Application Python: Traitement des données # 3: Format des données
Protocol Buffers
Que sont les tampons de protocole?
Traitez les données en définissant au préalable un type de message. Le type de message est comme une classe sans méthodes. Cette fois, je vais vous présenter comment définir le type de message en utilisant le langage proto2. Le flux de traitement des données est le suivant.
Définir le type de message avec 1, proto2 2, compilez le fichier dans lequel le type de message est défini 3, écrire des données en Python
Définir le type de message ①
Tout d'abord, définissons le type de message. Cette fois, définissons un type de message pour représenter la structure de la famille. Nous donnerons à chaque personne des informations sur «nom», «âge» et «relation». Voir le code source ci-dessous.
//Point-virgule à la fin de chaque ligne(;)Je vais mettre.
syntax = "proto2";
/*Top syntaxe= "proto2";Est comme un signal pour utiliser proto2.
Actuellement, il existe également proto3, mais cette fois, nous utiliserons proto2.*/
message Person{
/*
Il définit une personne pour représenter les informations de chaque membre de la famille.
message est comme une classe Python.
*/
//Commentaire 1:Une seule ligne
/*
commentaire
Partie 2:Utilisé lorsqu'il y a plusieurs lignes
*/
required string name = 1; //Nom complet
/*
nom de chaîne indique qu'une chaîne sera affectée au nom. Cette paire s'appelle un champ.
De côté= 1;Il est devenu. Celui-ci s'appelle une balise.
Les balises sont utilisées lors de la sortie de données au format binaire
C'est une marque pour distinguer quelles données sont lesquelles.
*/
required int32 age = 2; //âge
/*
Les balises de champ dans le même nid doivent être différentes.
Il est également souhaitable de spécifier un nombre entre 1 et 15 pour économiser de la mémoire.
*/
enum Relationship{
FATHER = 0; //père
MOTHER = 1; //mère
SON = 2; //fils
DAUGHTER = 3; //Fille
GRANDFATHER = 4; //grand-père
GRANDMOTHER = 5; //grand-mère
}
required Relationship relationship = 4; //relation
}
Dans proto2, il est nécessaire d'ajouter requis à l'élément requis (il est aboli dans proto3) Notez s'il vous plaît.
Définir le type de message ②
syntax = "proto2";
message Person{
required string name = 1; //Nom complet
required int32 age = 2; //âge
enum Relationship{
//Définir un nouveau type avec une relation enum
/*Il y a PÈRE et MÈRE dans l'énumération
Le type défini par enum prend l'une de ces valeurs.
Relationship relationship = 4;Défini dans
la relation est
Cela peut être PÈRE, MÈRE, SOMME, FILLE, GRAND-PÈRE ou GRAND-MÈRE.
*/
FATHER = 0; //père
MOTHER = 1; //mère
SON = 2; //fils
DAUGHTER = 3; //Fille
GRANDFATHER = 4; //grand-père
GRANDMOTHER = 5; //grand-mère
}
required Relationship relationship = 4; //relation
/*
Relationship relationship = 4;Bien que ce soit
Veuillez noter que ce 4 est une étiquette et ne fait pas référence à GRAND-PÈRE.
Tous les nombres qui apparaissent dans la définition de Relation sont également des balises.
Notez que les balises à l'intérieur de l'énumération commencent à 0.
*/
}
Relation relationnelle = 4;
Veuillez noter que ce 4 est une étiquette et ne fait pas référence à GRAND-PÈRE. De plus, tous les nombres qui apparaissent dans la définition de Relation sont des balises. Notez que les balises à l'intérieur de l'énumération commencent à 0.
Définir le type de message ③
Enfin, définissez la famille. La répétition doit avoir une image de type liste. Cela signifie qu'il y aura 0 ou plusieurs données de type Personne.
syntax = "proto2";
message Person{
required string name = 1; //Nom complet
required int32 age = 2; //âge
enum Relationship{
FATHER = 0; //père
MOTHER = 1; //mère
SON = 2; //fils
DAUGHTER = 3; //Fille
GRANDFATHER = 4; //grand-père
GRANDMOTHER = 5; //grand-mère
}
required Relationship relationship = 4; //relation
}
message Family{
repeated Person person = 1;
}
Ceci complète la définition de la famille. Pour gérer cela en Python, vous devez le réécrire en Python. Cela se fait avec la commande suivante:
%%bash
protoc --python_out={Chemin vers le répertoire pour enregistrer le fichier compilé(Chemin relatif du fichier à compiler)} {Chemin du fichier à compiler}
Cette fois, la famille est directement sous le répertoire de données.On suppose qu'il existe un fichier appelé proto. Exécutez la commande suivante.
