[PYTHON] [Renforcer l'apprentissage] Enquête sur l'utilisation de la bibliothèque Experience Replay de DeepMind Reverb [Client Edition]
Réimpression en japonais de article de blog publiée en anglais
1.Tout d'abord
Suite de Dernière fois, à propos de Reberb de la bibliothèque Experience Replay de DeepMind. Cette fois, en lisant le code source, j'ai étudié la partie non écrite dans le README côté client qui instruit l'opération d'entrée / sortie de données.
2. Client et TFClient
Reverb utilise un modèle serveur-client, mais il existe deux classes côté client, reverb.Client et reverb.TFClient.
On dit que «Client» est pour les premiers stades de développement, et «TFClient» est utilisé dans le programme d'apprentissage proprement dit. La grande différence est que TFClient, comme son nom l'indique, est destiné à être utilisé dans le graphe de calcul de TensorFlow.
L'une des motivations pour écrire cet article organisé était que les API et l'utilisation des deux étaient incohérentes et compliquées.
L'article suivant suppose que les programmes serveur et client ont été initialisés comme suit:
import numpy as np
import tensorflow as tf
import reverb
table_name = "ReplayBuffer"
alpha = 0.8
buffer_size = 1000
batch_size = 32
server = reverb.Server(tables=[reverb.Table(name=table_name,
sampler=reverb.selectors.Prioritized(alpha),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1))])
client = reverb.Client(f"localhost:{server.port}")
tf_client = reverb.TFClient(f"localhost:{server.port}")
obs = np.zeros((4,))
act = np.ones((1,))
rew = np.ones((1,))
next_obs = np.zeros_like(obs)
done = np.zeros((1,))
priority = 1.0
dtypes = [tf.float64,tf.float64,tf.float64,tf.float64,tf.float64]
shapes = [4,1,1,4,1]
3. Préservation de la transition ou de la trajectoire
3.1 Client.insert
client.insert([obs,act,rew,next_obs,done],priorities={table_name: priority})
L'argument priority est dict car les mêmes données peuvent être enregistrées dans plusieurs tables (tampons de relecture) en même temps avec des priorités différentes. (Je ne savais pas qu'il y avait un tel besoin)
Vous devez spécifier la priorité, même pour les tampons de relecture normaux non prioritaires.
Client.insert envoie des données au serveur chaque fois qu'il est appelé
3.2 Client.writer
with client.writer(max_sequence_length=3) as writer:
writer.append([obs,act,rew,next_obs,done])
writer.create_item(table_name,num_timesteps=1,priority=priority)
writer.append([obs,act,rew,next_obs,done])
writer.append([obs,act,rew,next_obs,done])
writer.append([obs,act,rew,next_obs,done])
writer.create_item(table_name,num_timesteps=3,priority=priority) #Enregistrez 3 étapes comme 1 élément.
#Envoyer au serveur lors de la sortie avec blocage
En utilisant reverb.Writer renvoyé par la méthode Client.writer comme gestionnaire de contexte,
Vous pouvez définir le contenu à enregistrer de manière plus flexible.
Par exemple, la première moitié de l'exemple de code ci-dessus enregistre le même contenu que 3.1, mais la seconde moitié enregistre les trois étapes ensemble en un seul élément. En d'autres termes, lors de l'échantillonnage, vous pouvez échantillonner les trois comme un seul. Par exemple, on peut supposer qu'il est utilisé lorsque vous souhaitez échantillonner chaque épisode.
Les données sont envoyées au serveur lorsque Writer.flush () ou Writer.close () est appelé (il est également appelé automatiquement en quittant le bloc with).
3.3 TFClient.insert
tf_client.inser([tf.constant(obs),
tf.constant(act),
tf.constant(rew),
tf.constant(next_obs),
tf.constant(done)],
tablea=tf.constant([table_name]),
priorities=tf.constant([priority],dtype=tf.float64))
L'argument «tables» est le «str» rang 1 «tf.Tensor», et les «priorités» est le «float64» (sauf si spécifié est «float32») rang 1 «tf.Tensor». Les deux formes doivent correspondre.
Il est probablement nécessaire de conserver le «tf.Tensor» de chaque donnée au rang 1 ou plus pour un échantillonnage ultérieur.
