[PYTHON] [Français] Spark Memory Management depuis 1.6.0
Traduit l'article ici.
Avec le début du développement d'Apache Spark 1.6.0, le modèle de gestion de la mémoire a changé. L'ancien modèle de gestion de la mémoire était la classe StaticMemoryManger. Maintenant, ça s'appelle «héritage». Le mode "Legacy" est désactivé par défaut. Cela donnera des résultats différents si vous exécutez le même code sur 1.5.x et 1.6.0. Soyez prudent à ce sujet. Vous pouvez activer le paramètre spark.memory.useLegacyMode pour la compatibilité. Ceci est désactivé par défaut.
Il y a environ un an, j'ai écrit sur la gestion de la mémoire pour le modèle «hérité» dans un article intitulé Spark Architecture. J'ai également brièvement écrit sur la gestion de la mémoire pour l'implémentation Spark Shuffle.
Cet article est un nouveau modèle de gestion de la mémoire dans ʻUnifiedMemoryManager` utilisé dans Apache Spark 1.6.0 Cette section explique.
Pour résumer brièvement, le nouveau modèle de gestion de la mémoire ressemble à ceci.
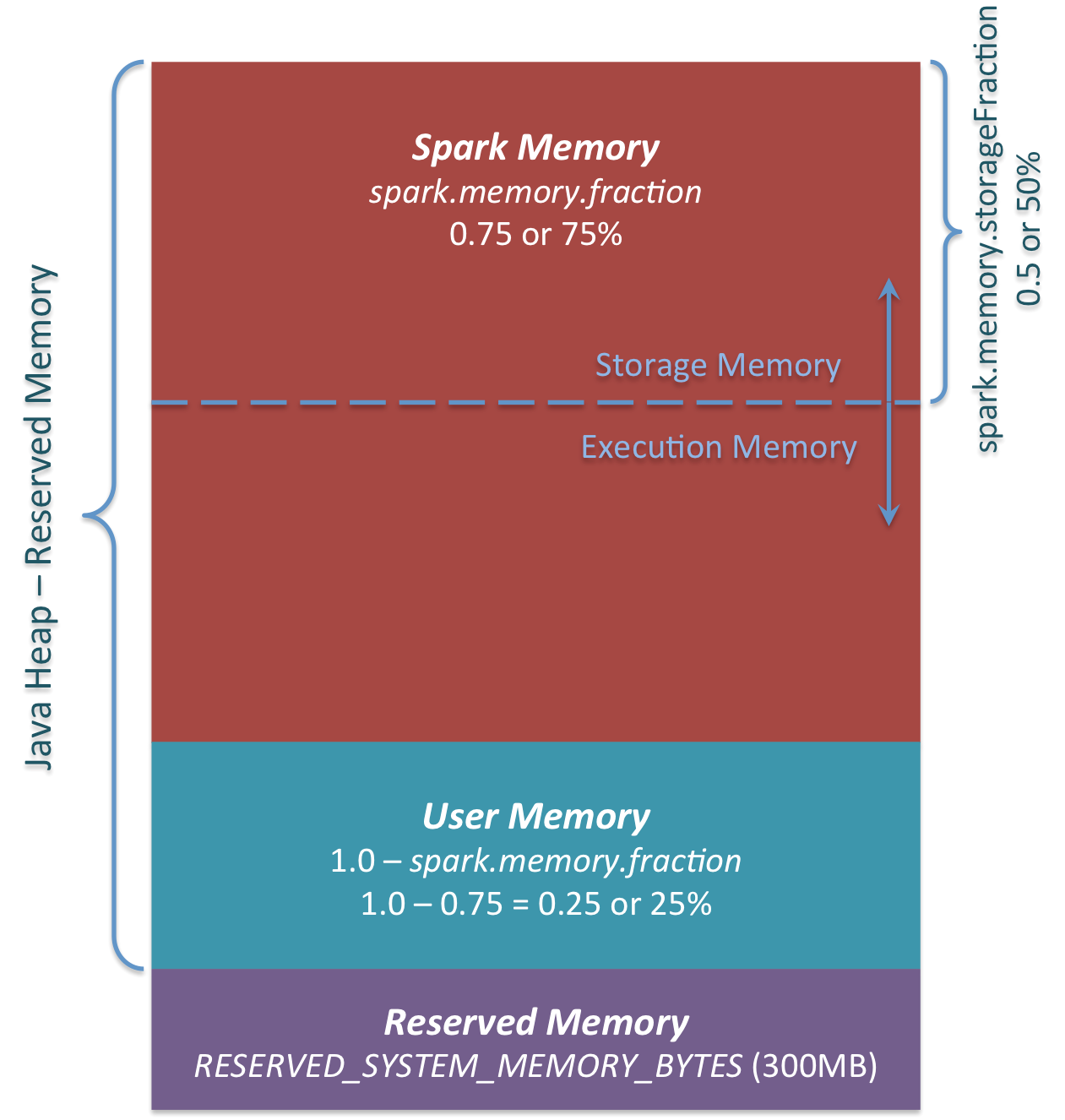
Les trois principales zones de mémoire sont visibles sur la figure.
