[PYTHON] Méthode croisée N
Méthode N-cross
Lorsque j'ai appliqué la séparation de source sonore aveugle (BASS) pour la voix par ILRMA, la voix est devenue une séparation supprimée au lieu d'une séparation complète (mettant à zéro la voix de l'orateur qui n'est pas la cible). C'est une méthode conçue pour que même de telles voix puissent être {VAD}. Le nom de la méthode N-cross est un nom que je lui ai donné de manière appropriée, donc je ne pense pas que vous puissiez trouver des références en recherchant.
Aperçu
Il existe une méthode appelée méthode de passage à zéro utilisée pour la détection d'activité vocale (VAD), mais comme elle est faible en résistance au bruit, il s'agit généralement d'une trame basée sur le modèle de mélange gaussien (GMM). La détection de section est effectuée sur la base de l'identification vocale / non vocale de l'unité. Cependant, avec la source sonore séparée par ILRMA cette fois, bien qu'il soit possible de supprimer le niveau de pression acoustique pour les sons non intentionnels, il ne peut pas être complètement réduit à zéro, de sorte que même la partie du son qui n'est pas nécessaire par la méthode GMM est traitée comme une section vocale. Je vais finir. Par conséquent, nous avons implémenté une méthode qui peut détecter la voix cible même s'il y a une voix en arrière-plan. Cette méthode sera appelée cette fois «méthode N-cross». Cette méthode peut être utilisée non seulement de cette manière, mais également dans des situations où l'audio externe est susceptible d'être mélangé, comme dans les négociations commerciales dans un café, ou lorsque la musique de fond est incluse dans la source sonore. 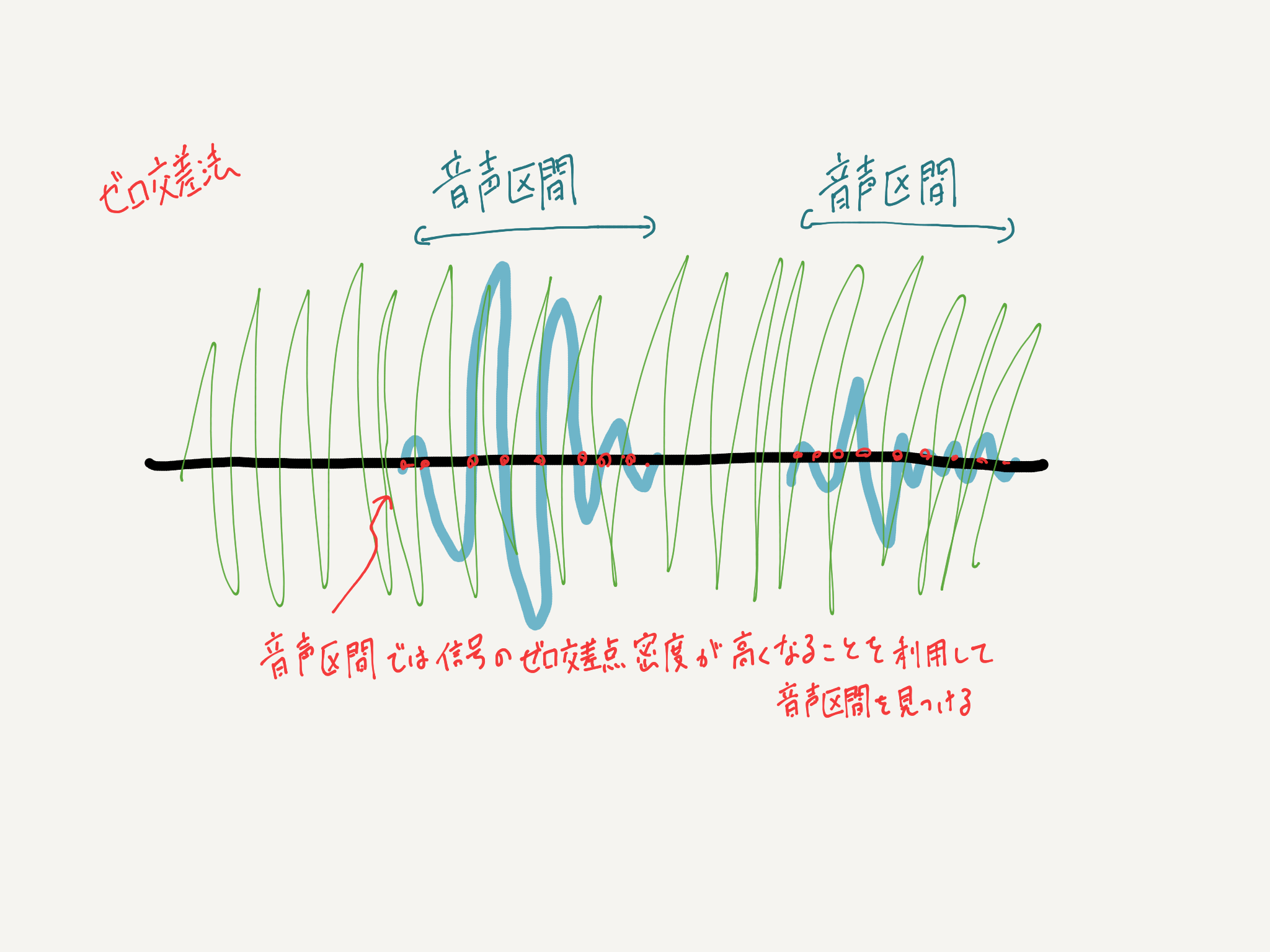
théorie
La théorie est simple. Dans la méthode d'intersection zéro, la section où la fréquence d'intersection sur la ligne Y = 0 est élevée par rapport à la forme d'onde de la voix est détectée comme section vocale, mais avec cette méthode, même une petite voix est détectée, donc N- La méthode cross utilise une intersection avec une valeur arbitraire de Y = N. Nous appellerons cette valeur N * N-cross Line * ou * Sensitivity *. 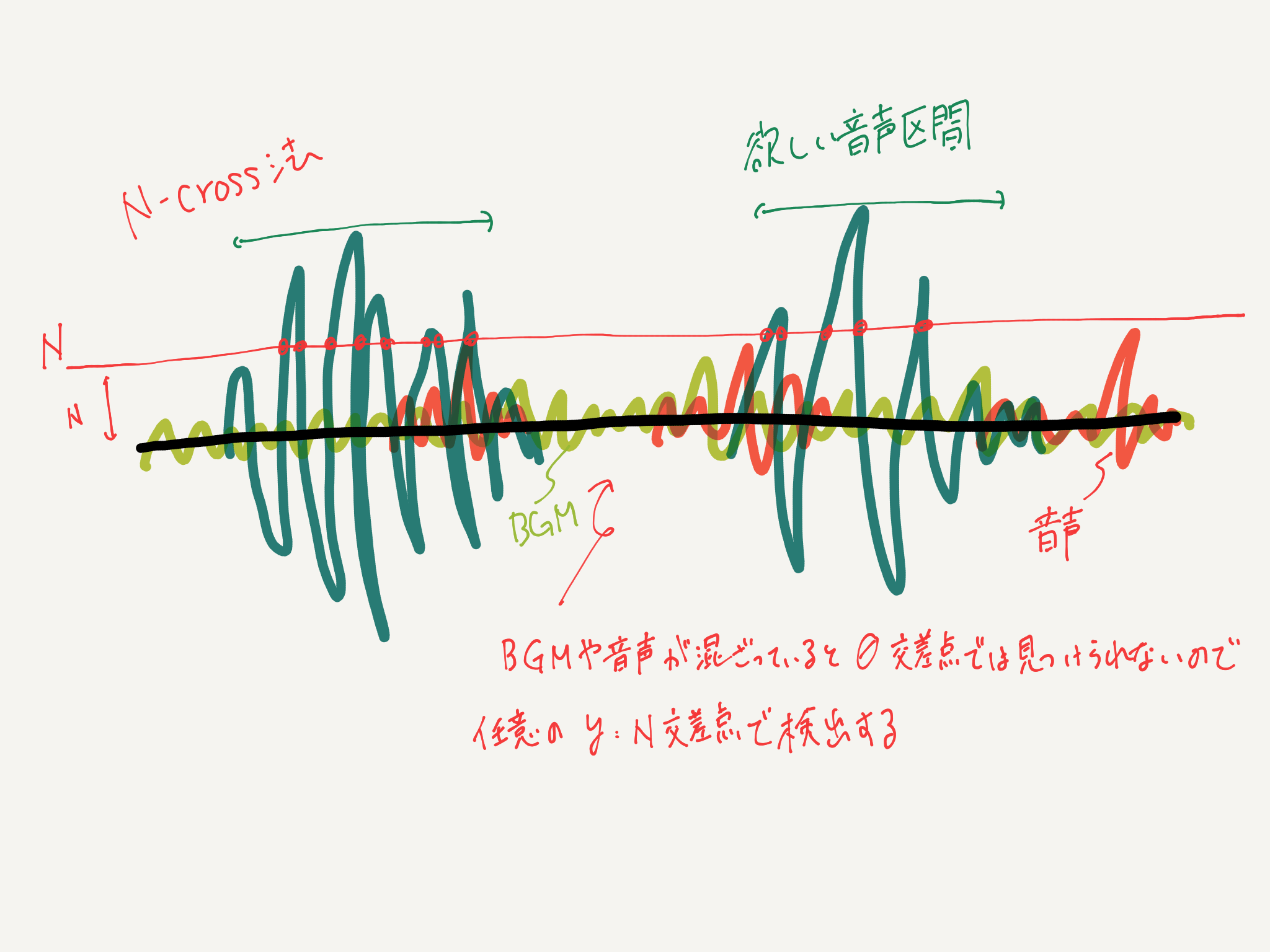
la mise en oeuvre
Implémenté en Python. Veuillez l'exécuter avec Colab ou Jupyter.
