[PYTHON] [Introduction à matplotlib] Lire l'heure de fin à partir des données COVID-19 ♬
Il y a des choses que j'ai apprises de la simulation précédente du nouveau Corona, mais si vous regardez de près, cela me fait penser que le pic d'infection peut être prévisible à partir du graphique de l'état d'infection de Corona.
C'était la simulation suivante.
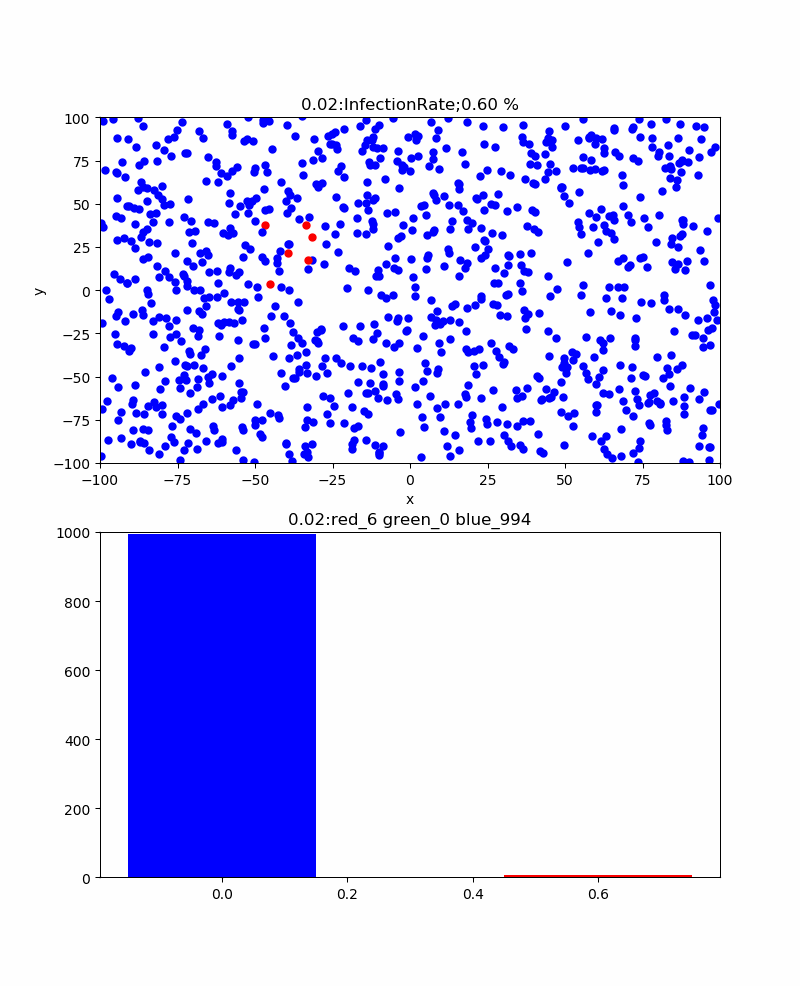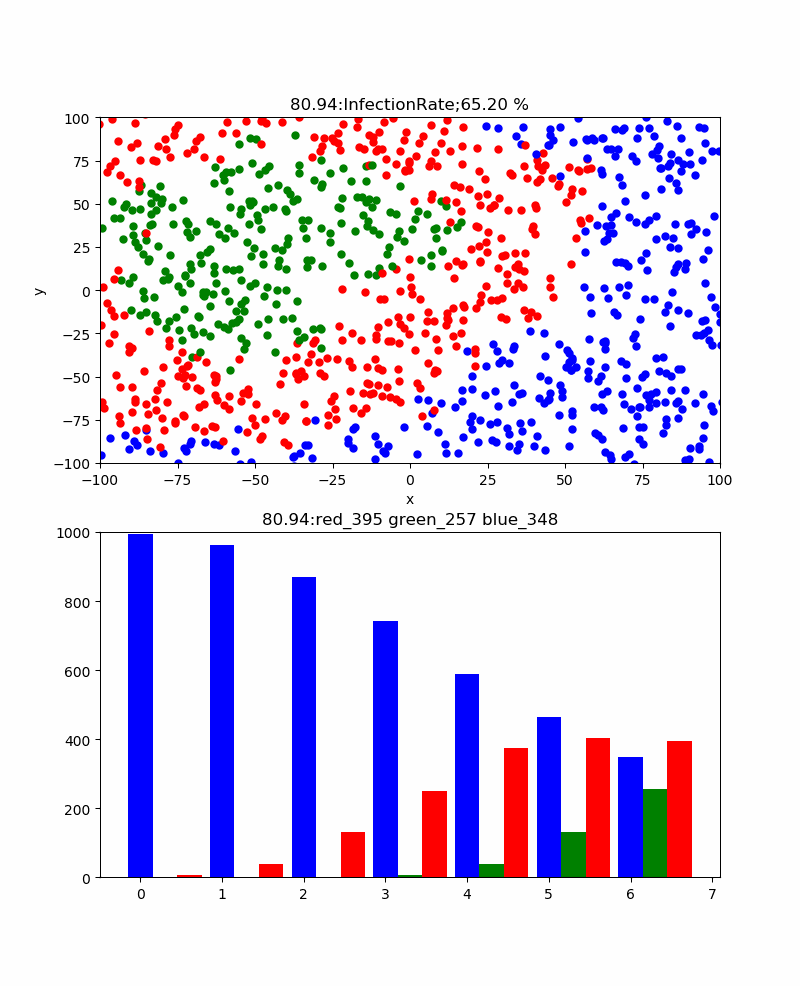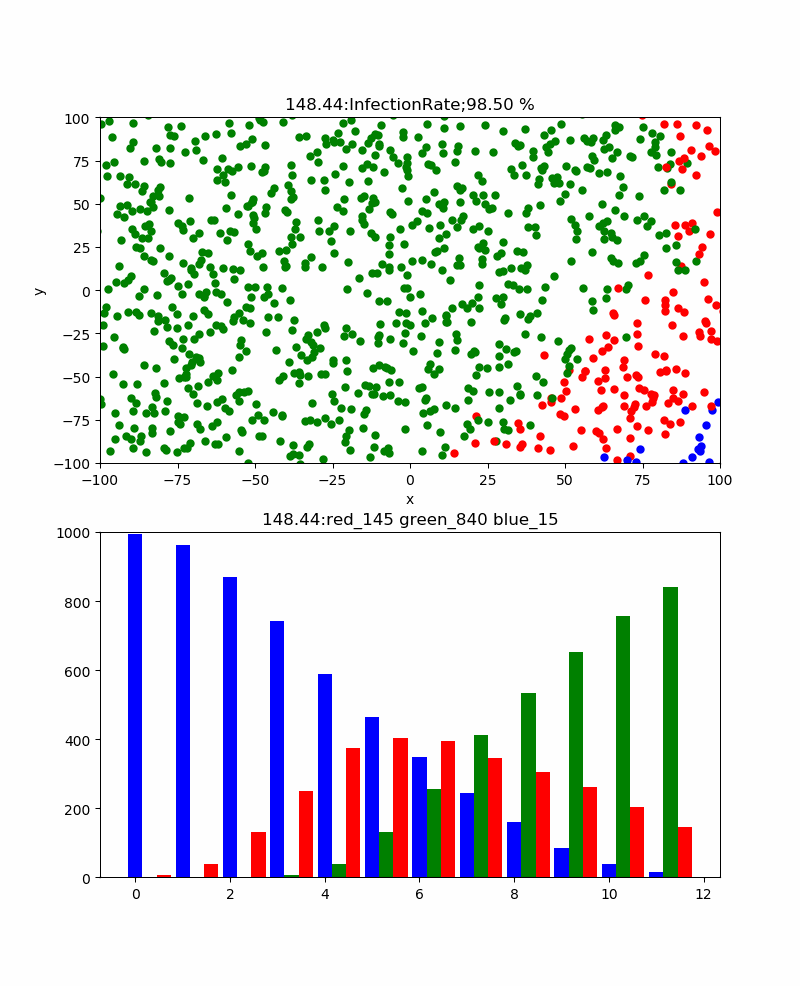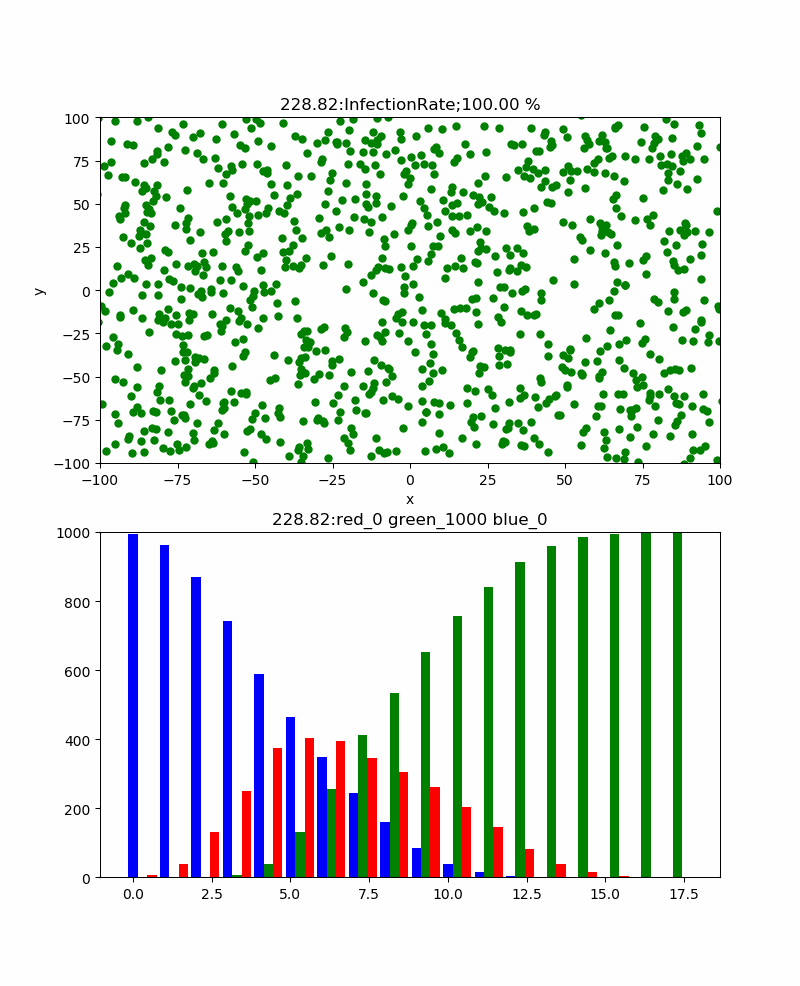 Autrement dit, le graphique à barres rouge montre le nombre d'infections et le graphique à barres vertes montre le nombre de traitements, mais il est difficile de prédire combien le nombre d'infections augmentera, mais le nombre de traitements est limité au nombre d'infections, donc au moins les infections Il ne dépasse pas le nombre. De plus, lorsqu'il est exprimé en termes de taux de guérison, il est proche de 100% à la fin. De plus, le taux de guérison atteint toujours son maximum après le pic d'infection. À première vue, il semble que le nombre d'infections qui culminent en premier soit plus facile à déterminer la fin, mais il n'est pas clair si ce pic est nécessairement la limite supérieure.