Reserved Memory
Mémoire réservée par le système. Cette taille est codée en dur. Dans Spark 1.6.0, cette valeur est de 300 Mo. 300 Mo de RAM ne sont pas utilisés pour les calculs Spark. Cette valeur ne peut pas être modifiée sans recompiler Spark ou changer spark.testing.reservedMemory. Cette valeur sert à des fins de test et il n'est pas recommandé de la modifier en production. Cette mémoire est appelée «réservée» et n'est jamais utilisée par Spark. Cette valeur peut définir une limite supérieure sur la quantité de mémoire pouvant être utilisée par les informations d'utilisation de Spark. Même si vous souhaitez utiliser tout Java Heap pour le cache de Spark, cette zone "réservée" ne sera pas utilisée. (En fait, ce n'est pas une pièce de rechange. C'est un endroit pour enregistrer l'objet interne de Spark.) Si vous ne donnez pas à l'exécuteur Spark un tas d'au moins 1,5 * mémoire réservée = 450 Mo, vous obtiendrez un message d'erreur "veuillez utiliser une taille de tas plus grande". Je vais.
User Memeory Ce pool de mémoire reste en mémoire même après l'allocation de la mémoire de Spark. C'est à l'utilisateur comment utiliser cette mémoire. Vous pouvez enregistrer la structure de données utilisée dans la transformation de RDD. Par exemple, vous pouvez réécrire l'opérateur de la variante mapPartitions de Spark, qui peut avoir une table de hachage et utiliser UserMemory pour l'agrégation. Dans Spark 1.6.0, la taille du pool de mémoire est calculée comme suit: "Java Heap" - "Reserved Memory" * (1.0 --spark.memory.fraction) Par défaut, c'est équivalent à: ("Java Heap" --300 Mo) * 0,25 À titre d'exemple, un tas de 4 Go peut avoir 949 Mo de UserMemory. Encore une fois, il appartient à l'utilisateur quelles données stocker pour cette UserMemory. Spark n'a rien à voir avec ce que fait l'utilisateur et s'il franchit les limites de la zone mémoire. Si vous ignorez cette zone de mémoire, vous pouvez obtenir une erreur MOO.
Spark Memory
Il s'agit d'un pool de mémoire géré par Apache Spark. Cette taille est calculée comme suit: ("Java Heap" - "Reserved Memory") * spark.memory.fraction. Dans Spark 1.6.0, il s'agit de ("Java Heap" -300 Mo) * 0,75. Par exemple, avec un segment de mémoire de 4 Go, la mémoire Spark serait de 2847 Mo. Ce pool de mémoire est alloué à deux zones. Mémoire de stockage et mémoire d'exécution. Cette limite peut être modifiée avec le paramètre spark.memory.storageFraction. La valeur par défaut est 0,5. L'avantage de cette nouvelle zone mémoire est que cette frontière n'est pas statique. Et si une pression de mémoire se produit, les limites changent. Par exemple, une zone peut emprunter de l'espace à l'autre pour augmenter sa taille. Eh bien, nous parlerons de la façon dont cette limite de mémoire change plus tard. Voyons d'abord comment cette mémoire est utilisée.