3.4 Résumé
| Envoyer au serveur | Plusieurs étapes en un seul élément | Utilisation dans le graphique de calcul TF | Les données | |
|---|---|---|---|---|
Client.insert |
À chaque fois | X | X | tout va bien |
Client.writer |
Writer.close(), Writer.flush() (ComprenantwithEn sortant) |
O | X | tout va bien |
TFClient.insert |
À chaque fois | X | O | tf.Tensor |
4. Lire une transition ou une trajectoire
Aucune des deux méthodes ne correspond au paramètre β de correction du poids dans la relecture d'expérience prioritaire. (Il ne calcule pas le poids de l'échantillonnage prioritaire en premier lieu)
4.1 Client.sample
client.sample(table_name,num_samples=batch_size)
La valeur de retour est le générateur de reverb.replay_sample.ReplaySample. ReplaySample est un tuple nommé et possède ʻinfo et data. Data contient les données sauvegardées et ʻinfo contient des informations telles que la clé et la priorité.
4.2 TFClient.sample
tf_client.sample(tf.constant([table_name]),data_dtypes=dtypes)
Malheureusement, cette méthode ne prend pas en charge l'échantillonnage par lots. La valeur de retour sera «ReplaySample».
4.3 TFClient.dataset
tf_client.dataset(tf.constant([table_name]),dtypes=dtypes,shapes=shapes)
Elle adopte une méthode complètement différente des autres méthodes, et il semble qu'elle vise principalement à adopter cette méthode dans l'apprentissage de la production à grande échelle.
La valeur de retour de cette fonction est «reverb.ReplayDataset», qui hérite de «tf.data.Dataset». Ce ReplayDataset peut extraire ReplaySample comme le générateur, et récupère automatiquement les données du serveur au bon moment. En d'autres termes, au lieu de «sample» à chaque fois, une fois que vous avez défini «ReplayDataset», il continuera à éjecter les données enregistrées automatiquement.
Étant donné que «shape» provoque une erreur lorsque «0» est spécifié comme élément, il semble nécessaire de sauvegarder les données au rang 1 ou supérieur.
D'autres paramètres pour l'ajustement des performances sont détaillés à écrire ici, alors vérifiez le Commentaire dans le code source. Je te veux.
4.4 Résumé
| Sortie par lots | Type de retour | Spécification de type | Désignation de forme | |
|---|---|---|---|---|
Client.sample |
O | replay_sample.ReplaySampledegenerator |
Inutile | Inutile |
TFClient.sample |
X | replay_sample.ReplaySample |
nécessaire | Inutile |
TFClient.dataset |
O (Implémenté automatiquement en interne) | ReplayDataset |
nécessaire | nécessaire |
5. Mise à jour de la priorité
Contrairement à d'autres implémentations de tampon de relecture, l'ID qui spécifie l'élément n'est pas un numéro de série commençant par «0», mais un hachage apparemment aléatoire. Il est accessible avec ReplaySample.info.key.
(Comme il est difficile d'écrire, je vais omettre une partie de l'exemple de code. Désolé.)
5.1 Client.mutate_priorities
client.mutate_priorities(table_name,updates={key:new_priority},deletes=[...])
Cela peut être supprimé ou mis à jour.
5.2 TFClient.update_priorities
tf_client.update_priorities(tf.constant([table_name]),
keys=tf.constant([...]),
priorities=tf.constant([...],dtype=tf.float64))
6. Comparaison des performances
Comme c'est un gros problème, j'ai pris un benchmark incluant mon travail cpprb.
** Remarque: l'apprentissage par renforcement n'est pas uniquement déterminé par la vitesse du tampon de relecture, car il existe d'autres processus lourds tels que l'apprentissage en profondeur et la mise à jour de l'environnement. (D'un autre côté, en fonction de l'implémentation et des conditions du tampon de relecture, il semble que le temps de traitement du tampon de relecture et le temps de traitement de l'apprentissage en profondeur puissent être à peu près identiques.) **
Le benchmark a été exécuté dans l'environnement avec le Dockerfile suivant.
Dockerfile
FROM python:3.7
RUN apt update \
&& apt install -y --no-install-recommends libopenmpi-dev zlib1g-dev \
&& apt clean \
&& rm -rf /var/lib/apt/lists/* \
&& pip install tf-nightly==2.3.0.dev20200604 dm-reverb-nightly perfplot
# Reverb requires development version TensorFlow
CMD ["bash"]
(Comme il est implémenté sur le CI du référentiel cpprb, cpprb est également installé. Il est presque synonyme de pip install cpprb)
Ensuite, j'ai exécuté le script de référence suivant et dessiné un graphique du temps d'exécution.