Dans le Ncross () '' suivant, si vous entrez une source sonore monophonique data```, il sera inférieur ou égal à N (= 0 à 1) lorsque la pression acoustique maximale de la source sonore est de 1. Si la pression sonore de n'est pas considérée comme une cible VAD et que les données vocales sont divisées en `` hop_length '' et détectées comme section de parole cible, elle est définie sur "1", sinon elle est définie sur "0". Renvoie une liste chronologique. De plus, la valeur de la zone qui considère la section cible comme une section vocale est donnée par le paramètre `` m. Plus il est petit, plus il devient sévère, et plus il est gros, plus il capte de bruit.
Et dans le kukan () '' écrit ci-dessous, commencez à parler à partir de la voix réelle en utilisant la liste de l'axe des temps N_cross_list obtenue par` `` Ncross () `` ``. Renvoie une liste qui stocke l'index temporel et l'index temporel de la fin de l'histoire. Concernant les paramètres, dans `` `N_cross_list, l'intervalle de parole est donné par" 1 "et l'intervalle de silence est donné par" 0 ", donc si cette valeur est donnée par`num```, n'importe quel intervalle Vous pouvez obtenir l'index temporel de. Vient ensuite M '', mais dans la conversation, je pense que vous pouvez prendre une "respiration" même en parlant. C'est une valeur qui détermine combien de secondes de silence sont considérées comme une conversation continue dans le discours avec ce silence entre les deux. Puisque M = 200 '' est réglé cette fois, la fréquence d'échantillonnage est de 44000 dans le temps réel, donc M * hop_length / SampleRate = 2,32 ... , ce qui est d'environ 2 secondes. S'il y a un certain silence, il est considéré comme une coupure dans la section du discours. De plus, bien que non inclus dans les paramètres d'entrée, chousei '' est un paramètre qui donne une marge à l'intervalle de parole détecté. Ici, chousei = 30``` est défini, donc chousei * hop_length / SampleRate = 0.348 ... '' `` secondes est considérée comme la section vocale. La raison pour laquelle je fais cela est que le son de friction et le son éclaté au début de la conversation ne sont souvent pas détectés comme une voix, alors je le donne.
Ncross.py
#N-Méthode croisée
#0 dans la section silencieuse,Renvoie une liste chronologique de 1 dans l'intervalle voisé
def Ncross(data,N,m,hop_length):
"""
N-Méthode croisée
1 dans la section silencieuse,Renvoie une liste de chronologie de 0 dans l'intervalle exprimé
'''
data : Sound
N :Valeur de la zone(0~1)
m :Seuil dans la méthode du passage par zéro
hop_length :Nombre de coupes dans le cadre
"""
y=data/np.max(np.abs(data))
#Nombre de coupes dans le cadre
nms = ((y.shape[0])//hop_length)+1
#Zéro rembourrage pour que le début et la fin puissent être découpés avec un cadre
y_bf = np.zeros(hop_length*2)
y_af = np.zeros(hop_length*2)
y_concat = np.concatenate([y_bf, y, y_af])
zero_cross_list = []
for j in range(nms):
zero_cross = 0
#Découpé par cadre
y_this = y_concat[j*512:j*512+2048]
for i in range(y_this.shape[0]-1):
#Condition en cas de changements positifs ou négatifs
if (np.sign(y_this[i]-N) - np.sign(y_this[i+1]-N))!=0:
zero_cross += 1
zero_cross_list.append(zero_cross)
#Normalisé à un maximum de 1
zero_cross_list = np.array(zero_cross_list)/max(zero_cross_list)
#Le seuil est 0.Réglé sur 4 (Hulistique, mais ...)
zero_cross_list = (zero_cross_list<m)*1
return zero_cross_list
hop_length = 2**9
cross_list = []
for i in range(N_person):
N_cross_list= Ncross(sep[:, -(i+1)],0.3,0.2,hop_length)
cross_list.append(N_cross_list)
N_cross_list1 = cross_list[0]
N_cross_list2 = cross_list[1]
for i in range(N_person):
plt.plot(sep[:, -(i+1)])
plt.show()
separation.py
num = 2
M = 200
chousei = 30
def kukan(N_cross_list,num,M):
A = N_cross_list
A_index = np.where(A == num)[0]
startlist = [A_index[0]]
endlist = []
for i in range(len(A_index)-1):
dif = A_index[i+1]-A_index[i]
if dif > M:
endlist.append(A_index[i])
startlist.append(A_index[i+1])
endlist.append(A_index[-1])
return startlist,endlist
for i in range(N_person):
startpoint,endpoint = kukan(cross_list[i],num=0,M=M)
print("start point",startpoint)
print("end point",endpoint)
for n in range(len(startpoint)):
target = sep[:, -(i+1)]
audio=target[hop_length*(startpoint[n]-chousei):hop_length*(endpoint[n]+chousei)]
display(Audio(audio, rate=RATE))