[Python / Chrome] Paramètres de base et opérations de scraping
introduction
J'avais l'habitude de gratter avec VBA, mais je ne sais pas combien de temps Internet Explorer peut être utilisé. J'ai donc commencé à gratter ** Chrome ** avec ** Python **. L'environnement est ** Windows **.
C'est plus de contenu maintenant, mais j'écrirai les bases que vous devriez garder à l'esprit (probablement le contenu que vous oublierez dans quelques mois) comme un rappel personnel.
** <Table des matières> ** [1. Installer le sélénium](# 1-Installer le sélénium) [2. Télécharger WebDriver](# 2-Télécharger Webdriver) [3. Description du code source](# 3-Description du code source)
1. Installez le sélénium
Tout d'abord, installez un package de contrôle du navigateur appelé selenium en Python.
Vous pouvez l'installer en tapant la commande py -m pip install selenium à partir de l'invite de commande comme suit:
invite de commande
>py -m pip install selenium
Collecting selenium
Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB)
|████████████████████████████████| 904 kB 1.1 MB/s
Collecting urllib3
Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
|████████████████████████████████| 127 kB 939 kB/s
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.25.11
Pour plus de détails, y compris comment installer Python lui-même, voir ici.
2. Téléchargez WebDriver
Ensuite, vous aurez besoin de ** WebDriver ** pour votre type de navigateur.
● Ouvrages de référence [Hidekatsu Nakajima "Livre qui automatise Excel, la messagerie et le Web avec Python" SB Creative](https://www.amazon.co.jp/Python%E3%81%A7Excel%E3%80%81%E3%83% A1% E3% 83% BC% E3% 83% AB% E3% 80% 81 Web% E3% 82% 92% E8% 87% AA% E5% 8B% 95% E5% 8C% 96% E3% 81% 99% E3% 82% 8B% E6% 9C% AC-% E4% B8% AD% E5% B6% 8B% E8% 8B% B1% E5% 8B% 9D / dp / 4815606390)
2-1. Site de téléchargement
Ouvrez la page de téléchargement des pilotes Chrome (https://sites.google.com/a/chromium.org/chromedriver/downloads) comme indiqué ci-dessous.
 Dans le cadre rouge ci-dessus, il existe trois versions (87, 86, 85) de Chrome Driver.
Parmi ceux-ci, vous téléchargerez celui qui correspond à la version de Chrome que vous utilisez actuellement (voir la section suivante).
Dans le cadre rouge ci-dessus, il existe trois versions (87, 86, 85) de Chrome Driver.
Parmi ceux-ci, vous téléchargerez celui qui correspond à la version de Chrome que vous utilisez actuellement (voir la section suivante).
Vous pouvez vérifier le lien WebDriver pour chaque navigateur dans la section Driver de" PyPI / selenium ".
2-2. Vérification de la version de Chrome
Vous pouvez vérifier la version en ouvrant «À propos de Google Chrome (G)» depuis «Aide (H)» dans le menu du navigateur Chrome.
 Dans mon environnement, la version de Chrome est «86», donc à partir du site de téléchargement que j'ai mentionné plus tôt, cliquez sur le «Pilote Chrome 86.0.4240.22» correspondant.
Dans mon environnement, la version de Chrome est «86», donc à partir du site de téléchargement que j'ai mentionné plus tôt, cliquez sur le «Pilote Chrome 86.0.4240.22» correspondant.
2-3. Acquisition de WebDriver
Lorsque vous voyez un écran comme celui ci-dessous, cliquez sur le pilote Chrome pour Windows pour l'installer.
 Si vous décompressez le fichier téléchargé, vous obtiendrez un WebDriver appelé
Si vous décompressez le fichier téléchargé, vous obtiendrez un WebDriver appelé chromedriver.exe comme suit.
 Vous utiliserez ce pilote dans le même dossier que le fichier de code source Python (vous pouvez le placer dans un dossier différent et spécifier le chemin dans le code source).
Vous utiliserez ce pilote dans le même dossier que le fichier de code source Python (vous pouvez le placer dans un dossier différent et spécifier le chemin dans le code source).
3. Description du code source
Voici le code qui ouvre le site yahoo et effectue une recherche:
Test01.py
import time
from selenium import webdriver
driver = webdriver.Chrome() #Créer une instance de WebDriver
driver.get('https://www.yahoo.co.jp/') #Ouvrez le navigateur en spécifiant l'URL
time.sleep(2) #Attendez 2 secondes
search_box = driver.find_element_by_name('p') #Identifier la zone de recherche par attribut de nom
search_box.send_keys('Grattage') #Saisissez du texte dans la zone de recherche
search_box.submit() #Envoyer le libellé de la recherche (comme pour appuyer sur le bouton de recherche)
time.sleep(2) #Attendez 2 secondes
driver.quit() #Fermer le navigateur
Il s'agit d'une modification mineure du code sur le site ChromeDriver (http://chromedriver.chromium.org/getting-started). Une fois exécuté, le navigateur (Chrome) sera lancé et le mot «scraping» sera recherché sur le site Yahoo.