%%bash
protoc --python_out=./ ./4080_data_handling_data/family.proto
Puis famille_pb2.Vous aurez un fichier appelé py. Veuillez faire attention à ne pas modifier ce fichier(Si vous le modifiez et l'enregistrez accidentellement, réexécutez la commande ci-dessus.)。
%% bash est appelé une commande magique pour exécuter des commandes sur Jupyter Notebook. Non requis sauf pour Jupyter Notebook.
(Lors de l'exécution dans l'environnement local de Windows, utilisez protoc.exe --python_out = ./ ./4080_data_handling_data / family.proto.)
Écrire des données en Python
J'écrirai les données en Python.
import sys
sys.path.append('./4080_data_handling_data')
family_pb2 = __import__('family_pb2')
#Instance de données de type de famille
family = family_pb2.Family()
family_name = ["Bob", "Mary", "James", "Lisa", "David", "Maria"]
family_age = [34, 29, 5, 3, 67, 66]
# family_rel = [i for i in range(6)]Peut être
family_rel = [family_pb2.Person.FATHER, family_pb2.Person.MOTHER, family_pb2.Person.SON,
family_pb2.Person.DAUGHTER, family_pb2.Person.GRANDFATHER, family_pb2.Person.GRANDMOTHER]
for i in range(6):
#répété est comme un tableau
#Ajouter un nouvel élément
person = family.person.add()
#Nom de substitution, âge, relation
person.name = family_name[i]
person.age = family_age[i]
person.relationship = family_rel[i]
print(family)
Commencez par déclarer une instance de type Family avec family = family_pb2.Family (). La famille avait une personne répétée. C'est comme une liste Si vous souhaitez ajouter un élément, écrivez quelque chose comme family.person.add (). La substitution à celle définie par enum affecte le nom de l'élément ou la balise de enum
hdf5
hdf5 est le format de données utilisé par keras. Par exemple, si vous souhaitez enregistrer le modèle entraîné, il sera généré au format hdf5. Une caractéristique majeure de hdf5 est que la structure hiérarchique peut être complétée dans un seul fichier.
Par exemple, créez un répertoire appelé cooking. Créer des répertoires appelés japonais, occidental et chinois De plus, chaque méthode consiste à réaliser des plats grillés, des plats bouillis, etc.
Créez un répertoire hiérarchique comme une arborescence.
Créer un fichier au format hdf5
Lors de la gestion des données au format hdf5 en Python, une bibliothèque appelée h5py et Pandas est utilisée. Créons réellement les données et sauvegardons-les dans un fichier. Prenons la population de la préfecture A comme exemple.
import h5py
import numpy as np
import os
np.random.seed(0)
#Considérez la ville X, la ville Y et la ville Z dans la préfecture A
#Supposons que X ville a 1 à 3 chome, Y city a 1 à 5 chome et Z city a seulement 1 chome.
#Définition de la population dans chaque ville
population_of_X = np.random.randint(50, high=200, size=3)
population_of_Y = np.random.randint(50, high=200, size=5)
population_of_Z = np.random.randint(50, high=200, size=1)
#Lister la population
population = [population_of_X, population_of_Y, population_of_Z]
#Supprimer le fichier s'il existe déjà
if os.path.isfile('./4080_data_handling_data/population.hdf5'):
os.remove('./4080_data_handling_data/population.hdf5')
#Fichier ouvert
hdf_file = h5py.File('./4080_data_handling_data/population.hdf5')
# 'A'Créez un groupe nommé(Signification de la préfecture A)
prefecture = hdf_file.create_group('A')
for i in range(3):
#Par exemple A/X/1 est une image de 1-chome, ville X, préfecture A
#Image de mise des données dans un fichier nommé 1 dans le répertoire X dans le répertoire A
for j in range(len(population[i])):
city = hdf_file.create_dataset('A/' + ['X', 'Y', 'Z'][i] + '/' + str(j + 1), data=population[i][j])
#l'écriture
hdf_file.flush()
#Fermer
hdf_file.close()
Lecture au format hdf5
Essayez de lire le fichier. L'accès aux éléments est la même image qu'une liste.
