[PYTHON] Catégoriser les images de chats à l'aide de ChainerCV
<! - Classer les images de chats avec chainercv -->
Aperçu
Environ 2000 images de chats collectées sur le site de publication d'images Pixabay sont collectées à l'aide de la bibliothèque d'apprentissage automatique ChainerCV. J'ai essayé de classer.
pixabay est un site qui collecte et publie des images et des vidéos avec une licence assez lâche appelée ~~ CC0 (domaine public) ~~ Licence Pixabay. Dans les images collectées en spécifiant «chat» comme terme de recherche, certaines images autres que les chats sont en fait mélangées. En fin de compte, je pense qu'il sera nécessaire de classer manuellement, mais le but de cet article est d'abord de séparer les fichiers en utilisant un modèle de classification formé existant pour le prétraitement.
ChainerCV
Les modèles formés de VGGNet sont largement distribués et plusieurs méthodes les appliquent. Lorsque je cherchais une boîte à outils pour la classification d'images en l'utilisant, je suis arrivé à ChainerCV: une bibliothèque pour la vision par ordinateur en apprentissage profond. Prend en charge la détection d'objets et la segmentation sémantique.
J'ai écrit le code pour classer les fichiers en utilisant ceci. Il est basé sur le contenu de l'échantillon.
code
#!/usr/nogpu/bin/python
# -*- coding: utf-8 -*-
import argparse
import chainer
from chainercv.datasets import voc_detection_label_names
from chainercv.links import SSD300
from chainercv import utils
import os
def main():
chainer.config.train = False
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=-1)
parser.add_argument('--pretrained_model', default='voc0712')
parser.add_argument('src_dir')
parser.add_argument('dst_dir')
args = parser.parse_args()
model = SSD300(
n_fg_class=len(voc_detection_label_names),
pretrained_model=args.pretrained_model)
if args.gpu >= 0:
model.to_gpu(args.gpu)
chainer.cuda.get_device(args.gpu).use()
file_lists = []
for f in os.listdir(args.src_dir):
if not f.startswith("."):
file_lists.append(f)
if not os.path.exists(args.dst_dir):
os.mkdir(args.dst_dir)
cat_id = voc_detection_label_names.index('cat') #Obtenir un index équivalent à cat
def has_cat(labels):
for l in labels:
if type(l) == int:
if l == cat_id:
return True
for ll in l: #les étiquettes peuvent renvoyer un tableau de tableaux
if ll == cat_id:
return True
return False
print("target file: %d files" % len(file_lists))
count = 0
for f in file_lists:
fname = os.path.join(args.src_dir, f)
img = utils.read_image(fname, color=True)
bboxes, labels, scores = model.predict([img])
if has_cat(labels):
dst_fname = os.path.join(args.dst_dir, f)
os.rename(fname, dst_fname)
count += 1
print("%d: move from %s to %s" % (count, fname, dst_fname))
print("%d files moved." % count)
if __name__ == '__main__':
main()
Commentaire
Il existe différentes méthodes prises en charge par ChainerCV, mais lorsque je l'ai essayé avec Faster-RCNN et le détecteur multibox à un coup (Wei Liu, et al. "SSD: détecteur multibox à coup unique" ECCV 2016.), le SSD C'était plus rapide, donc je l'ai utilisé pour écrire le code.
Il téléchargera automatiquement le modèle de pré-formation lorsque vous créez une instance de classe SSD300. Cette fois, j'ai choisi "voc0712" qui est le même que la démo par défaut attachée à Chainer CV. Ce processus de téléchargement est effectué uniquement la première fois qu'il est exécuté et est enregistré sous le nom de fichier $ HOME / .chainer / dataset / pfnet / chainercv / models / ssd300_voc0712_2017_06_06.npz. Ce modèle prend en charge 20 types de classification. Ce modèle est compatible avec Le PASCAL Visual Object Classes Challenge 2012 (VOC2012).
$ python
>>> from chainercv.datasets import voc_detection_label_names
>>> voc_detection_label_names
('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')
précision
Cela n'a pas l'air mal à première vue. Les fichiers à traiter incluent des chats autres que des chats (lions, léopards, etc.), mais comme ils ne sont pas soumis à VOC2012, des chats et des chiens qui semblent avoir des caractéristiques relativement similaires Il semble qu'il soit souvent classé comme.
À partir des résultats classés comme chats, nous avons sélectionné ceux qui ne sont clairement pas des chats. Les résultats sont montrés plus bas.
| Fichier d'image | Classé comme un chat | Classé comme autre que chat |
|---|---|---|
| Le chat est sur la photo | 1635 | 70 |
| Le chat n'est pas sur la photo | 7 | 337 |
- Nombre total d'images: 2049
- faux négatif 7 feuilles
- faux positif 70 feuilles
- precision: 0.9957
- recall: 0.9589
La précision semble être suffisamment élevée, mais par rapport à l'environnement où la précision de classification serait généralement évaluée étant donné que la majorité des sujets sont des images de chat (images moyennement comparables pour chaque étiquette). Ce n'est peut-être pas un peu juste à faire.
Cas d'erreur de jugement
Regardons quelques cas d'échec.
Même s'il ressemble à un chat, il est jugé comme un chien
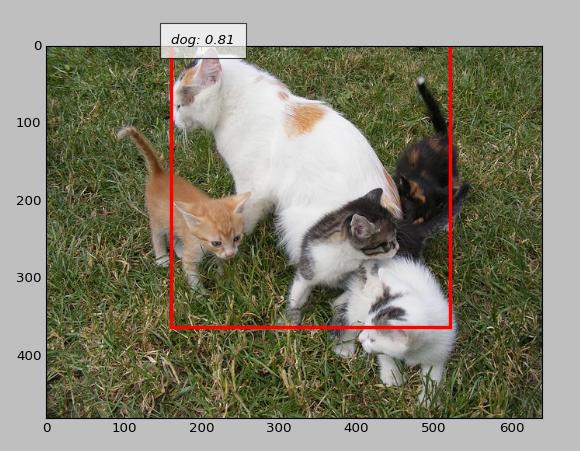
L'objet au premier plan gêne-t-il?