Storage Memory
Ce pool de mémoire est utilisé comme espace temporaire pour «dérouler» les données mises en cache et les données sérialisées de Spark. Les données "diffusées" sont également enregistrées en tant que bloc de cache. Si vous êtes intéressé par "dérouler", jetez un œil à ce code de déroulement. Comme vous pouvez le voir, le déroulement n'a pas besoin de suffisamment de mémoire pour le bloc déroulé. S'il n'y a pas assez de mémoire pour la partition déroulée et que le niveau de persistance permet au lecteur de faire des données, les données seront placées directement sur le lecteur. Pour la "diffusion", toutes les données de diffusion sont mises en cache selon le niveau de persistance "MEMORY_AND_DISK".
Execution Memory
Ce pool de mémoire stocke les objets dont vous avez besoin lors de l'exécution des tâches Spark. Par exemple, il est utilisé pour stocker la mémoire tampon d'état intermédiaire de shuffle du côté carte, ou pour stocker la table de hachage utilisée pour l'agrégation de hachage. Ce pool de mémoire écrira des données sur le disque s'il n'y a pas assez de mémoire. Cependant, vous ne pouvez pas exclure des blocs de ce pool de mémoire d'autres threads (tâches).
Voyons maintenant comment fonctionne la limite entre la mémoire de stockage et la mémoire d'exécution. Il n'est pas possible de forcer un bloc du pool de mémoire en tant que caractéristique de la mémoire d'exécution. Comme ils sont utilisés pour les calculs intermédiaires, les processus qui nécessitent cette mémoire échoueront sans ce bloc de mémoire. Cela ne s'applique pas à la mémoire de stockage (un simple cache dans la RAM). Si vous souhaitez supprimer le bloc du pool de mémoire, vous pouvez mettre à jour les métadonnées du bloc comme si le bloc avait été évacué (ou simplement supprimé) sur le disque dur. Spark recalculera s'il essaie de lire ce bloc à partir du disque dur ou si le niveau persistant ne permet pas d'écrire sur le disque dur.
Vous pouvez forcer le bloc à sortir de Storge Memory. En revanche, la mémoire d'exécution ne peut pas être utilisée. Quand la mémoire d'exécution écrit-elle la mémoire à partir de la mémoire de stockage? Cela se produit dans les cas suivants.
--S'il y a trop de mémoire dans la mémoire de stockage. Par exemple, si le bloc mis en cache n'utilise pas toute la mémoire. Dans ce cas, réduisez la taille du pool de mémoire de stockage et augmentez le pool de mémoire d'exécution.
--Lorsque la taille du pool de mémoire de stockage dépasse la taille de la zone de mémoire de stockage initiale et que toute la zone est utilisée. Dans ce cas, les blocs en mémoire sont forcés hors du pool de mémoire de stockage (écrits sur le lecteur) lorsque la taille initiale n'est pas atteinte.
Deuxièmement, le pool de mémoire de stockage peut emprunter de l'espace à partir de la mémoire d'exécution s'il y en a trop dans le pool de mémoire d'exécution.
La taille de la zone de mémoire de strage initiale est calculée comme suit: «Spark Memory» * spark.memory.storageFraction = («Java Heap» - «Reserved Memory») * spark.memory.fraction * spark.memory.storageFraction. Par défaut, il équivaut à: («Java Heap» - 300 Mo) * 0,75 * 0,5 = («Java Heap» - 300 Mo) * 0,375. Par exemple, un tas de 4 Go utilise 1 423,5 Mo de RAM comme mémoire de stockage initiale.
Cela signifie que si la somme de la quantité de données dans le cache Spark et le cache de l'exécuteur est la même que la taille initiale de la mémoire de stockage, alors au moins la taille de la zone de stockage est la même que la taille initiale des données. En effet, il n'est pas possible de déplacer des données hors de la mémoire tout en réduisant leur taille. Toutefois, si la zone de mémoire d'exécution dépasse la taille initiale avant que la mémoire de stockage ne soit épuisée, vous ne pouvez pas forcer la mémoire d'exécution à expulser les entrées. Enfin, tandis que la mémoire d'exécution contient la mémoire, le traitement est effectué avec la petite taille de la mémoire de stockage (car la mémoire est dédiée à la mémoire d'exécution).