[GO] [Ruby vs Python] Comparaison de référence entre Rails et Flask
Lors de l'introduction de Flask, un framework Web léger pour Python, nous l'avons comparé à Rails avec accès à la base de données et héritage de modèle. Le résultat est que ** Rails est plus rapide **, ce qui est différent des [Web Framework Benchmarks] externes (https://www.techempower.com/benchmarks/), donc cet article identifie la cause et la résout.
Résultats de référence
Puisqu'il est censé être utilisé par des PJ individuels, j'ai écrit et comparé des benchmarks spécialisés pour chaque application. Résultats ** Rails ** s'est avéré ** 1,493 fois plus rapide que ** Flask ** **. Rails est vraiment rapide.
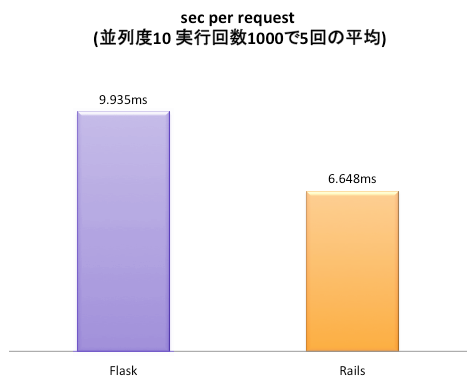
Résultats différents des Benchmarks Web Framework
Le résultat est différent de Web Framework Benchmarks. Flask est lent car il semble y avoir un problème côté code, donc je vais le vérifier.

Conditions du banc
C'est un test de référence spécialisé pour les applications.
- Accès à la base de données pour obtenir 1 enregistrement et afficher le résultat sous forme de modèle
- Assurez-vous d'accéder à la base de données à partir du mappeur O / R
- Les modèles utilisent toujours des fichiers de mise en page (étendus en Python) pour hériter des modèles une fois
- Le benchmark est obtenu avec Apache Bench. Obtenez la vitesse de réponse moyenne 5 fois en accédant 1000 fois avec un degré de parallélisme de 10 --DB est mysql --Invalide car la fonction de session n'est pas utilisée
- Tous les environnements sont construits localement
Commande de démarrage du serveur
#Dans les deux cas, un seul thread a été démarré par la commande de débogage.
# Rails
rails server
# Flask
python manage.py runserver
Version pour chaque programme
| Classification | Langue ver | Framework Web ver |
|---|---|---|
| Flask | Python 3.5.0 | 0.10.1 |
| Rails | ruby 2.0.0p451 | Rails 4.2.5 |
Obtenez une analyse comparative avec Apache Bench
Il s'agit d'une commande de mesure des performances du serveur WEB fournie en standard avec Apache et qui peut être exécutée avec la commande ** ab ** (abréviation d'Apache Bench).
ʻAb.exe -n <Nombre total de demandes d'émission> -c <Nombre de connexions simultanées>
commande ab
#Accédez 1000 fois avec un degré de parallélisme de 10
ab -n 1000 -c 10 http://127.0.0.1:3000/
--Citation: Test de performances Crisp avec Apache Bench
Mon flacon ne peut pas être aussi lent
Dernier article Flask a répondu avec ** 2 ms en moyenne ** sans accès à la base de données et héritage de modèle. L'héritage du modèle doit être mis en cache à un coût nul et l'accès à la base de données ne nécessite pas jusqu'à 7 ms. Cela ne devrait-il pas être de 1 à 2 ms pour l'accès à la base de données, même si vous estimez beaucoup? Il doit y avoir une raison.
Après cela, à la suite du débogage d'impression et de l'enquête, j'ai constaté que le regroupement de connexions DB était désactivé dans SQL Alchemy (O / R Mapper) et je l'ai corrigé.
db.py
#Avant correction
engine = create_engine(db_path, encoding='utf-8')
#modifié
engine = create_engine(db_path, encoding='utf-8', pool_size=5)
#* Sur le banc, j'ai écrit le code pour réutiliser la connexion en creusant dans ThreadLocalStorage.