En revanche, le nombre de cures culmine autour de 50% et devrait progressivement se rapprocher de cette valeur.
En d'autres termes, si vous suivez cette valeur, il semble que l'heure de fin sera à peu près visible.
En regardant le graphique ci-dessus avec la conviction que l'infection est en train de se saturer dès le début de la guérison.
Cette fois, voyons d'abord si les données réelles se comportent de la même manière.
【référence】
・ Visualisez le nombre de personnes infectées par le virus corona avec matplotlib
Autrement dit, le graphique à barres rouge montre le nombre d'infections et le graphique à barres vertes montre le nombre de traitements, mais il est difficile de prédire combien le nombre d'infections augmentera, mais le nombre de traitements est limité au nombre d'infections, donc au moins les infections Il ne dépasse pas le nombre. De plus, lorsqu'il est exprimé en termes de taux de guérison, il est proche de 100% à la fin. De plus, le taux de guérison atteint toujours son maximum après le pic d'infection. À première vue, il semble que le nombre d'infections qui culminent en premier soit plus facile à déterminer la fin, mais il n'est pas clair si ce pic est nécessairement la limite supérieure.
En revanche, le nombre de cures culmine autour de 50% et devrait progressivement se rapprocher de cette valeur.
En d'autres termes, si vous suivez cette valeur, il semble que l'heure de fin sera à peu près visible.
En regardant le graphique ci-dessus avec la conviction que l'infection est en train de se saturer dès le début de la guérison.
Cette fois, voyons d'abord si les données réelles se comportent de la même manière.
【référence】
・ Visualisez le nombre de personnes infectées par le virus corona avec matplotlib
Ce que j'ai fait
・ Explication du code ・ Visualisez le nombre de personnes infectées dans chaque pays
・ Explication du code
Le code est ci-dessous. ・ Collective_particles / draw_covid19.py
Cette fois, il s'agit d'une méthode de visualisation de plusieurs données. Pour visualiser les données d'infection, obtenez au moins 3 données à partir des sites suivants. Par souci de simplicité, j'ai téléchargé le fichier zip à partir du site de référence suivant et l'ai développé. (Le lien ci-dessous est la page de lien du fichier. Nous vous recommandons de télécharger par lots à partir de la référence ci-dessous) time_series_19-covid-Confirmed.csv time_series_19-covid-Deaths.csv time_series_19-covid-Recovered.csv 【référence】 ・ CSSEGISandData / COVID-19 Nous traiterons ces données de manière appropriée et dessinerons un graphique similaire à celui ci-dessus. Le processus jusqu'au dessin graphique est expliqué ci-dessous. Tout d'abord, utilisez le fichier Lib. Ici, l'environnement utilise également Jetson-nano cette fois, mais pandas vient d'être installé. Quant à la référence, j'ai eu une erreur si c'était simple, alors je l'ai finalement saisie avec la commande suivante.
sudo apt-get install python-pandas
sudo apt-get install python3-pandas
Le code suivant fonctionnait sur python, mais l'importation de pandas ne fonctionnait pas sur python3.
- Cela semble fonctionner comme suit? ??
$ python3
Python 3.6.9 (default, Nov 7 2019, 10:44:02)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>>
【référence】 ・ Comment installer Pandas en 3 minutes sans utiliser pip
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Ensuite, lisez les trois fichiers csv comme suit.
#Lisez les données CSV avec les pandas.
data = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
data_r = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
data_d = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
Définissez la variable. Les données à lire ont la structure suivante, donc les quatre premières sont exclues.
| Province/State | Country/Region | Lat | Long | 1/22/20 | 1/23/20 | 1/24/20 | 1/25/20 |
|---|---|---|---|---|---|---|---|
| Thailand | 15 | 101 | 2 | 3 | 5 | 7 | |
| Japan | 36 | 138 | 2 | 1 | 2 | 2 | |
| New South Wales | Australia | -33.8688 | 151.2093 | 0 | 0 | 0 | 0 |
La date a été remplacée par le nombre de jours. .. .. De l'article de référence ci-dessus
confirmed = [0] * (len(data.columns) - 4)
confirmed_r = [0] * (len(data_r.columns) - 4)
confirmed_d = [0] * (len(data_d.columns) - 4)
recovered_rate = [0] * (len(data_r.columns) - 4)
deaths_rate = [0] * (len(data_d.columns) - 4)
days_from_22_Jan_20 = np.arange(0, len(data.columns) - 4, 1)
Cette fois, jetons un coup d'œil aux données de Wuhan.
city = "Hubei"
Les premières variables ci-dessous sont fournies pour stocker le nombre total de cas, le nombre total de guérisons et le nombre total de décès pour l'affichage du titre. Comme vous pouvez le voir à partir des données ci-dessus, il est aligné avec les États et les pays, donc pour importer les données de Wuhan, utilisez ʻif (data.iloc [i] [0] == city): `. Le pays utilise le commenté. Stockez les nombres quotidiens dans confirmé, confirmé_r et confirmé_d. Étant donné que les données sur le nombre de cas sont une valeur cumulative, le nombre de cas de guérison ce jour-là est soustrait et remplacé par le nombre d'infections ce jour-là. Le calcul + = est utilisé pour obtenir la valeur totale des régions dans le même pays mais dans des régions différentes.
