[PYTHON] Data wrangling of Excel file of my number card issue status (septembre)
introduction
Ministère des affaires intérieures et des communications My Number System and My Number Card
- Format Excel de l'état d'émission de ma carte numérique (au 1er septembre, 2ème année de Reiwa)
Convertir au format CSV de My Number Card Spread Status Dashboard
- mynumbercard_statistics
- Le code de caractère des données récupérées était incorrect, je l'ai donc corrigé
- 1er août, 2ème année de Rewa et 1er septembre, 2ème année de Rewa Étant donné que le format des fichiers Excel est différent, seul le 1er septembre, 2ème année de Rewa est pris en charge.
- La date de base est août à la fin de chaque tableau, et septembre est dans le nom de la colonne (identique au PDF)
- Séparation de chaque table
Cliquez ici pour connaître l'état de l'émission de la carte My Number (à compter du 1er août, 2e année de Reiwa) https://qiita.com/barobaro/items/05efbb6aa2c759c80ff0
- En septembre, la date de base est dans le nom de la colonne et chacune est extraite
- Chaque table a un point dans le temps dans les 2e et 3e colonnes du nom de la colonne, donc extraire en fonction de cela
Data wrangling
import csv
import datetime
import re
import pandas as pd
def wareki2date(s):
m = re.search("(H|R|Heisei|Reiwa)([0-9 yuans]{1,2})[.Année]([0-9]{1,2})[.Mois]([0-9]{1,2})journée?",s)
year, month, day = [1 if i == "Ancien" else int(i) for i in m.group(2, 3, 4)]
if m.group(1) in ["Heisei", "H"]:
year += 1988
elif m.group(1) in ["Reiwa", "R"]:
year += 2018
return datetime.date(year, month, day).strftime("%Y/%m/%d")
def df_conv(df, col_name, population_date, delivery_date):
df.set_axis(col_name, axis=1, inplace=True)
df["Date de base du calcul de la population"] = population_date
df["Date de base pour le calcul du nombre de livraisons"] = delivery_date
df.insert(0, "Date de base du calcul", delivery_date)
return df
def my_round(s):
return int(s * 1000 + 0.5) / 10
df = pd.read_excel(
"https://www.soumu.go.jp/main_content/000707709.xlsx", sheet_name=1, header=None
)
df.dropna(thresh=3, inplace=True)
dfg = df.groupby(
(df[1].str.contains("Point dans le temps", na=False) | df[2].str.contains("Point dans le temps", na=False)).cumsum()
)
dfs = [g.dropna(how="all", axis=1).reset_index(drop=True) for _, g in dfg]
print(len(dfs))
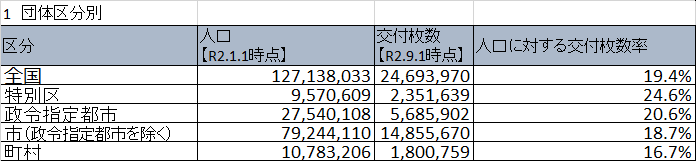
#Par classification de groupe
population_date = wareki2date(dfs[0].iat[0, 1])
delivery_date = wareki2date(dfs[0].iat[0, 2])
df0 = df_conv(
dfs[0].iloc[1:].reset_index(drop=True),
["Classification", "population", "Nombre de livraisons", "populationに対するNombre de livraisons率"],
population_date,
delivery_date,
)
df0["Nombre de subventions à la population"] = df0["Nombre de subventions à la population"].apply(my_round)
df0.to_csv(
"summary_by_types.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df0
#Liste des préfectures
population_date = wareki2date(dfs[3].iat[0, 1])
delivery_date = wareki2date(dfs[3].iat[0, 2])
df3 = df_conv(
dfs[3].iloc[1:].reset_index(drop=True),
["Nom des préfectures", "Nombre total (population)", "Nombre de livraisons", "人口に対するNombre de livraisons率"],
population_date,
delivery_date,
)
df3["Nombre de subventions à la population"] = df3["Nombre de subventions à la population"].apply(my_round)
df3.to_csv(
"all_prefectures.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df3
#Par sexe et âge
population_date = wareki2date(dfs[4].iat[0, 1])