Résultat de la réacquisition de référence
Après avoir réacquis le benchmark avec le pool de connexions DB de Flask activé, Flask était le plus rapide en termes de vitesse de demande moyenne. Lors de la vérification d'un cadre Web inconnu, il est judicieux de comparer les résultats d'un benchmark externe aux résultats disponibles.
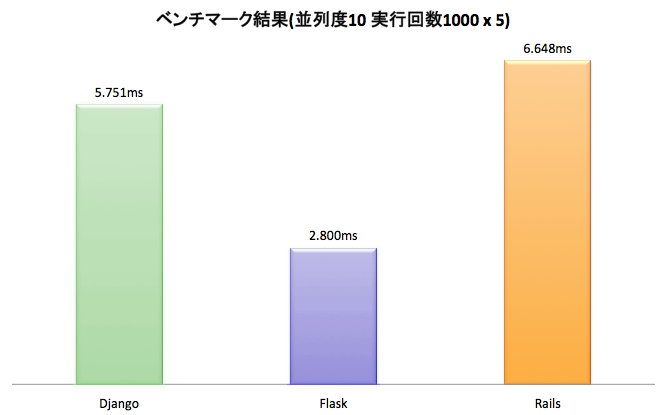

| Classification | Langue ver | Framework Web ver | O/Mappeur R |
|---|---|---|---|
| Django | Python 2.7.5 | Django==1.6.4 | Implémentation originale de Django |
| Flask | Python 3.5.0 | 0.10.1 | SQL Alchemy |
| Rails | ruby 2.0.0p451 | Rails 4.2.5 | Active Record |
Ce que je pense de Flask en tant qu'ingénieur salarié
Pour moi, qui écrit Python au travail, je ne suis pas très attiré par Flask, qui n'est que deux fois plus rapide que Django en termes de vitesse d'exécution. Plus il y a de personnes qui travaillent dans une équipe, moins elles sont susceptibles de ressentir les avantages de jeter les actifs testés existants et de payer ensemble les coûts d'apprentissage. Cependant, dans le PJ personnel, je veux réduire le coût du serveur même de 1 yen et allumer les ongles, donc je vais l'utiliser activement. L'argent est important.
Résumé
--TechEmpower's Web Framework Benchmarks Compétent --Rails est assez rapide --Flask, les utilisateurs de Pyramid doivent vérifier si [SQL Alchemy DB Connection Pool](http://docs.sqlalchemy.org/en/latest/core/ Covoiturage.html) est activé
- Les utilisateurs de Django doivent s'assurer que DB Connection Pool est activé.
- Ce que vous pouvez faire avec Rails peut être fait avec Flask. Et vice versa
Comparaison de Me Me Bench et du Web Framework
J'ai essayé de générer un graphique de comparaison. Je vais enquêter sur le fait que Django ne peut pas être aussi rapide quand j'en ai envie.
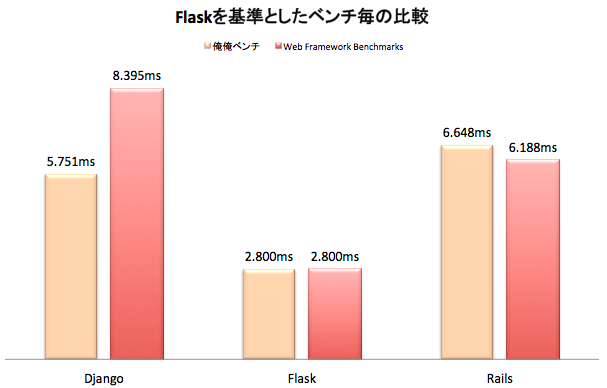
Le monde des frameworks Web au top
** revel ** dans le langage go est ** 2,41 ** fois plus rapide que ** Flask **

Code du banc
C'est assez amusant de faire chaque tutoriel. Générer quoi que ce soit avec la commande Rails rails generate était difficile à comprendre car elle cache ce qui se passe à l'intérieur.