Ci-dessous, je laisserai une brève explication.
3-1. Importation de la bibliothèque
Sample.py
import time
from selenium import webdriver
Fondamentalement, il est décrit par la correspondance de import [nom de la bibliothèque].
La première ligne importe la bibliothèque standard «time». La deuxième ligne importe une bibliothèque appelée «webdriver» à partir du paquet «selenium» que vous venez d'installer.
3-2. Création d'une instance de WebDriver
3-2-1. Lorsque le pilote est enregistré dans le même dossier que le code source
Si ChromeDriver est enregistré dans le même dossier que le code source, vous pouvez créer une instance de WebDriver en écrivant comme suit.
Sample.py
driver = webdriver.Chrome()
3-2-2. Lorsque le pilote est enregistré dans un dossier différent du code source
Si le pilote est enregistré dans le répertoire (dossier) un niveau inférieur, écrivez comme suit.
Sample.py
driver = webdriver.Chrome('Driver/chromedriver')
Le Pilote ci-dessus est le nom du répertoire (nom du dossier).
3-2-3. À propos des noms de variables d'instance
Notez que la variable «driver» peut être n'importe quoi (bien sûr).
Vous pouvez définir la variable sur d comme suit:
Sample.py
d = webdriver.Chrome()
3-3. Ouvrez le navigateur en spécifiant l'URL
Vous pouvez ouvrir le site spécifié en écrivant «[nom de l'instance] .get ([nom de l'URL])» comme suit.
Sample.py
driver.get('https://www.yahoo.co.jp/')
3-4. Récupérez le nœud
3-4-1. Vérification du HTML
Pour effectuer la recherche, vous devez lire le emplacement de la zone de texte pour entrer le` mot de recherche, tel que:
 Ceci sera obtenu en regardant le HTML de la page WEB.
Pour voir le HTML dans la zone de texte, cliquez dessus avec le bouton droit de la souris et sélectionnez Valider.
Ceci sera obtenu en regardant le HTML de la page WEB.
Pour voir le HTML dans la zone de texte, cliquez dessus avec le bouton droit de la souris et sélectionnez Valider.
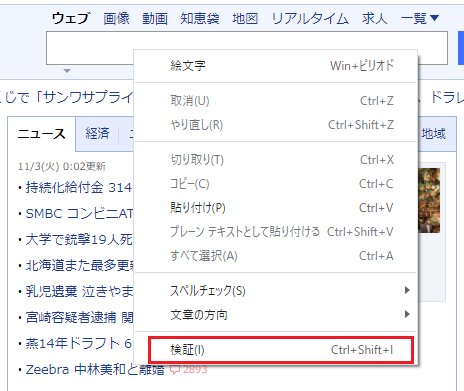 Ensuite, le HTML du site sera affiché sur le côté droit.
La partie bleue est le HTML de la partie concernée.
Ensuite, le HTML du site sera affiché sur le côté droit.
La partie bleue est le HTML de la partie concernée.
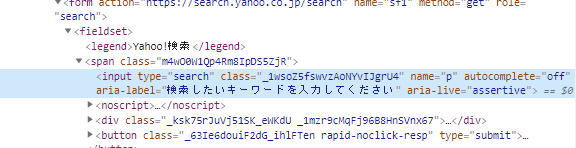 Dans ce code HTML, les valeurs d'attribut telles que «type», «class» et «name» sont spécifiées dans la balise «input».
En utilisant ces noms de balises et ces valeurs d'attribut comme indices, vous spécifierez les parties requises (nœuds).
Dans ce code HTML, les valeurs d'attribut telles que «type», «class» et «name» sont spécifiées dans la balise «input».
En utilisant ces noms de balises et ces valeurs d'attribut comme indices, vous spécifierez les parties requises (nœuds).
Le même nom de balise et la même valeur d'attribut peuvent être dupliqués, cherchez donc d'abord celui qui est unique (il n'y en a qu'un sur la page). Après vérification, j'ai trouvé qu'il n'y avait qu'une seule des «classe» et «nom» suivantes dans la page.
class="_1wsoZ5fswvzAoNYvIJgrU4"
name="p"
3-4-2. Code source pour obtenir le nœud
Ici, en utilisant la valeur d'attribut plus simple de nom, obtenez la partie nécessaire (nœud) avec le code suivant.
Puisque search_box est une variable, cela peut être un alias.
Sample.py
search_box = driver.find_element_by_name('p')
Si vous voulez obtenir un nœud avec la valeur d'attribut de nom, décrivez-le avec la disposition de [nom de l'instance] .find_element_by_name ([valeur de l'attribut]).
Pour l'obtenir avec la valeur d'attribut de class, écrivez comme suit.