Êtes-vous entraîné vers le jugement de fond?
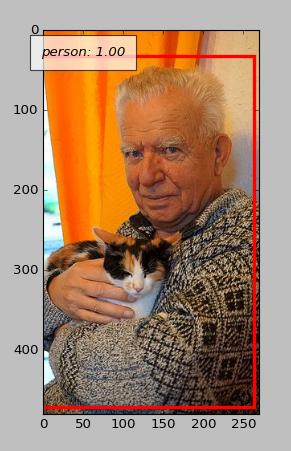
Le contraste n'est pas bon
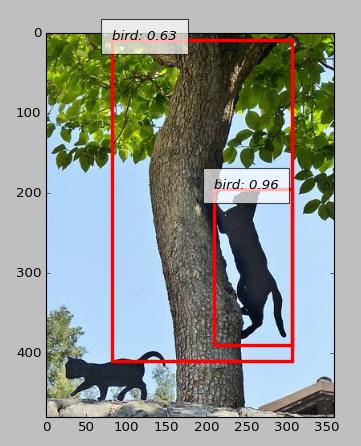
Juste du fil

Statues et animaux en peluche

Le cas où le classement est correct mais je voulais que tu joues
Celui sur la photo est un chat (ou quelque chose qui ressemble à ça), et voici des exemples de cas où les chats sont également classés comme des chats.
- L'avant-pied du chat est relevé
- Face vers le haut
- Seulement autour des yeux
- Seulement autour de la bouche
- Seulement la queue
- Poupée en peluche
- Image traitée de la photo
- Image photoréaliste
- Image modérément déformée
- Par la porte du filet
- Image floue
- Image monochrome
Il y a certains comportements qui sont corrects dans un sens, il semble donc que ces choses ne peuvent être classées qu'à la main.
Dépôt de reproduction
La liste d'URL que j'ai utilisée pour collecter des images est disponible sur github. Si vous préparez des données d'image en fonction de ces informations, vous pouvez reproduire ce que vous avez fait dans cet article.
- https://github.com/knok/pixabay-cat-images
à partir de maintenant
Étant donné que la zone reconnue peut également être obtenue, je pense que ce serait bien de pouvoir effectuer des traitements tels que la lecture d'images en dessous d'un certain pourcentage. Nous prévoyons d'utiliser ce résultat pour pix2pix (article précédent).
Ajouté à propos du changement de licence de PIXTA
Je ne connais pas la date exacte, mais Pixabay a abandonné la licence CC0 et ajouté quelques restrictions. Pour autant que je l'ai confirmé avec Wayback Machine, j'ai ajouté une limite vers juillet 2017 est. C'est une assez bonne licence pour les données de formation en machine learning, mais gardez à l'esprit qu'il ne s'agit plus de CC0.
Recommended Posts