#Données de processus
t_cases = 0
t_recover = 0
t_deaths = 0
for i in range(0, len(data), 1):
#if (data.iloc[i][1] == city): #for country/region
if (data.iloc[i][0] == city): #for province:/state
print(str(data.iloc[i][0]) + " of " + data.iloc[i][1])
for day in range(4, len(data.columns), 1):
confirmed[day - 4] += data.iloc[i][day] - data_r.iloc[i][day]
confirmed_r[day - 4] += data_r.iloc[i][day]
confirmed_d[day - 4] += data_d.iloc[i][day]
t_recover += data_r.iloc[i][day]
t_deaths += data_d.iloc[i][day]
Cette fois, je veux voir la fin de ce qui précède, donc je calcule le taux de guérison. Nous calculons également le taux de mortalité préoccupant.
tl_confirmed = 0
for i in range(0, len(confirmed), 1):
tl_confirmed = confirmed[i] + confirmed_r[i] + confirmed_d[i]
if tl_confirmed > 0:
recovered_rate[i]=float(confirmed_r[i]*100)/float(tl_confirmed)
deaths_rate[i]=float(confirmed_d[i]*100)/float(tl_confirmed)
else:
continue
t_cases = tl_confirmed
Il est représenté ci-dessous. Cette fois, plusieurs graphiques peuvent être affichés ensemble.
- Cet article semble être plus polyvalent et agréable. Pour référence, je pense que le code suivant est facile à comprendre. 【référence】 ・ Axe secondaire avec twinx (): comment ajouter à la légende?
#dessin matplotlib
fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2))
ax3 = ax1.twinx()
ax4 = ax2.twinx()
lns1=ax1.plot(days_from_22_Jan_20, confirmed, "o-", color="red",label = "cases")
lns2=ax1.plot(days_from_22_Jan_20, confirmed_r, "*-", color="green",label = "recovered")
lns3=ax3.plot(days_from_22_Jan_20, confirmed_d, "D-", color="black", label = "deaths")
lns4=ax2.plot(days_from_22_Jan_20, recovered_rate, "*-", color="green",label = "recovered")
lns5=ax4.plot(days_from_22_Jan_20, deaths_rate, "D-", color="black", label = "deaths")
lns_ax1 = lns1+lns2+lns3
labs_ax1 = [l.get_label() for l in lns_ax1]
ax1.legend(lns_ax1, labs_ax1, loc=0)
lns_ax2 = lns4+lns5
labs_ax2 = [l.get_label() for l in lns_ax2]
ax2.legend(lns_ax2, labs_ax2, loc=0)
ax1.set_title(city +" ; {} cases, {} recovered, {} deaths".format(t_cases,t_recover,t_deaths))
ax1.set_xlabel("days from 22, Jan, 2020")
ax1.set_ylabel("casas, recovered ")
ax2.set_ylabel("recovered_rate %")
ax2.set_ylim(0,100)
ax3.set_ylabel("deaths ")
ax4.set_ylabel("deaths_rate %")
ax4.set_ylim(0,10)
ax1.grid()
ax2.grid()
plt.pause(1)
plt.savefig('./fig/fig_{}_.png'.format(city))
plt.close()
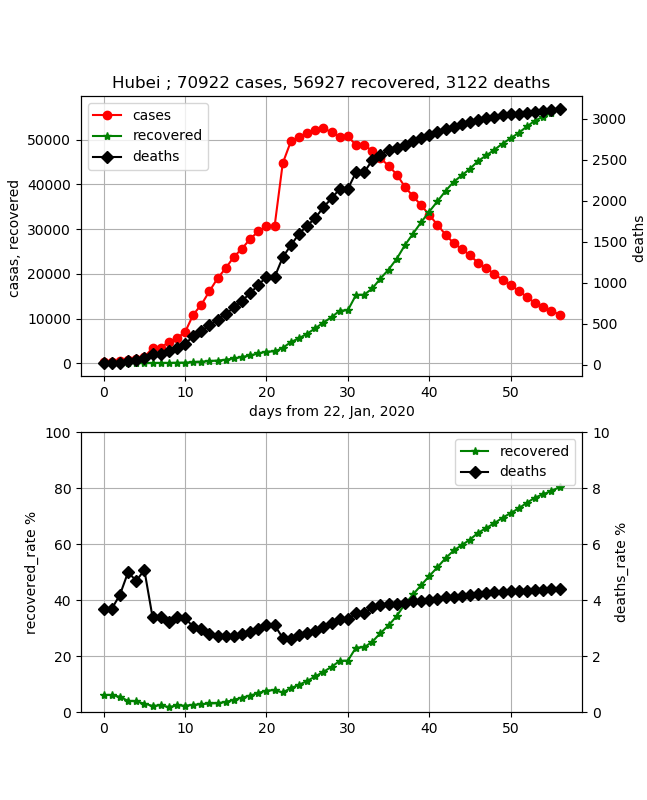
Ces données sont de très bonnes données à comparer avec la simulation. Malheureusement, la partie qui a changé la méthode de comptage semble grande. A partir de ces données, si cela peut être reproduit par simulation, il sera possible de simuler la transmission de l'infection à Wuhan cette fois. Et si vous regardez le taux de guérison, vous pouvez voir que 50% est le pic de cette transmission de l'infection, et on peut prédire qu'elle se terminera dans environ le même nombre de jours par la suite. En d'autres termes, il culmine environ 40 jours après le début de l'infection, et maintenant, environ 20 jours après, il est susceptible de se terminer dans environ 20 jours. De plus, le taux de mortalité augmente progressivement, et il semble être d'environ 4,5%. Cela n'augmente pas le nombre de personnes nouvellement infectées, mais je pense que c'est inévitable car les décès continueront jusqu'à la dernière nuit.