import pandas as pd
import h5py
import numpy as np
#Chemin du fichier que vous souhaitez ouvrir
path = './4080_data_handling_data/population.hdf5'
#Fichier ouvert
# 'r'Signifie le mode de lecture
population_data = h5py.File(path, 'r')
for prefecture in population_data.keys():
for city in population_data[prefecture].keys():
for i in population_data[prefecture][city].keys():
print(prefecture + 'Préfecture' + city + 'ville' + i + 'Chome: ',
int(population_data[prefecture][city][i].value))
#Fermer
population_data.close()
TFRecord
À propos de TF Record
TFRecord est le format de données utilisé par TensorFlow. La raison pour laquelle TFRecord est recommandé est de sauvegarder une fois les données dans ce format. En effet, le coût de l'apprentissage automatique peut être inférieur.
De plus, TFRecord est implémenté dans proto3. Ici, nous examinerons le processus de conversion des données au format TFRecord et de leur sortie dans un fichier.
Convertissez l'image au format TFRecord et exportez-la dans un fichier externe ①
Je vais vous montrer comment charger une image et la convertir au format TFRecord. Ici, nous allons gérer la préparation avant d'écrire dans le fichier.
import numpy as np
import tensorflow as tf
from PIL import Image
#Charger l'image
image = Image.open('./4080_data_handling_data/hdf5_explain.png')
#Définition des données à exporter
# tf.train.Utilisez une classe appelée Exemple
# tf.train.De la classe appelée Fonctionnalités"Cohésif"
#Chaque tf.train.L'élément de fonctionnalité est des octets
#Cette image de temps, label, height,Adoptez la largeur comme données
my_Example = tf.train.Example(features=tf.train.Features(feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()])),
'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([1000]).tobytes()])),
'height': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.height]).tobytes()])),
'width': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.width]).tobytes()])),
}))
C'est un peu compliqué, mais jetons un œil à la définition de my_Example.
tf.train.BytesList Ceci est une classe. En définissant value = [hoge], une instance avec hoge comme données est créée. Notez que hoge est octets. Cette fois, la hoge est
- image.tobytes()
- np.ndarray([1000]).tobytes()
- np.ndarray([image.height]).tobytes()
- np.ndarray([image.width]).tobytes()
Ils sont quatre.
Créer une instance de la classe tf.train.Feature
Attribuez une clé à chaque instance de tf.train. Créez une instance de dict. La clé cette fois est
- image
- label
- height
- width
Ils sont quatre. Utilisation du dict généré à partir de ces quatre tf.train. Créez une instance de tf.train.Features.
Créez une instance de tf.train.Example
Généré à partir d'une instance de la classe tf.train.Feature
Cette instance est my_Example, qui est utilisée pour écrire dans le fichier.
Vous pouvez utiliser trois types de formats d'écriture: int64, float et bytes. Cette fois, les octets sont utilisés selon le code source.
L'explication des quatre tf.train. l'image est l'image elle-même label est une marque de l'image et est un nombre arbitraire (1000 cette fois) la hauteur et la largeur sont respectivement la hauteur et la largeur de l'image.
Ici, nous allons incorporer les éléments que nous essayons de trouver. Par exemple, dans ce cas, il n'y a qu'une seule image, donc il n'y a pas beaucoup besoin d'une étiquette. Cependant, cela peut devenir nécessaire à mesure que le nombre d'images augmente. Il peut être préférable d'inclure d'autres informations telles que le nom de l'image. Si l'image suffit, l'image seule convient.