Rails
book_controller.rb
class BookController < ApplicationController
def index
@msg = 'Message d'essai';
# select
book = Book.where("id = 1").all
@book = book[0];
end
end
rb:index.html.erb
<p>
<%= @msg %><br/>
<%= @book.id %><br />
<%= @book.name %><br />
<%= @book.description %><br />
</p>
Flask
index.html
{% extends "master.html" %}
{% block title %}index{% endblock %}
{% block body %}
<h1>this is index page</h1><br />
{{ book.id }}
{{ book.title }}
{{ book.publish }}
{% endblock %}
root.py
# -*- coding: utf-8 -*-
from flask import render_template, Blueprint
#Le nom du premier argument est l'url du modèle_Lié au nom lors de l'appel pour
from utils.db import get_db_session
from module.book import Book
app = Blueprint("index",
__name__,
url_prefix='/<user_url_slug>')
#Url lors de l'appel d'un modèle_for('index.index')
@app.route("/")
def index():
book = get_db_session().query(Book).filter(Book.id=1).all()
return render_template('root/index.html', book=book[0])
django
index.html
{% extends "master.html" %}
{% block content %}
{{ book.id }}
{{ book.name }}
{{ book.description }}
{% endblock %}
views.py
class TestView(TemplateView):
"""
test
"""
template_name = 'index.html'
def get(self, request, *args, **kwargs):
book = Book.objects.filter(id=1).get()
response = self.render_to_response({
'book': book,
})
return response
Premiers rails
J'ai utilisé Rails pour la première fois et le sentiment d'être complètement épuisé était merveilleux. Je n'ai pas trouvé l'écosystème Rails si confortable. En particulier, j'ai été soulagé de constater que les paramètres générés par les deux systèmes de production et de développement étaient bien pensés et avaient une conception morte.
- Pas d'hésitation dans le réglage. Dès le début, les fichiers «production.rb» et «development.rb» appropriés ont été générés.
- Afficher et code de test associé généré avec une seule commande
- Le pipeline d'actifs crée automatiquement à la fois css et js ――Lorsque vous le touchez légèrement, ActiveRecord est maintenant un mappeur O / R ordinaire. ―― La commande Rake est pratique car elle combine des parties difficiles en une seule tâche. ――Beaucoup de documents japonais sortiront si vous faites le tour «Nous avons pu construire à partir de zéro et obtenir une référence en seulement 3 heures lorsque les facteurs ci-dessus se chevauchaient.
- Coût d'apprentissage élevé, ça vaut le coup
Situation de regroupement de connexions de base de données Rails
Il semble que vous puissiez définir la valeur du pool dans config / database.yml. Cependant, s'il est défini sur 0, une erreur se produira et cela ne fonctionnera pas. Il semble que le pool de connexions DB doit être activé dans Rails.
Il y a un problème en raison du fait que le regroupement de connexions ne peut pas être désactivé dans Rails
L'activation du pool de connexions DB accélérera certainement les choses, mais cela a un effet secondaire. Charge du serveur de base de données. Même si vous louez l'instance de base de données la plus élevée d'AWS, si vous établissez 50000 connexions, le processeur restera à 100% et volera avec la charge. Une connexion de base de données est créée pour chaque thread du serveur. En supposant 8 CPU par serveur, il est courant de démarrer un processus enfant HTTP avec 8 à 48 threads, donc même si pool = 1 est défini, il y a 1000 serveurs avec timeout. Et DB volera avec une charge.
La personne de l'entreprise d'exemple l'a résolu
La personne dans l'exemple de site de recettes l'a résolu. Je pense que résoudre la plupart des problèmes après un certain temps est l'un des grands avantages d'un framework Web avec de nombreux utilisateurs et une communauté forte.
Votre prochaine ligne est "Sinatra" ... (・ ㅂ ・) و
Recommended Posts