- J'espère que des procédures médicales seront mises en place et que les gens ne mourront pas progressivement.
・ Visualisez le nombre de personnes infectées dans chaque pays
Sortons la situation du pays qui vous tient à cœur Ci-dessous, j'ai écrit divers commentaires, mais je ne suis pas sûr car c'est juste une impression d'Uwan amateur regardant le graphique.
·Corée
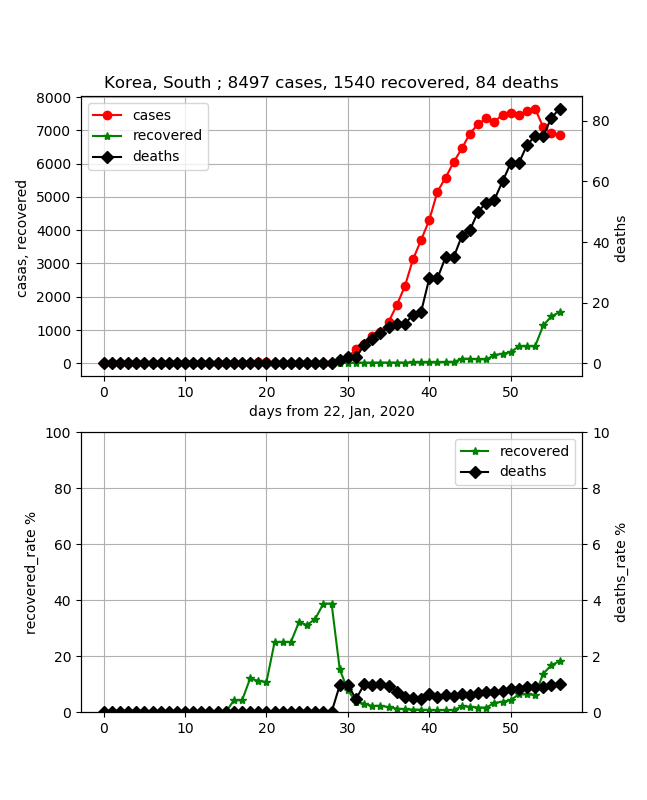 Le taux de mortalité peut être faible. Cependant, j'ai entendu dire qu'elle était terminée, et bien que le nombre d'infections semble avoir atteint son apogée, le taux de guérison est toujours inférieur à 20%, et j'ai l'impression que c'est imprévisible. Il faut simplement environ 30 jours pour atteindre 50%, et il semble que cela ne se terminera qu'environ 50 jours après cela.
Le taux de mortalité peut être faible. Cependant, j'ai entendu dire qu'elle était terminée, et bien que le nombre d'infections semble avoir atteint son apogée, le taux de guérison est toujours inférieur à 20%, et j'ai l'impression que c'est imprévisible. Il faut simplement environ 30 jours pour atteindre 50%, et il semble que cela ne se terminera qu'environ 50 jours après cela.
- Nous prévoyons de créer une application capable d'évaluer cela un peu plus quantitativement.
·Italie
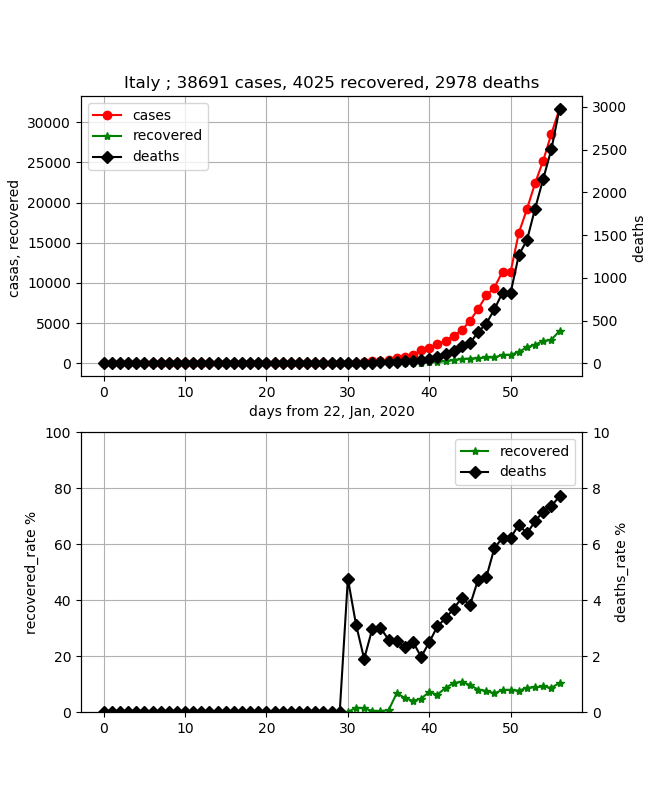 J'étais inquiet de l'effondrement des soins médicaux, mais j'étais soulagé que les données soient solides.