Convertissez l'image au format TFRecord et exportez-la dans un fichier externe ②
Ensuite, écrivez l'instance générée de la classe tf.train.Example dans le fichier
import numpy as np
import tensorflow as tf
from PIL import Image
#Charger l'image
image = Image.open('./4080_data_handling_data/hdf5_explain.png')
#Définition des données à exporter
# tf.train.Utilisez une classe appelée Exemple
# tf.train.De la classe appelée Fonctionnalités"Cohésif"
#Chaque tf.train.L'élément de fonctionnalité est des octets
#Cette image de temps, label, height,Adoptez la largeur comme données
my_Example = tf.train.Example(features=tf.train.Features(feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()])),
'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([1000]).tobytes()])),
'height': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.height]).tobytes()])),
'width': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.width]).tobytes()])),
}))
#Créer un objet TFRecordWriter pour exporter un fichier au format TFRecoder
fp = tf.python_io.TFRecordWriter('./4080_data_handling_data/sample.tfrecord')
#Exemple d'objet sérialisé et écrit
fp.write(my_Example.SerializePartialToString())
#Fermer
fp.close()
fp = tf.python_io.TFRecordWriter ('./4080_data_handling_data/sample.tfrecord') Considérez-le comme un TFRecord ouvert ('. / 4080_data_handling_data / sample.tfrecord', 'w').
fp.write() #Cela va réellement écrire dans le fichier.
SerializePartialToString() #Vous devez maintenant le convertir en une chaîne d'octets et le passer en argument.
fp.close() #Cela ferme le fichier et vous avez terminé.
Gérer les données de longueur variable
Ensuite, je présenterai comment gérer les données de longueur variable. Une longueur variable est une liste dont la longueur peut être modifiée littéralement.
La liste Python est essentiellement de longueur variable Certains ne peuvent contenir qu'une quantité prédéterminée de données, et on les appelle des longueurs fixes.
①tf.train.L'exemple est une longueur fixe.
②tf.train.Utilisez une classe appelée SequenceExample pour générer des données de longueur variable.
```
```python
import numpy as np
import tensorflow as tf
from PIL import Image
#Génération d'instance
my_Example = tf.train.SequenceExample()
#Chaîne de données
greeting = ["Hello", ", ", "World", "!!"]
fruits = ["apple", "banana", "grape"]
for item in {"greeting": greeting, "fruits": fruits}.items():
for word in item[1]:
# my_Fonctionnalité dans l'exemple_de listes, fonctionnalité_Comme clé de liste"word"Ajouter un élément avec
words_list = my_Example.feature_lists.feature_list[item[0]].feature.add()
# word_octets dans la liste_Référence à la valeur dans la liste
new_word = words_list.bytes_list.value
# utf-Encodez en 8 et ajoutez des éléments
new_word.append(word.encode('utf-8'))
print(my_Example)
```
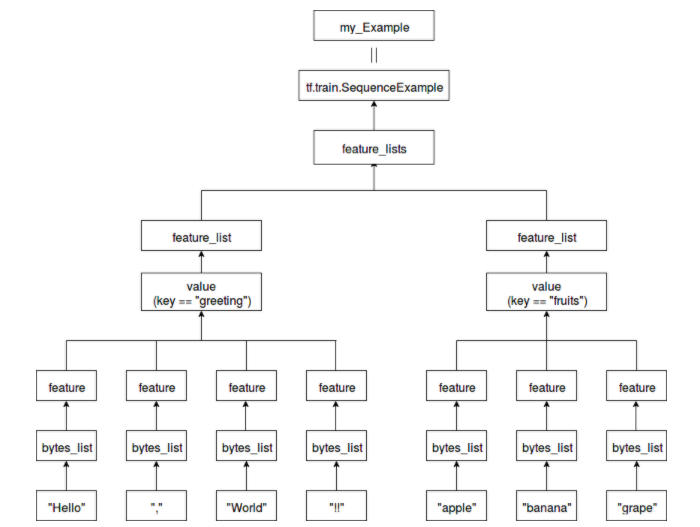
"Hello", "!!" et "apple" font partie de bytes_list.
Vous pouvez également ajouter plusieurs éléments à bytes_list.
Pour la fonctionnalité, spécifiez l'une des options bytes_list, float_list ou int64_list.
Cette fois, bytes_list est spécifié.
Une collection de fonctionnalités est feature_list.
feature_lists a une chaîne comme clé et feature_list comme valeur.
"Salutation" comme clé pour "Hello, World !!"
"Fruits" est spécifié comme clé pour "pomme, banane, raisin".
Une classe avec des listes de fonctionnalités qui les résume est tf.train.SequenceExample
my_Example est cette instance.
Recommended Posts