benchmark.py
import gc
import itertools
import numpy as np
import perfplot
import tensorflow as tf
# DeepMind/Reverb: https://github.com/deepmind/reverb
import reverb
from cpprb import (ReplayBuffer as RB,
PrioritizedReplayBuffer as PRB)
# Configulation
buffer_size = 2**12
obs_shape = 15
act_shape = 3
alpha = 0.4
beta = 0.4
env_dict = {"obs": {"shape": obs_shape},
"act": {"shape": act_shape},
"next_obs": {"shape": obs_shape},
"rew": {},
"done": {}}
# Initialize Replay Buffer
rb = RB(buffer_size,env_dict)
# Initialize Prioritized Replay Buffer
prb = PRB(buffer_size,env_dict,alpha=alpha)
# Initalize Reverb Server
server = reverb.Server(tables =[
reverb.Table(name='ReplayBuffer',
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1)),
reverb.Table(name='PrioritizedReplayBuffer',
sampler=reverb.selectors.Prioritized(alpha),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1))
])
client = reverb.Client(f"localhost:{server.port}")
tf_client = reverb.TFClient(f"localhost:{server.port}")
# Helper Function
def env(n):
e = {"obs": np.ones((n,obs_shape)),
"act": np.zeros((n,act_shape)),
"next_obs": np.ones((n,obs_shape)),
"rew": np.zeros(n),
"done": np.zeros(n)}
return e
def add_client(_rb,table):
""" Add for Reverb Client
"""
def add(e):
n = e["obs"].shape[0]
with _rb.writer(max_sequence_length=1) as _w:
for i in range(n):
_w.append([e["obs"][i],
e["act"][i],
e["rew"][i],
e["next_obs"][i],
e["done"][i]])
_w.create_item(table,1,1.0)
return add
def add_client_insert(_rb,table):
""" Add for Reverb Client
"""
def add(e):
n = e["obs"].shape[0]
for i in range(n):
_rb.insert([e["obs"][i],
e["act"][i],
e["rew"][i],
e["next_obs"][i],
e["done"][i]],priorities={table: 1.0})
return add
def add_tf_client(_rb,table):
""" Add for Reverb TFClient
"""
def add(e):
n = e["obs"].shape[0]
for i in range(n):
_rb.insert([tf.constant(e["obs"][i]),
tf.constant(e["act"][i]),
tf.constant(e["rew"][i]),
tf.constant(e["next_obs"][i]),
tf.constant(e["done"])],
tf.constant([table]),
tf.constant([1.0],dtype=tf.float64))
return add
def sample_client(_rb,table):
""" Sample from Reverb Client
"""
def sample(n):
return [i for i in _rb.sample(table,num_samples=n)]
return sample
def sample_tf_client(_rb,table):
""" Sample from Reverb TFClient