En d'autres termes, je sens que le pays est aux commandes. Cependant, la caractéristique est que le taux de mortalité est en constante augmentation et atteint récemment environ 8%. De plus, le taux de guérison est d'environ 10%, et le nombre d'infections est d'environ 40 000, mais il est en pleine augmentation et il n'y a aucune perspective de fin.
J'étais inquiet de l'effondrement des soins médicaux, mais j'étais soulagé que les données soient solides.
En d'autres termes, je sens que le pays est aux commandes. Cependant, la caractéristique est que le taux de mortalité est en constante augmentation et atteint récemment environ 8%. De plus, le taux de guérison est d'environ 10%, et le nombre d'infections est d'environ 40 000, mais il est en pleine augmentation et il n'y a aucune perspective de fin.
· Iran
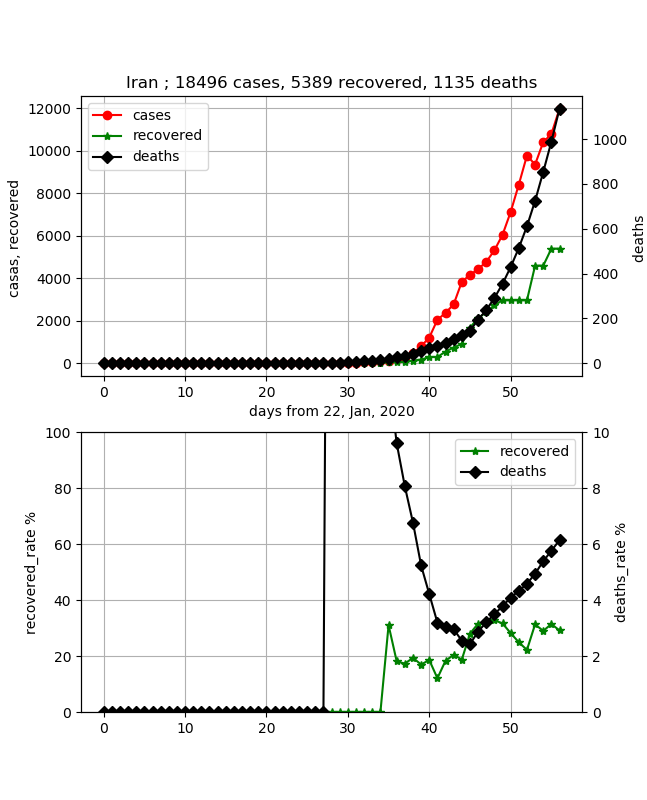 C'est un pays inquiétant avec l'Italie. Après tout, le taux de mortalité était une valeur anormale, mais quand je suis arrivé ici, il a encore fortement augmenté et dépassé 6%. Cependant, comme le taux de guérison a atteint environ 30%, le nombre maximal d'infections pourrait survenir bientôt. L'augmentation du taux de guérison est lente, mais si le nombre maximal de traitements peut être prédit à partir de cela, il sera possible d'atteindre le confinement.
Puisque les données sont solides, il semble que l'effondrement médical soit acceptable.
C'est un pays inquiétant avec l'Italie. Après tout, le taux de mortalité était une valeur anormale, mais quand je suis arrivé ici, il a encore fortement augmenté et dépassé 6%. Cependant, comme le taux de guérison a atteint environ 30%, le nombre maximal d'infections pourrait survenir bientôt. L'augmentation du taux de guérison est lente, mais si le nombre maximal de traitements peut être prédit à partir de cela, il sera possible d'atteindre le confinement.
Puisque les données sont solides, il semble que l'effondrement médical soit acceptable.