Sample.py
search_box = driver.find_element_by_class_name('_1wsoZ5fswvzAoNYvIJgrU4')
3-4-3. Méthode d'obtention des nœuds
Il existe plusieurs méthodes pour obtenir le nœud en plus de name et class (this site). référence).
3-4-3-1. Lors de l'acquisition d'un seul nœud
| Méthode | Objectif d'acquisition |
|---|---|
| find_element_by_id | nom d'id (valeur d'attribut) |
| find_element_by_name | nom nom (valeur d'attribut) |
| find_element_by_xpath | Obtenez avec XPath |
| find_element_by_link_text | Obtenir avec le texte du lien |
| find_element_by_partial_link_text | Obtenir dans le cadre du texte du lien |
| find_element_by_tag_name | Nom de la balise (élément) |
| find_element_by_class_name | nom de classe (valeur d'attribut) |
| find_element_by_css_selector | Obtenez avec le sélecteur |
Lors de la récupération d'un seul numéro, seul le premier nœud trouvé sera récupéré, même s'il y en a un avec le même nom.
Si vous n'êtes pas familier avec XPath comme moi, veuillez vous référer à cet article "Requis pour créer un robot d'exploration! Résumé de la notation XPATH". .. Je pense que ce sera très pratique si vous pouvez le maîtriser.
3-4-3-2. Lors de l'acquisition de plusieurs nœuds (liste)
| Méthode | Objectif d'acquisition |
|---|---|
| find_elements_by_name | nom d'id (valeur d'attribut) |
| find_elements_by_xpath | nom nom (valeur d'attribut) |
| find_elements_by_link_text | Obtenir avec le texte du lien |
| find_elements_by_partial_link_text | Obtenir dans le cadre du texte du lien |
| find_elements_by_tag_name | Nom de la balise (élément) |
| find_elements_by_class_name | nom de classe (valeur d'attribut) |
| find_elements_by_css_selector | Obtenez avec le sélecteur |
Lors de la récupération d'un seul numéro, tous les nœuds avec le même nom seront récupérés au format liste.
Dans la description HTML d'origine, il existe des règles telles qu'un «nom d'id» dans une page et plusieurs «nom de classe» et «nom de nom», mais certains sites ont plusieurs noms d'id. Par conséquent, il existe plusieurs méthodes d'acquisition (liste) telles que find_elements_by_name.
Dans le cas d'une acquisition multiple, les nœuds étant acquis sous forme de liste, il est nécessaire de spécifier jusqu'au numéro d'élément comme suit.
Sample.py
search_box = driver.find_elements_by_name('p')[0]
3-4-4. [Référence] Récupère le nœud (sous l'élément enfant) du nœud
Lorsque vous obtenez un nœud, vous pouvez facilement écrire du code si vous avez un nom d'identifiant unique, etc., mais parfois ce n'est pas si pratique. Dans un tel cas, il arrive souvent qu'une large plage de nœuds soit spécifiée une fois et que les nœuds de ses éléments enfants (éléments petits-enfants) soient spécifiés, par exemple en effectuant une recherche affinée.
La méthode d'obtention du nœud du nœud peut être réalisée en concaténant simplement les méthodes comme suit.
Sample.py
search_box = driver.find_element_by_tag_name('fieldset').find_element_by_tag_name('input')
Il est également possible d'écrire les variables séparément (ci-dessous).
Sample.py
search_box1 = driver.find_element_by_tag_name('fieldset')
search_box = search_box1.find_element_by_tag_name('input')
Dans le deuxième raffinement, les nœuds sous l'élément enfant sont ciblés.
3-5. Saisissez du texte dans la zone de recherche
Pour saisir du texte dans la zone de recherche, utilisez la méthode send_keys et écrivez:
Ici, le mot «grattage» est entré dans la zone de texte.
Sample.py
search_box.send_keys('Grattage')
3-6. Effectuer une recherche
Vous pouvez soumettre le texte saisi dans le formulaire de recherche au serveur du site Web (c'est-à-dire effectuer la recherche) en utilisant la méthode submit comme suit.
Sample.py
search_box.submit()
Cela signifie que vous envoyez des données de formulaire HTML au serveur.
Vous pouvez obtenir le même résultat en exécutant simplement la commande "cliquez sur le bouton de recherche" comme indiqué ci-dessous.
Sample.py
search_box = driver.find_element_by_class_name('PHOgFibMkQJ6zcDBLbga8').click()
Cela signifie que le nœud est acquis par le nom de classe pour le bouton de recherche et que le bouton de recherche est cliqué par la méthode clic.
3-7. Fermez le navigateur
Vous pouvez fermer le navigateur ouvert avec le code suivant.
Sample.py
driver.quit()
enfin
Ce qui précède est-il «les bases de base»?
En écrivant ceci, je me suis demandé comment obtenir innerText et externalHTML, mais les méthodes étaient également préparées normalement dans ce domaine.
Le grattage Python est utilisé par de nombreuses personnes, il semble donc assez facile à utiliser.
Recommended Posts