"""
def sample(n):
return [_rb.sample(table,
[tf.float64,tf.float64,tf.float64,tf.float64,tf.float64])
for _ in range(n)]
return sample
def sample_tf_client_dataset(_rb,table):
""" Sample from Reverb TFClient using dataset
"""
def sample(n):
dataset=_rb.dataset(table,
[tf.float64,tf.float64,tf.float64,tf.float64,tf.float64],
[4,1,1,4,1])
return itertools.islice(dataset,n)
return sample
# ReplayBuffer.add
perfplot.save(filename="ReplayBuffer_add2.png ",
setup = env,
time_unit="ms",
kernels = [add_client_insert(client,"ReplayBuffer"),
add_client(client,"ReplayBuffer"),
add_tf_client(tf_client,"ReplayBuffer"),
lambda e: rb.add(**e)],
labels = ["DeepMind/Reverb: Client.insert",
"DeepMind/Reverb: Client.writer",
"DeepMind/Reverb: TFClient.insert",
"cpprb"],
n_range = [n for n in range(1,102,10)],
xlabel = "Step size added at once",
title = "Replay Buffer Add Speed",
logx = False,
logy = False,
equality_check = None)
# Fill Buffers
for _ in range(buffer_size):
o = np.random.rand(obs_shape) # [0,1)
a = np.random.rand(act_shape)
r = np.random.rand(1)
d = np.random.randint(2) # [0,2) == 0 or 1
client.insert([o,a,r,o,d],priorities={"ReplayBuffer": 1.0})
rb.add(obs=o,act=a,rew=r,next_obs=o,done=d)
# ReplayBuffer.sample
perfplot.save(filename="ReplayBuffer_sample2.png ",
setup = lambda n: n,
time_unit="ms",
kernels = [sample_client(client,"ReplayBuffer"),
sample_tf_client(tf_client,"ReplayBuffer"),
sample_tf_client_dataset(tf_client,"ReplayBuffer"),
rb.sample],
labels = ["DeepMind/Reverb: Client.sample",
"DeepMind/Reverb: TFClient.sample",
"DeepMind/Reverb: TFClient.dataset",
"cpprb"],
n_range = [2**n for n in range(1,8)],
xlabel = "Batch size",
title = "Replay Buffer Sample Speed",
logx = False,
logy = False,
equality_check=None)
# PrioritizedReplayBuffer.add
perfplot.save(filename="PrioritizedReplayBuffer_add2.png ",
time_unit="ms",
setup = env,
kernels = [add_client_insert(client,"PrioritizedReplayBuffer"),
add_client(client,"PrioritizedReplayBuffer"),
add_tf_client(tf_client,"PrioritizedReplayBuffer"),
lambda e: prb.add(**e)],
labels = ["DeepMind/Reverb: Client.insert",
"DeepMind/Reverb: Client.writer",
"DeepMind/Reverb: TFClient.insert",
"cpprb"],
n_range = [n for n in range(1,102,10)],