・ France / Allemagne / Amérique
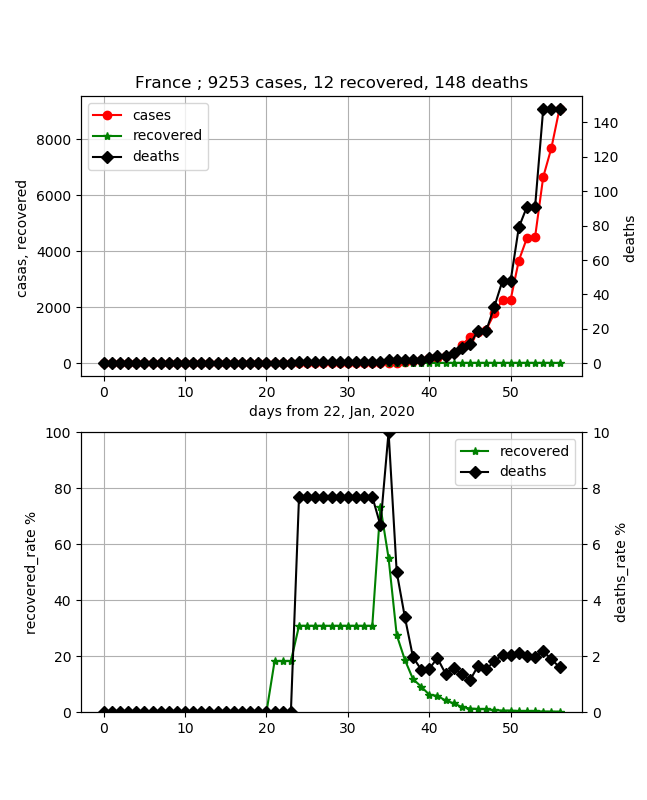
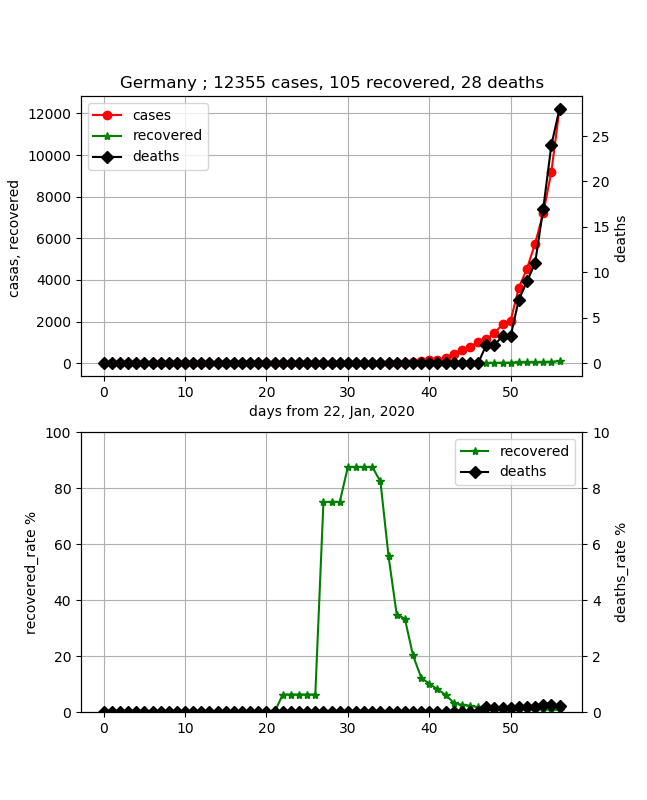 Montré ensemble. Ces deux pays sont également préoccupants. En effet, le nombre de cas a augmenté dans les deux cas, mais la guérison est presque nulle. Une infection soudaine est prévue, et j'imagine que cela ne s'arrêtera pas pour le moment.
Le taux de mortalité est faible à 2% en France, mais il est proche de 0 en Allemagne avec moins de 30 personnes. Cela fait moins de 20 jours que j'ai été infecté, alors je peux imaginer qu'il y a beaucoup de gens qui combattent la maladie, mais j'aimerais voir la transition.
Les États-Unis sont également un pays où le nombre d'infections augmente rapidement.
Montré ensemble. Ces deux pays sont également préoccupants. En effet, le nombre de cas a augmenté dans les deux cas, mais la guérison est presque nulle. Une infection soudaine est prévue, et j'imagine que cela ne s'arrêtera pas pour le moment.
Le taux de mortalité est faible à 2% en France, mais il est proche de 0 en Allemagne avec moins de 30 personnes. Cela fait moins de 20 jours que j'ai été infecté, alors je peux imaginer qu'il y a beaucoup de gens qui combattent la maladie, mais j'aimerais voir la transition.
Les États-Unis sont également un pays où le nombre d'infections augmente rapidement.
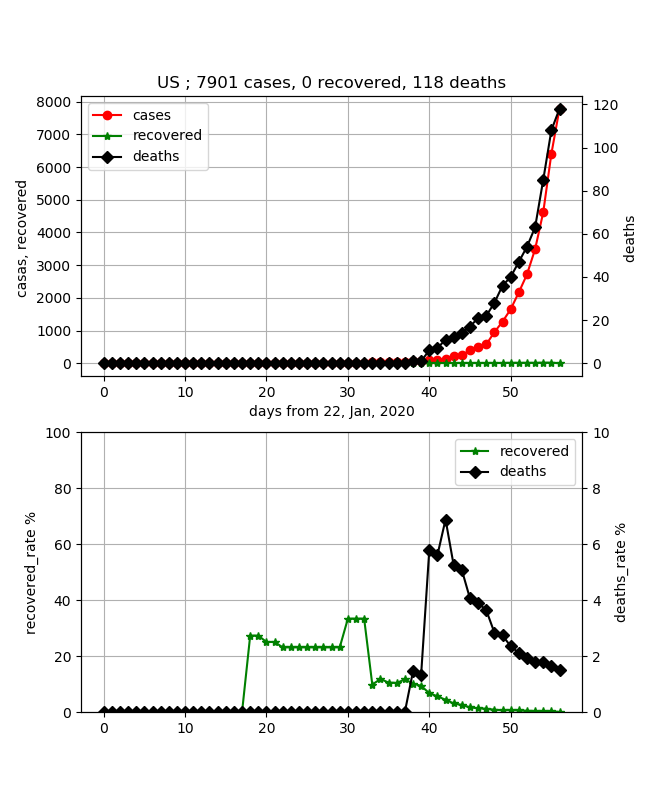 Aux États-Unis également, le nombre de remèdes est de 0 et le taux de mortalité est maintenu bas à 2% ou moins, mais c'est aussi environ 20 jours après l'augmentation du nombre d'infections, alors j'aimerais voir la transition.
Aux États-Unis également, le nombre de remèdes est de 0 et le taux de mortalité est maintenu bas à 2% ou moins, mais c'est aussi environ 20 jours après l'augmentation du nombre d'infections, alors j'aimerais voir la transition.
·Espagne
L'Espagne est également l'un des pays inquiets. C'est comme suit.
