[PYTHON] Analysons les données de l'enquête par questionnaire [4e: Analyse des émotions]
Cette fois, je voudrais contester l'analyse des émotions en utilisant les données de réponse du questionnaire. En effectuant une analyse émotionnelle, il est possible de juger si l'attitude du répondant est positive ou négative à partir des mots de la réponse libre.
Cette fois également, nous utiliserons les données de réponse gratuite sur «Pourquoi voulez-vous utiliser la version électronique du cahier de médecine» à partir de l'URL suivante.
Nous avons mené une «enquête de sensibilisation sur le cahier de médecine électronique» https://www.nicho.co.jp/corporate/newsrelease/11633/
① Tout d'abord, importez la bibliothèque. Cette fois, j'utiliserai janome.
import csv
from janome.tokenizer import Tokenizer
② Ensuite, téléchargez et lisez le "Dictionnaire japonais de polarité d'évaluation". Il s'agit d'un dictionnaire de mots utilisé pour juger des mots, par exemple, «honnêteté» est positive, «baissière» est négative et environ 8 500 expressions sont associées à des expressions positives ou négatives (ci-dessous). Référence URL).
http://www.cl.ecei.tohoku.ac.jp/index.php?Open%20Resources%2FJapanese%20Sentiment%20Polarity%20Dictionary
! curl http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/pn.csv.m3.120408.trim > pn.csv
np_dic = {}
fp = open("pn.csv", "rt", encoding="utf-8")
reader = csv.reader(fp, delimiter='\t')
for i, row in enumerate(reader):
name = row[0]
result = row[1]
np_dic[name] = result
if i % 500 == 0: print(i)
(3) Effectuer une analyse morphologique sur les données cibles et comparer chaque mot avec le dictionnaire ci-dessus. Dans le code ci-dessous, "p" est positif, "n" est négatif et "e" est une phrase neutre qui n'est ni l'un ni l'autre, et chacun est compté pour déterminer le degré positif ou négatif.
df = open("survey3.txt", "rt", encoding="utf-8")
text = df.read()
tok = Tokenizer()
res = {"p":0, "n":0, "e":0}
for t in tok.tokenize(text):
bf = t.base_form
if bf in np_dic:
r = np_dic[bf]
if r in res:
res[r] += 1
print(res)
cnt = res["p"] + res["n"] + res["e"]
print("Positive", res["p"] / cnt)
print("Negative", res["n"] / cnt)
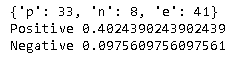
Le résultat est le suivant. La réponse était simplement "pourquoi vous voulez utiliser la version électronique du cahier de médecine", et le résultat est toujours très positif.
D'ailleurs, cette enquête examine également «pourquoi vous ne voulez pas utiliser la version électronique du cahier de médecine». Et si nous faisions une analyse similaire avec ces données?
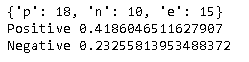
Le résultat ressemble à ceci. Malgré la "raison pour laquelle je ne veux pas l'utiliser", le niveau positif dépasse le niveau négatif. En regardant les données de réponse d'origine, il y avait des réponses telles que «Le cahier papier est meilleur», et il semble que le résultat ci-dessus a été obtenu. Ce domaine est également lié à la conception du questionnaire, et il semble que vous deviez faire attention si vous supposez la mise en œuvre de l'exploration de texte.
Site de référence
Évaluons les romans en ligne tout ce que vous pouvez lire avec un jugement négatif / positif https://news.mynavi.jp/article/zeropython-58/
Recommended Posts