xlabel = "Step size added at once",
title = "Prioritized Replay Buffer Add Speed",
logx = False,
logy = False,
equality_check=None)
# Fill Buffers
for _ in range(buffer_size):
o = np.random.rand(obs_shape) # [0,1)
a = np.random.rand(act_shape)
r = np.random.rand(1)
d = np.random.randint(2) # [0,2) == 0 or 1
p = np.random.rand(1)
client.insert([o,a,r,o,d],priorities={"PrioritizedReplayBuffer": p})
prb.add(obs=o,act=a,rew=r,next_obs=o,done=d,priority=p)
perfplot.save(filename="PrioritizedReplayBuffer_sample2.png ",
time_unit="ms",
setup = lambda n: n,
kernels = [sample_client(client,"PrioritizedReplayBuffer"),
sample_tf_client(tf_client,"PrioritizedReplayBuffer"),
sample_tf_client_dataset(tf_client,"PrioritizedReplayBuffer"),
lambda n: prb.sample(n,beta=beta)],
labels = ["DeepMind/Reverb: Client.sample",
"DeepMind/Reverb: TFClient.sample",
"DeepMind/Reverb: TFClient.dataset",
"cpprb"],
n_range = [2**n for n in range(1,9)],
xlabel = "Batch size",
title = "Prioritized Replay Buffer Sample Speed",
logx=False,
logy=False,
equality_check=None)
Le résultat est le suivant. (La dernière version peut être obsolète, alors consultez le site du projet cpprb.)
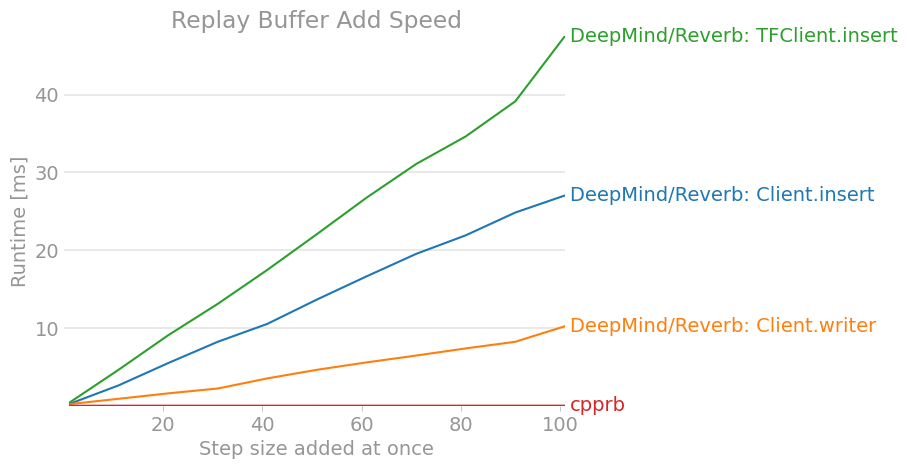
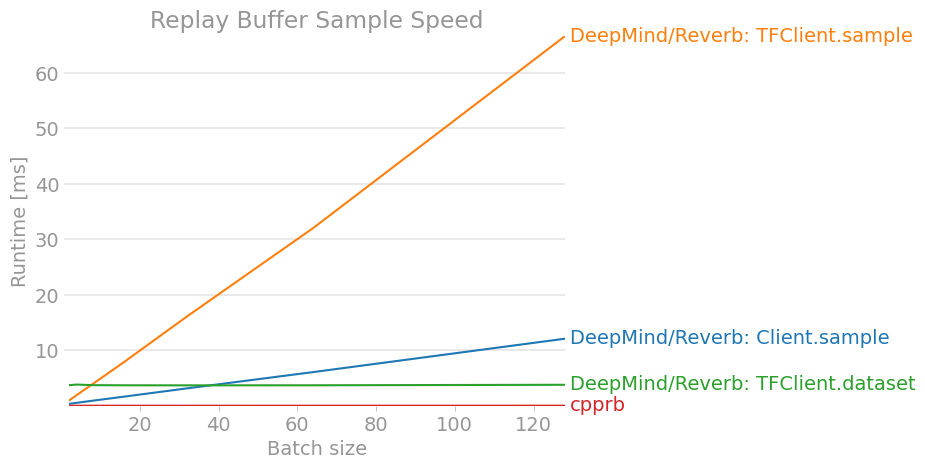
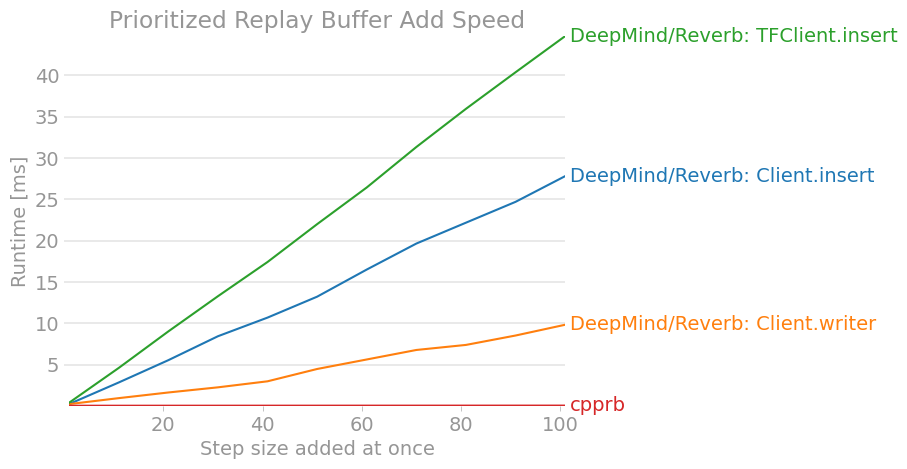
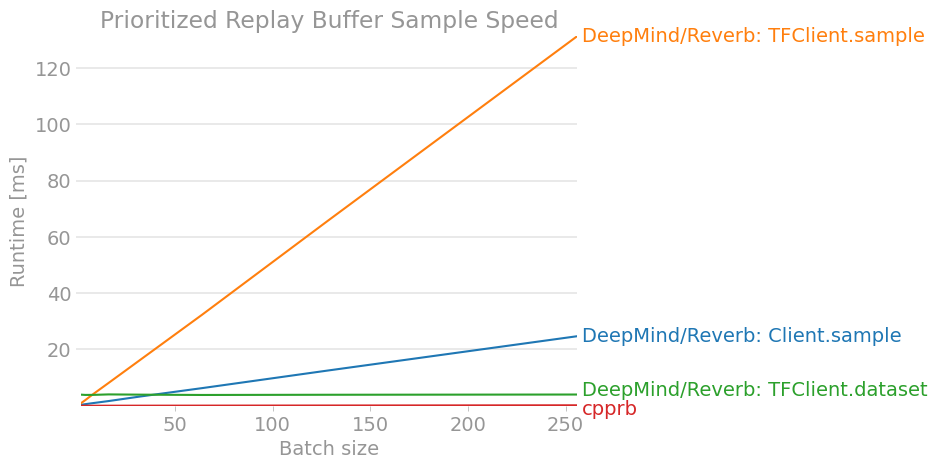
7. Conclusion
Nous avons étudié et organisé comment utiliser le client Reverb du framework DeepMind Experience Replay. Comparé à d'autres implémentations de tampon de relecture telles que OpenAI / Baselines, j'ai trouvé cela difficile à comprendre car il existe de nombreuses différences dans l'API et l'utilisation. (J'espère que ce sera un peu plus facile à comprendre lorsque la version stable sera publiée.)
À tout le moins, cela ne semblerait pas être supérieur en termes de performances à moins que nous n'effectuions un apprentissage distribué à grande échelle et que nous ayons terminé tout l'apprentissage par renforcement dans le graphique de calcul TensorFlow.
Bien sûr, un apprentissage distribué à grande échelle et un apprentissage amélioré dans les graphiques informatiques peuvent considérablement améliorer les performances, je pense donc que nous devons continuer à en tenir compte.
Recommended Posts