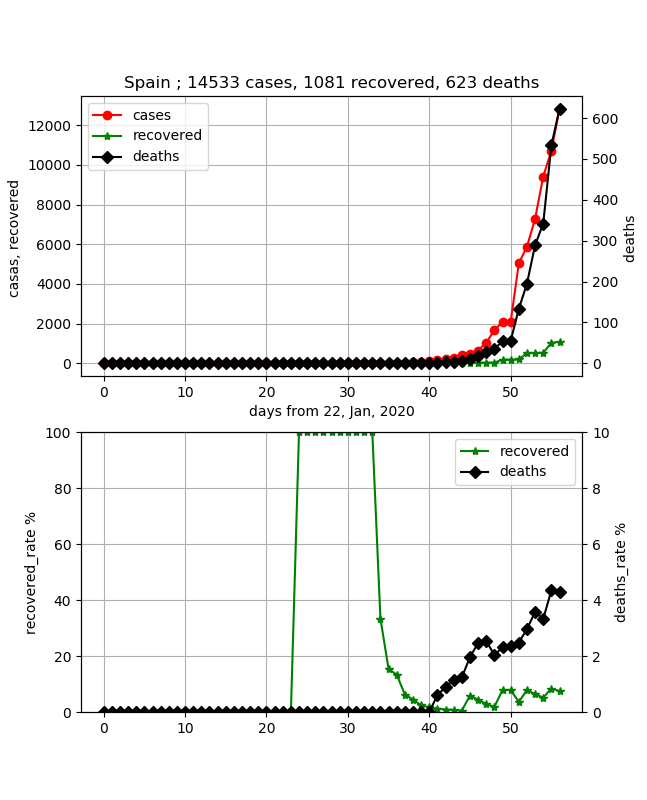 Les données semblent solides et contrôlées. Cependant, le taux de mortalité augmente ici aussi et a récemment dépassé 4%. Si l'on regarde le taux de guérison, il est inférieur à 10% et le nombre d'infections est d'environ 15 000, mais on peut voir qu'il n'en est qu'à ses débuts. Je souhaite garder un œil sur les tendances futures.
Les données semblent solides et contrôlées. Cependant, le taux de mortalité augmente ici aussi et a récemment dépassé 4%. Si l'on regarde le taux de guérison, il est inférieur à 10% et le nombre d'infections est d'environ 15 000, mais on peut voir qu'il n'en est qu'à ses débuts. Je souhaite garder un œil sur les tendances futures.
·Japon
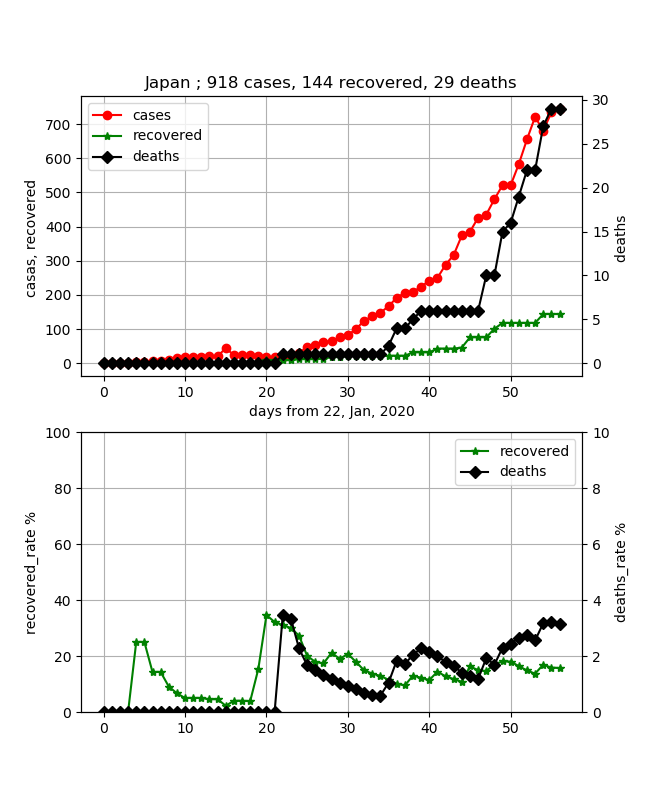 Je pense que le Japon est le pays où l'infection se propage le plus lentement.
Dans un sens, j'ai l'impression que c'est à la fois polaire et chinois.
Le taux de mortalité a également été maintenu bas, mais il semble qu'il s'approche progressivement de 4%. De plus, le taux de guérison a augmenté à environ 18% maintenant, mais comme il n'augmente que très lentement, je pense que ni le pic d'infection ni le pic du taux de guérison ne peuvent encore être observés. Je pense qu'il sera visible s'il continue d'augmenter pendant environ 30 jours. Cependant, l'augmentation du nombre d'infections est une courbe convexe vers le bas, ce qui peut conduire à une augmentation rapide, donc je pense que c'est imprévisible.
Je pense que le Japon est le pays où l'infection se propage le plus lentement.
Dans un sens, j'ai l'impression que c'est à la fois polaire et chinois.
Le taux de mortalité a également été maintenu bas, mais il semble qu'il s'approche progressivement de 4%. De plus, le taux de guérison a augmenté à environ 18% maintenant, mais comme il n'augmente que très lentement, je pense que ni le pic d'infection ni le pic du taux de guérison ne peuvent encore être observés. Je pense qu'il sera visible s'il continue d'augmenter pendant environ 30 jours. Cependant, l'augmentation du nombre d'infections est une courbe convexe vers le bas, ce qui peut conduire à une augmentation rapide, donc je pense que c'est imprévisible.
Résumé
・ J'ai essayé de tracer des données COVID-19 ・ Plusieurs graphiques peuvent être liés et générés ・ Évalué ce qui peut être vu de la simulation avec des données réelles
・ Prolongez la simulation pour pouvoir prédire la fin ・ Je souhaite créer une application qui catégorise la situation dans chaque pays.
Recommended Posts