
f2 = f(x)
grad[i] = (f1 - f2)/(2 * h)
x[i] = tmp
return grad
#Méthode de gradient
def gradient_descent(f, x, lr = 0.02, step_num = 200):
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
#Définir f
def f(x):
return x[0] ** 2 + x[1] ** 2
#Sortie x
print(gradient_descent(f, np.array([10.0, 3.0])))
Le résultat de la définition de $ \ boldsymbol {x} ^ {(0)} = (10,3), \ eta = 0,02, k = 0,1, \ ldots, 199 $ [ 0.00284608 0.00085382] Doit être sorti. Puisque $ x et y $ valent à la fois environ 10 $ ^ {-3} $, on peut dire qu'ils valent presque 0 $.
Méthode de gradient dans l'apprentissage automatique
Le contour et l'utilité de la méthode du gradient ont été expliqués ci-dessus. En apprentissage automatique, la clé est de savoir comment trouver le poids optimal $ \ boldsymbol {W} $. Le poids optimal est la fonction de perte $ \ boldsymbol {W} $ qui minimise $ L $. La méthode du gradient peut être utilisée comme l'une des méthodes pour y parvenir. Le poids $ \ boldsymbol {W} $ est, par exemple, une matrice $ 2 \ times2 $
\boldsymbol{W}=\left(\begin{array}{cc}
w_{11} & w_{12} \\
w_{21} & w_{22}
\end{array}\right) \tag{9}
Pour la fonction de perte $ L $ donnée dans
\nabla L \equiv \frac{\partial L}{\partial \boldsymbol {W}}\equiv\left(\begin{array}{cc}
\frac{\partial L}{\partial w_{11}} & \frac{\partial L}{\partial w_{12}} \\
\frac{\partial L}{\partial w_{21}} & \frac{\partial L}{\partial w_{22}}
\end{array}\right) \tag{10}
Calculer
Résumé
Merci d'avoir lu jusqu'ici. Cette fois, j'ai commencé par une simple implémentation différentielle unidimensionnelle utilisant Python et je l'ai étendue à plusieurs dimensions. Ensuite, j'ai présenté l'opérateur de gradient Nabla et appris la méthode de gradient pour trouver la valeur minimale d'une fonction arbitraire qui l'utilisait. Et enfin, je vous ai dit que l'utilisation de la méthode du gradient peut réduire la fonction de perte, c'est-à-dire améliorer la précision de l'apprentissage automatique. Cependant, bien que les poids ainsi obtenus soient souvent extrêmes, nous avons également constaté que le problème est que la fonction de perte n'est pas minimisée, ni optimisée. À partir de la prochaine fois, j'essaierai une autre approche à ce problème.
en conclusion
Cette fois, j'ai eu la chance d'être présenté par un ami et de poster sur ce calendrier de l'Avent de l'Université de Chiba 2019. C'était un peu difficile parce que je l'ai résumé à partir d'une partie assez rudimentaire, mais j'ai pu écrire plus longtemps que d'habitude et ressentir un sentiment de fatigue et d'accomplissement. En plus de mes messages, diverses personnes publient de merveilleux articles sur divers sujets à différents niveaux, alors jetez un œil.
Recommended Posts