Scrapage Web rapide avec Python (tout en prenant en charge le chargement JavaScript)
introduction
Il arrive souvent que vous souhaitiez extraire un élément spécifique d'une page Web et y accéder. (Je veux regarder l'inventaire et le prix d'un certain produit sur un certain site EC toutes les 5 minutes, je veux extraire le texte avec précision pour la classification des documents, etc.) Une telle extraction d'élément est appelée web scraping et Python est également utile dans de tels cas.
Au fait, il y a Crawler / Scraping Advent Calendar 2014 qui est parfait pour cela, et les articles suivants sont bien organisés. (J'ai remarqué son existence il y a quelque temps) http://orangain.hatenablog.com/entry/scraping-in-python
Essayons d'abord
Comme mentionné à la fin de l'article précédent, les requêtes '' et lxml '' sont généralement suffisantes lors du scraping en Python.
pip install requests
pip install lxml
Maintenant, extrayons la partie texte de la page suivante de Tele-Asa News. http://news.tv-asahi.co.jp/news_politics/articles/000041338.html
Voyons d'abord comment la page est organisée. Dans Chrome, il existe des outils de développement en standard comme indiqué ci-dessous (Firebug dans Firefox), et lorsque vous le démarrez, cliquez sur l'icône en forme de loupe et déplacez le curseur de la souris sur la partie que vous souhaitez extraire, et vous pouvez facilement atteindre l'élément cible Vous pouvez voir quel type de structure de page est.
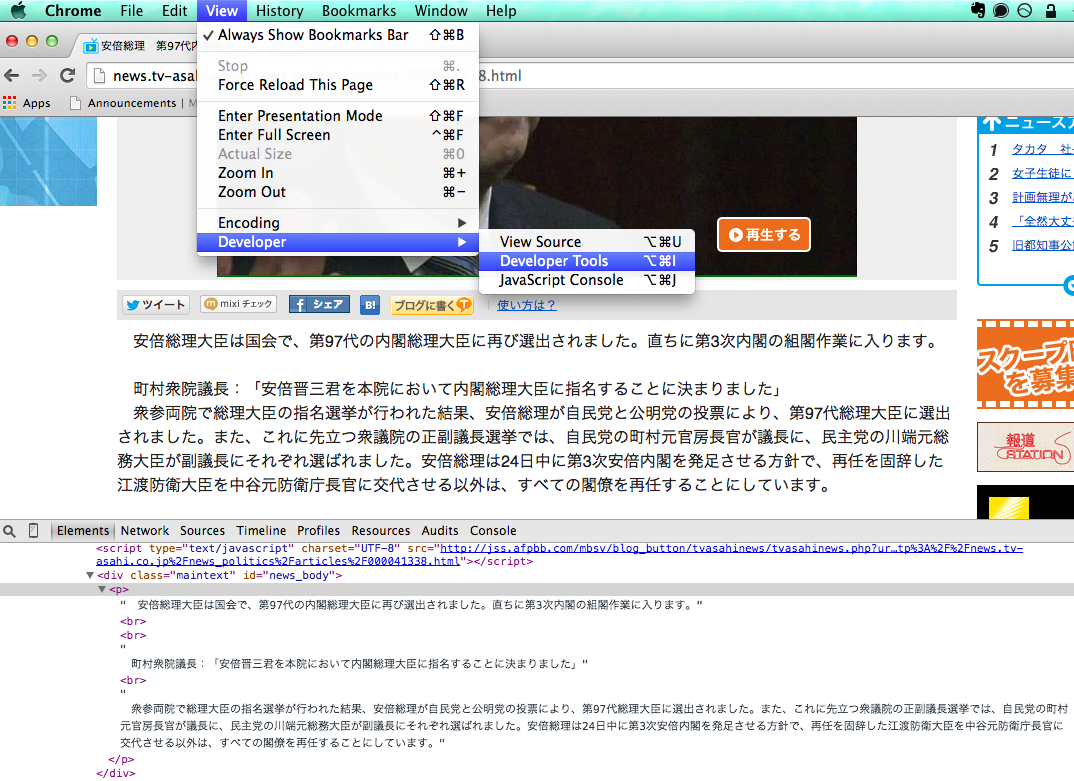
<div class="maintext" id="news_body">Sous l'étiquette<p>Vous pouvez voir que la phrase souhaitée est plus loin sous la balise.
Cet emplacement peut être exprimé par `` # news_body> p``` en utilisant le sélecteur CSS, donc le code de scraping qui extrait finalement cette partie du texte peut être écrit comme:
cf. Récapitulatif des sélecteurs CSS http://weboook.blog22.fc2.com/blog-entry-268.html
import lxml.html
import requests
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
target_html = requests.get(target_url).text
root = lxml.html.fromstring(target_html)
#text_content()La méthode récupère tout le texte sous cette balise
root.cssselect('#news_body > p').text_content()
Si Erreur d'importation: cssselect ne semble pas être installé. Si vous vous mettez en colère, vous pouvez faire `` `` pip install cssselect.
Comme vous pouvez le voir, c'est très simple.
Charger JavaScript
La prochaine partie délicate est la partie qui est rendue en JavaScript. En le regardant avec les outils de développement comme avant, je pense que cela peut être pris de la même manière, mais en fait, c'est le résultat du chargement de JavaScript et du rendu.

Le html avant le chargement de JavaScript est simplement comme ça.
<!--nouvelles liées-->
<div id="relatedNews"></div>
Donc même si vous essayez d'analyser le html obtenu par les requêtes tel quel, cela ne fonctionnera pas. C'est là que le sélénium et le PhantomJS entrent en jeu.
pip installe le sélénium et PhantomJS[dans les environs](http://tips.hecomi.com/entry/20121229/1356785834)Veuillez l'installer en vous référant à.
Ensuite, la version qui charge JavaScript ressemble à ceci.
Si vous obtenez du code HTML via sélénium et PhantomJS, le reste du processus est le même.
```py
import lxml.html
from selenium import webdriver
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
driver = webdriver.PhantomJS()
driver.get(target_url)
root = lxml.html.fromstring(driver.page_source)
links = root.cssselect('#relatedNews a')
for link in links:
print link.text
Résultat d'exécution
Le 3e Cabinet Abe sera lancé prochainement, seul le ministre de la Défense sera remplacé.
Shinzo Abe nommé 97e Premier ministre de la Chambre des représentants
Convocation d'un parlement spécial aujourd'hui: le 3e Cabinet Abe a été établi dans la nuit
À la mise en place du 3e Cabinet Abe, le ministre de la Défense Eto refuse sa reconduction
"Une année fructueuse", le Premier ministre Abe revient sur cette année
Résumé
Comme mentionné ci-dessus, j'ai pu rapidement et facilement gratter non seulement des pages html normales, mais également des pages avec un rendu JavaScript. Lorsque vous grattez en fait divers sites, vous rencontrez souvent des problèmes de code de caractère, mais si vous pouvez faire du scraping Web, vous pouvez automatiser diverses tâches, donc dans diverses situations C'est utile personnellement. Passez une belle vie de Noël et de scraping Web.
Recommended Posts