delivery_date = wareki2date(dfs[4].iat[0, 4])
df4 = df_conv(
dfs[4].iloc[2:].reset_index(drop=True),
[
"âge",
"population(Homme)",
"population(femme)",
"population(Total)",
"Nombre de livraisons(Homme)",
"Nombre de livraisons(femme)",
"Nombre de livraisons(Total)",
"Taux de subvention(Homme)",
"Taux de subvention(femme)",
"Taux de subvention(Total)",
"Ratio du nombre de subventions à l'ensemble(Homme)",
"Ratio du nombre de subventions à l'ensemble(femme)",
"Ratio du nombre de subventions à l'ensemble(Total)",
],
population_date,
delivery_date,
)
df4["Taux de subvention(Homme)"] = df4["Taux de subvention(Homme)"].apply(my_round)
df4["Taux de subvention(femme)"] = df4["Taux de subvention(femme)"].apply(my_round)
df4["Taux de subvention(Total)"] = df4["Taux de subvention(Total)"].apply(my_round)
df4["Ratio du nombre de subventions à l'ensemble(Homme)"] = df4["Ratio du nombre de subventions à l'ensemble(Homme)"].apply(my_round)
df4["Ratio du nombre de subventions à l'ensemble(femme)"] = df4["Ratio du nombre de subventions à l'ensemble(femme)"].apply(my_round)
df4["Ratio du nombre de subventions à l'ensemble(Total)"] = df4["Ratio du nombre de subventions à l'ensemble(Total)"].apply(my_round)
df4.to_csv(
"demographics.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig",
)
df4
#Par ville
population_date = wareki2date(dfs[5].iat[0, 2])
delivery_date = wareki2date(dfs[5].iat[0, 3])
df5 = df_conv(
dfs[5].iloc[2:].reset_index(drop=True),
["Nom des préfectures", "Nom de Ville", "Nombre total (population)", "Nombre de livraisons", "人口に対するNombre de livraisons率"],
population_date,
delivery_date,
)
df5["Nombre de subventions à la population"] = df5["Nombre de subventions à la population"].apply(my_round)
df5["Nom de Ville"] = df5["Nom de Ville"].replace(r"\s", "", regex=True)
df5["Nom de Ville"] = df5["Nom de Ville"].mask(df5["Nom des préfectures"] + df5["Nom de Ville"] == "Ville de Shinoyama, préfecture de Hyogo", "Ville de Tamba Shinoyama")
df5["Nom de Ville"] = df5["Nom de Ville"].mask(df5["Nom des préfectures"] + df5["Nom de Ville"] == "Ville de Kajiwara, comté de Takaoka, préfecture de Kochi", "Hibara-cho, Takaoka-gun")
df5["Nom de Ville"] = df5["Nom de Ville"].mask(df5["Nom des préfectures"] + df5["Nom de Ville"] == "Ville de Sue, comté de Kasuya, préfecture de Fukuoka", "Sue-cho, Kasuya-gun")
if pd.Timestamp(df5.iloc[0]["Date de base du calcul"]) < datetime.date(2018, 10, 1):
df5["Nom de Ville"] = df5["Nom de Ville"].mask(
df5["Nom des préfectures"] + df5["Nom de Ville"] == "Ville de Nakagawa, préfecture de Fukuoka", "Nakagawa-cho, Chikushi-gun"
)
else:
df5["Nom de Ville"] = df5["Nom de Ville"].mask(
df5["Nom des préfectures"] + df5["Nom de Ville"] == "Ville de Nakagawa, comté de Chikushi, préfecture de Fukuoka", "Ville de Nakagawa"
)
df_code = pd.read_csv(
"https://docs.google.com/spreadsheets/d/e/2PACX-1vSseDxB5f3nS-YQ1NOkuFKZ7rTNfPLHqTKaSag-qaK25EWLcSL0klbFBZm1b6JDKGtHTk6iMUxsXpxt/pub?gid=0&single=true&output=csv",
dtype={"Code de groupe": int, "Nom des préfectures": str, "Nom du comté": str, "Nom de Ville": str},
)
df_code["Nom de Ville"] = df_code["Nom du comté"].fillna("") + df_code["Nom de Ville"]
df_code.drop("Nom du comté", axis=1, inplace=True)
df5 = pd.merge(df5, df_code, on=["Nom des préfectures", "Nom de Ville"], how="left")
df5["Code de groupe"] = df5["Code de groupe"].astype("Int64")
df5.to_csv(
"all_localgovs.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df5